DUBBO中的一致性哈希算法
DUBBO中的一致性哈希算法
- 哈希
- 一致性哈希
-
- DUBBO中的一致性哈希算法
哈希
保证哈希算法是同一个,因此同一个用户经过哈希算法后会映射到同一台服务器处理。但存在的问题是:扩容或者缩容时,会导致大量的数据迁移。
问题原因也很好理解,因为扩容或者缩容时,如果哈希算法是单纯对服务器数量进行取模,那么就会导致哈希值改变,映射到不同服务器。
一致性哈希
一致性 hash 算法由麻省理工学院的 Karger 及其合作者于1997年提出的,原理是找比哈希值大的最近的节点。首先把服务器映射到一个[0,2^32-1]的圆环上,每个服务器都有对应的哈希值,当有请求来时,求出请求的哈希值,能够对应环上的一个点,那么选取比这个点更大的服务器。特殊的,如果哈希值更大的第一个服务器挂掉了,则请求下一个结点。在一致性哈希算法中,不论是扩容还是缩容,受影响的区间仅仅是增加或减少服务器的部分哈希环空间。但是一致性哈希也存在一些问题,当结点较少时,可能出现某个服务器承担大部分请求,这种情况叫数据倾斜。

要解决数据倾斜,可以加入虚拟结点,如图根据四台服务器映射出虚拟结点。
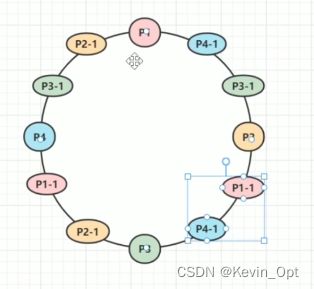
DUBBO中的一致性哈希算法
在DUBBO中,每个服务提供者成为Invoker,并且引入虚拟结点。
TreeMap是红黑树,可以实现哈希环。tailMAP(k),返回大于k的SortedMap,firstKey
首先来看doSlect方法,主要做一些前置工作,检查invokers列表是否扩容或者缩容,如果不存在对应选择器则初始化选择器,接下来调用select方法。
@SuppressWarnings("unchecked")
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String methodName = RpcUtils.getMethodName(invocation);
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
// using the hashcode of list to compute the hash only pay attention to the elements in the list
int invokersHashCode = invokers.hashCode();
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
if (selector == null || selector.identityHashCode != invokersHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, invokersHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
再来看如何初始化ConsistentHashSelector,replecatNumer是虚拟节点数,默认是160个,digest是长度16的字节数组,一个数组进行4次Hash运算,分别对0—3,4—7,8—11,12—15进行位运算。
private static final class ConsistentHashSelector<T> {
private final TreeMap<Long, Invoker<T>> virtualInvokers;
private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = Bytes.getMD5(address + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
最后看看select方法,对参数进行md5计算和hash计算,获得这个哈希值后,选择大于等于这个哈希值的服务器,如果没有,则选择第一个服务器。
public Invoker<T> select(Invocation invocation) {
String key = toKey(invocation.getArguments());
byte[] digest = Bytes.getMD5(key);
return selectForKey(hash(digest, 0));
}
private Invoker<T> selectForKey(long hash) {
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}