【MySQL数据库基本操作06--函数】
MySQL的函数
1. 聚合函数
count\sum\min\max\avg
重点:group_concat()
-- 将所有员工的名字合并成一行
select group_concat(emp_name) from emp;
-- 指定分隔符合并
select group_concat(emp_name separator ';') from emp;
-- 指定排序方式和分隔符
select department,group_concat(emp_name separator ';') from emp group by department;
select department,group_concat(emp_name order by salary separator ';') from emp group by department;
2. 数学函数
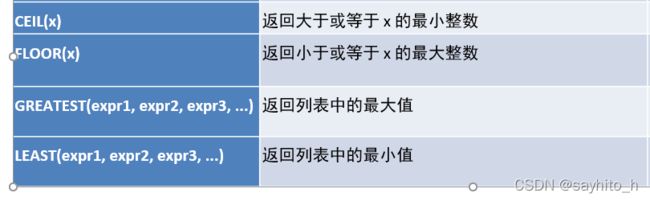
select ceil(1.1);--2
select floor(1.1); --1
select greatest(1,2,3);--3 # max返回字段的最大值,greatest返回列表的最大值
select least(1,2,3); --1
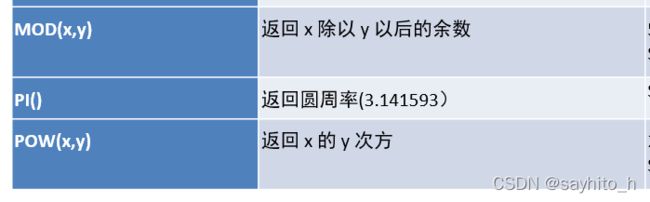
select mod(5/2); --1
select pow(3,2); --9
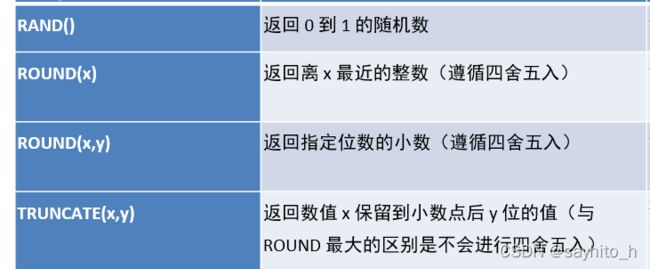
select floor(rand() * 100);
select round(3.568); --4
select round(3.568,2); --3.57
select truncate(3.568,2); --3.56
3. 字符串函数
#1 获取字符串字符个数
select char_length('hello');-- 5 length返回字节数
#2 concat字符串合并
select concat('hello','world'); -- helloworld
#3 指定分隔符进行合并
select concat_ws('-','hello','world'); -- hello-world
#4 返回第一个字符串 s 在字符串列表(s1,s2...)中第一次出现的位置
select field('a','a','b','c'); -- 1
#5 去除左边\右边\两端空格
select ltrim(' abc'),rtrim('abc '),trim(' abc ');
#6 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len)
select mid('helloworld',2,3); # ell
# 从字符串 s 中获取 s1 的开始位置,POSITION(s1 IN s)
select position('a' in 'nation'); #2
# 替换
select replace('abc','a','x'); # xbc
# 翻转
select reverse('abc'); #'cba'
# 返回字符串后n个字符
select right('hello',2); # lo
# 字符串比较
select strcmp('hello','world'); #-1,w>h
# 字符串截取
select substr('hello',2,3) #'ell'
# upper/lower 转换大小写
select upper('hello'); 'HELLO'
4. 日期函数
select unix_timestamp();
select unix_timestamp(2021-12-25 16:32:06);
# 将毫秒值时间戳转为指定格式日期
SELECT FROM_UNIXTIME(1598079966,'%Y-%m-%d %H:%i:%s');
# 获取当前年月日
select curdate();
# 获取当年时分秒
select curtime();
# 获取当前日期和时间
SELECT CURRENT_TIMESTAMP();
# 从日期或日期时间表达式中提取日期值
SELECT DATE(current_timestamp());
# 计算日期 d1->d2 之间相隔的天数
SELECT DATEDIFF('2001-01-01','2001-02-02')
# 计算时间差值(秒级)
SELECT TIMEDIFF("13:10:11", "13:10:10");
# 日期格式化
select date_format('2021-1-1 1:1:1','%Y-%m-%d %H:%i:%s');
