浅读JDK17源码 - StringBuilder
前言
24届软工学硕,本人水平:0 offer,不保证正确,本文内容仅是个人理解。
随缘更新ing…
目录
- 前言
- 1. 基本信息&构造方法
- 2. append()
- 2. 扩容
1. 基本信息&构造方法
StringBuilder sb = new StringBuilder();
首先看一下默认的构造方法:
@IntrinsicCandidate
public StringBuilder() {
super(16);
}
// public final class StringBuilder extends AbstractStringBuilder
默认的构造方法直接调用了父类的构造方法,并传入了默认长度16,StringBuilder类继承了AbstractStringBuilder类,这个抽象类的实现类还有StringBuilder,一个线程安全的StringBuilder

看一下抽象类的属性,包括:
value:存储的值,是一个byte数组coder:编码类型,用静态常量表示@Native static final byte LATIN1 = 0;@Native static final byte UTF16 = 1;
count:字符串的长度EMPTYVALUE:一个默认的空值,在抽象类的无参构造方法中用到。但是这个无参构造方法并没有被调用,源码的注释是:对子类的序列化是必要的。(这里有什么用,作者不是很懂,嘻嘻)
abstract class AbstractStringBuilder implements Appendable, CharSequence {
byte[] value;
byte coder;
int count;
private static final byte[] EMPTYVALUE = new byte[0];
}
再看一下有参的构造,常用的是直接初始化时直接传入字符串。
StringBuilder str= new StringBuilder("SWPU");
同样,调用了父类的有参构造
@IntrinsicCandidate
public StringBuilder(String str) {
super(str);
}
AbstractStringBuilder(String str) {
// 获取长度length
int length = str.length();
// 容量预留 16 的长度,如果超过最大值,就取最大值
int capacity = (length < Integer.MAX_VALUE - 16)
? length + 16 : Integer.MAX_VALUE;
// coder() 获取传入的字符串的编码形式,如果禁用了字符串压缩,就用utf16的编码
final byte initCoder = str.coder();
// StringBuilder的编码随传入的str的编码改变
coder = initCoder;
// 如果编码是UTF16,就new一个2倍大小的byte[]. 因为UTF16的字符占2个字节
value = (initCoder == LATIN1)
? new byte[capacity] : StringUTF16.newBytesFor(capacity);
// 调用append方法初始化
append(str);
}
2. append()
/**
append()
*/
public AbstractStringBuilder append(String str) {
// 如果是空串,会append长度为4的字符串"null"
if (str == null) {
return appendNull();
}
// 获取要添加的字符串的长度
int len = str.length();
// 检查添加字符串后,容量是否合格
ensureCapacityInternal(count + len);
putStringAt(count, str);
count += len;
return this;
}
这里的ensureCapacityInternal()方法是为了干嘛呢?
value属性是一个byte类型的数组,在初始化value时,预留了16个字节大小的空位,value.length其实是远大于count的。count属性是用来记录实际占用的字节大小。
验证一下:
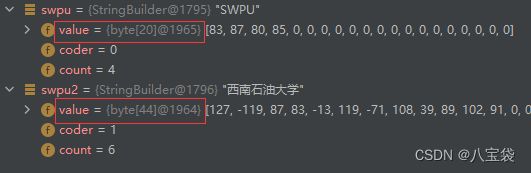
swpu: 编码是LATIN 20 = 4 + 16
swpu2:编码是UTF16 44 = (6 + 16) * 2 = (6+16) << 1
所以每次涉及到容量的操作,都会对根据coder进行一次位运算,因为LATIN = 0,所以位运算不改变大小。(这代码写得确实丝滑)
为了便于理解,就用LATIN编码举例。那么下面这个方法的逻辑就很好理解了。
首先,获取oldCapacity,也就是原容量,给我们预留了16个位置的那个;然后传入的参数minimumCapacity = count + str.length(),就是加上新的字符串需要的容量,如果超出了容量,就扩容,否则无事发生。
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
// LATIN: 0; UTF16:1
// 如果是utf16编码,容量就是长度/2
int oldCapacity = value.length >> coder;
// 判断是否需要扩容
if (minimumCapacity - oldCapacity > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);
}
}
扩容完毕or无需扩容后,执行putStringAt(count, str)
private void putStringAt(int index, String str) {
putStringAt(index, str, 0, str.length());
}
// 传入起始点, 字符串, 偏移量, 结束位置
private void putStringAt(int index, String str, int off, int end) {
if (getCoder() != str.coder()) {
// 如果latin编码遇到了UTF16,就转化原来的为UTF16的2字节存储,UTF16向下兼容嘛
inflate();
}
str.getBytes(value, off, index, coder, end - off);
}
void getBytes(byte[] dst, int srcPos, int dstBegin, byte coder, int length) {
// 正常情况,用了System.arraycopy()实现value的赋值
if (coder() == coder) {
System.arraycopy(value, srcPos << coder, dst, dstBegin << coder, length << coder);
} else { // this.coder == LATIN && coder == UTF16
StringLatin1.inflate(value, srcPos, dst, dstBegin, length);
}
}
可以看到,append()的底层其实就是调用了System.arraycopy(),这个方法其实也是Arrays.copyof()的底层调用

执行完之后,更新一下count属性,也就是当前value存的字符串的真实长度,和value的长度是分开的,至此append()方法结束。
2. 扩容
在append()方法中,其中有一步是检查容量,如果容量不超过预留大小n+16,就无事发生,这里的n是初始化的字符串的长度。那么,如果超过容量了,会发生什么呢?
回到方法ensureCapacityInternal():
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
int oldCapacity = value.length >> coder;
if (minimumCapacity - oldCapacity > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);
}
}
如果说,现在我们加入一个长度为20的字符串,会发生什么?
StringBuilder swpu = new StringBuilder("SWPU");
swpu.append("SWPU_SWPU_SWPU_SWPU!");


答案是:20 —> 42
扩容方法如下:
private int newCapacity(int minCapacity) {
// 20
int oldLength = value.length;
// 4+20 (swpu + ...)
int newLength = minCapacity << coder;
// 4 (超出的部分)
int growth = newLength - oldLength;
//
int length = ArraysSupport.newLength(oldLength, growth, oldLength + (2 << coder));
if (length == Integer.MAX_VALUE) {
throw new OutOfMemoryError("Required length exceeds implementation limit");
}
return length >> coder;
}
值得注意的是下面这行代码
ArraysSupport.newLength(oldLength, growth, oldLength + (2 << coder));
// oldLength: 原容量
// minGrowth: 最小扩容量
// prefGrowth: 期望的扩容量
// 20, 4, 22
public static int newLength(int oldLength, int minGrowth, int prefGrowth){
...
// 20 + MAX(4,22) = 42
int prefLength = oldLength + Math.max(minGrowth, prefGrowth)
...
}
所以,每次扩容时,把原容量*2+2作为新容量,至于为什么需要minGrowth这个变量,我猜是为了防止扩充时容量乘2超过最大值。