# 字符串转为日期
select str_to_date('2017-10-10','%Y-%m-%d');
# 将日期进行减法(date_sub)、加法(date_add);type值也可以多种
select date_sub('2021-10-01',interval 2 day);
# 从日期中获取小时
select extract(hour from '2021-12-25 20:01:10');
# 返回给给定日期的那一月份的最后一天
select last_day('2021-12-25');
# 获取指定年和天数的日期
select makedate('2021',100);
# 返回第几季节
select quarter('2021-5-20');
5. 控制流函数
5.1 if
# if(expr,v1,v2)
SELECT IF(1 > 0,'正确','错误');
# ifnull 如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。
SELECT IFNULL(null,'Hello Word')
# isnull 判断表达式是否为 NULL
SELECT ISNULL(NULL);
# nullif 比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1
select nullif()
5.2 case when
'''CASE expression
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionN THEN resultN
ELSE result
END'''
select
* ,
case payType
when 1 then '微信支付'
when 2 then '支付宝支付'
when 3 then '银行卡支付'
else '其他支付方式'
end as payTypeStr
from orders;
6. 窗口函数
MySQL 8.0 新增窗口函数,窗口函数又被称为开窗函数

window_function ( expr ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
'''
其中window_function 是窗口函数的名称;expr 是参数,有些函数不需要参数;OVER子句包含三个选项:
分区(PARTITION BY)
PARTITION BY选项用于将数据行拆分成多个分区(组),它的作用类似于GROUP BY分组。如果省略了 PARTITION BY,所有的数据作为一个组进行计算
排序(ORDER BY)
OVER 子句中的ORDER BY选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似
以及窗口大小(frame_clause)。
frame_clause选项用于在当前分区内指定一个计算窗口,也就是一个与当前行相关的数据子集。
'''
6.1 序号函数
序号函数有三个:
ROW_NUMBER()、RANK()、DENSE_RANK(),可以用来实现分组排序,并添加序号。
不加partition by表示全局排序
row_number()|rank()|dense_rank() over (
partition by ...
order by ...
)
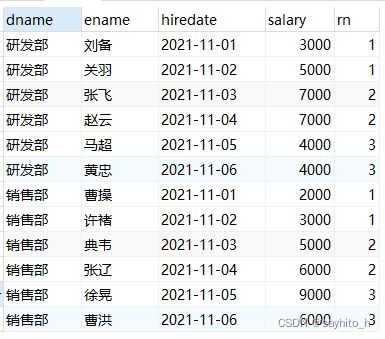
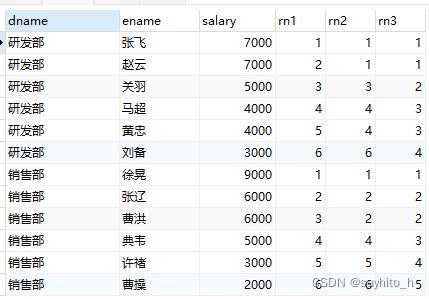
SELECT
dname,
ename,
salary,
ROW_NUMBER() over ( PARTITION BY dname ORDER BY salary DESC ) AS rn1,
rank() over ( PARTITION BY dname ORDER BY salary DESC ) AS rn2,
dense_rank() over ( PARTITION BY dname ORDER BY salary DESC ) AS rn3
FROM
employee;
6.2 开窗聚合函数
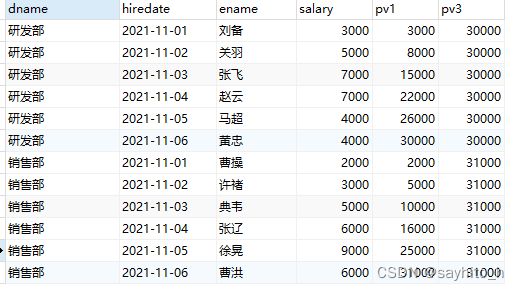
select
dname,hiredate,
ename,
salary,
sum(salary) over(partition by dname order by hiredate rows between unbounded preceding and current row),
sum(salary) over(partition by dname) as pv3
from employee; -- 如果没有order by排序语句 默认把分组内的所有数据进行sum操作
6.3 分布函数
CUME_DIST:
• 用途:分组内小于、等于当前rank值的行数 / 分组内总行数
• 应用场景:查询小于等于当前薪资(salary)的比例
SELECT
dname,
ename,
salary,
round( cume_dist() over ( ORDER BY salary ), 2 ) AS rn1,-- 没有partition语句 所有的数据位于一组
round( cume_dist() over ( PARTITION BY dname ORDER BY salary ), 2 ) AS rn2
FROM
employee;
PERCENT_RANK:
•用途:每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
•应用场景:不常用
7. 前后函数
•用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值
•应用场景:查询前1名同学的成绩和当前同学成绩的差值
SELECT
dname,
ename,
hiredate,
salary,
lag( hiredate, 1, '2000-01-01' ) over ( PARTITION BY dname ORDER BY hiredate ) AS last_1_time,
lag( hiredate, 2 ) over ( PARTITION BY dname ORDER BY hiredate ) AS last_2_time
FROM
employee;
/*
last_1_time: 指定了往上第1行的值,default为'2000-01-01'
第一行,往上1行为null,因此取默认值 '2000-01-01'
第二行,往上1行值为第一行值,2021-11-01
第三行,往上1行值为第二行值,2021-11-02
last_2_time: 指定了往上第2行的值,为指定默认值
第一行,往上2行为null
第二行,往上2行为null
第四行,往上2行为第二行值,2021-11-01
第七行,往上2行为第五行值,2021-11-02
*/
-- lead的用法
select
dname,
ename,
hiredate,
salary,
lead(hiredate,1,'2000-01-01') over(partition by dname order by hiredate) as last_1_time,
lead(hiredate,2) over(partition by dname order by hiredate) as last_2_time
from employee;
8. 头尾函数
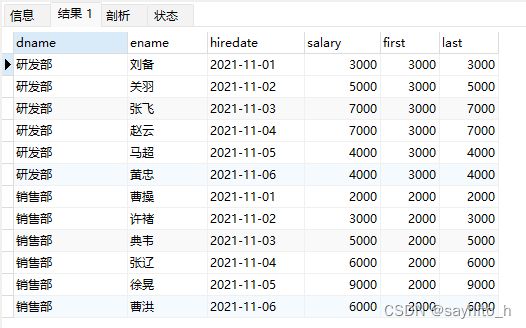
•用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
•应用场景:截止到当前,按照日期排序查询第1个入职和最后1个入职员工的薪资
-- 注意, 如果不指定ORDER BY,则进行排序混乱,会出现错误的结果
select
dname,
ename,
hiredate,
salary,
first_value(salary) over(partition by dname order by hiredate) as first,
last_value(salary) over(partition by dname order by hiredate) as last
from employee;
9. 其他函数
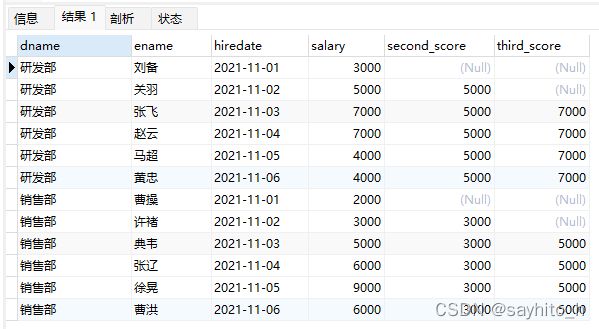
NTH_VALUE(expr,n)
•用途:返回窗口中第n个expr的值。expr可以是表达式,也可以是列名
•应用场景:截止到当前薪资,显示每个员工的薪资中排名第2或者第3的薪资
-- 查询每个部门截止目前薪资排在第二和第三的员工信息
select
dname,
ename,
hiredate,
salary,
nth_value(salary,2) over(partition by dname order by hiredate) as second_score,
nth_value(salary,3) over(partition by dname order by hiredate) as third_score
from employee
NTILE(n)
•用途:将分区中的有序数据分为n个等级,记录等级数
•应用场景:将每个部门员工按照入职日期分成3组
-- 根据入职日期将每个部门的员工分成3组
select
dname,
ename,
hiredate,
salary,
ntile(3) over(partition by dname order by hiredate ) as rn
from employee;