TCP拥塞控制详解 | 2. 背景
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach[1]
第2章 背景
要理解互联网拥塞处理方法,有必要先讨论一下互联网架构中的构建假设和设计决策,也就是本章的主要内容,在讨论过程中,我们将提供足够的TCP/IP协议栈的细节来帮助理解后面章节中介绍的拥塞控制机制。对于TCP/IP协议栈的更完整介绍,建议参考以下资源。
延伸阅读:
Computer Networks: A Systems Approach, 2020.
2.1 尽力而为的包传递(Best-Effort Packet Delivery)
互联网支持无连接的(connectionless) 、尽力而为(best-effort) 的包传递服务模型,这种模型由IP定义,并由交换机和路由器实现。无连接(connectionless) 意味着每个IP包携带足够的信息,网络可以根据这些信息将其转发到正确的目的地,没有机制告诉网络当包到达时要做什么。尽力而为(Best-effort) 意味着,如果途中发生什么错误,造成数据包丢失、损坏或传送到错误的目的地,网络无法从故障中恢复,从错误中恢复是运行在终端主机上的更高级别协议的责任。网络被有意设计成这样,从而使路由器可以尽可能简单,这通常被认为与Saltzer、Reed和Clark所阐述的端到端论点(end-to-end argument) 相一致。
延伸阅读:
J. Saltzer, D. Reed, and D. Clark. End-to-End Arguments in System Design. ACM Transactions on Computer Systems, Nov. 1984.
这种设计的结果是,给定数据源可能有足够容量以某种速率向网络发送流量,但在网络中间的某个地方,许多不同流量源可能需要使用同一个链路,因此数据包可能会遇到瓶颈。图3展示了这种情况的一个典型例子,两条高速链路连接到路由器,路由器再将传出的流量输入到低速链路上。虽然路由器能够在一段时间内缓冲数据包,但如果问题持续存在,缓冲队列会增长到一定长度,并最终(因为是有限的)将溢出,导致数据丢失。这种负载超过链路容量的情况正是拥塞的定义。
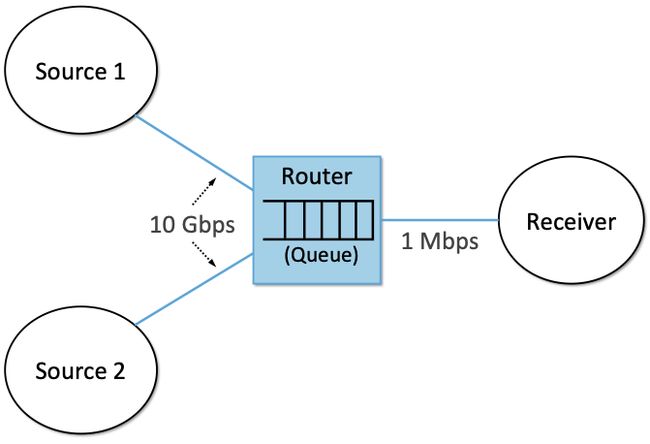 图3. 瓶颈路由器造成的拥塞。
图3. 瓶颈路由器造成的拥塞。
需要注意,避免拥塞不是一个可以完全通过路由解决的问题。虽然路由协议确实可以为拥塞的链路分配很大的"cost",从而使流量避开该链路,但这并不能解决整体问题。要了解这一点,我们只需看看图3描述的简单网络,其中所有流量都必须通过同一个路由器才能到达目的地。虽然这是一个极端的例子,但通常至少有一个链接是不可能绕过的。这条链路以及向该链路发送数据包的路由器可能会拥塞,而路由机制对此无能为力。
2.1.1 流和软状态(Flows and Soft State)
由于互联网采用无连接模型,因此任何面向连接的服务都是由运行在终端主机上的端到端传输协议(如TCP)实现的。网络本身并没有实现连接建立机制(与基于虚拟电路的网络相比),因此路由器没有为活跃连接预分配缓冲区空间或链路带宽的机制。
缺少显式的连接建立机制并不意味着路由器完全不知道端到端连接。IP数据包是独立交换的,但通常情况下,给定的一对主机需要连续交换多个数据包,例如,客户端从服务器下载大视频文件。此外,一对主机之间给定的数据流通常通过一组一致的路由器传输。由此引入了流(在源/目标对之间发送的数据包序列,并遵循相同的网络路由)这一重要的抽象概念,后面章节将多次使用这一概念。
流抽象的强大之处在于,流可以在不同粒度上定义。例如,可以是主机到主机(即具有相同的源/目标IP地址)或进程到进程(即具有相同的源/目标主机/端口对)。图4演示了通过一系列路由器的几个流。
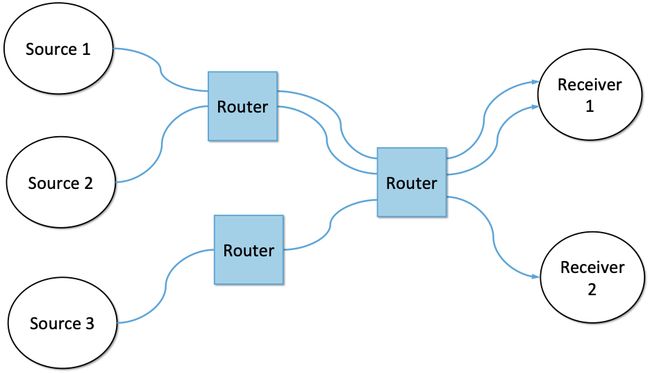 图4. 通过一组路由器的多条流。
图4. 通过一组路由器的多条流。
由于每个路由器都有多条数据流,因此有时需要为每条数据流维护状态信息,这些信息可以用于对该数据流的包进行资源分配决策,这被称为软状态(soft state) ,软状态和硬状态之间的主要区别是,前者不是通过信令明确创建和删除的。软状态代表了在路由器上保持无状态的纯无连接网络和在路由器上保持硬状态的纯面向连接网络之间的中间状态。一般来说,网络的正确运行并不依赖于当前的软状态(每个包仍然能正确路由),但当一个包恰好属于路由器当前保持的软状态的流时,就能被更好的处理。
服务质量(Quality-of-Service)
在尽力而为服务中,所有包都得到了基本平等的处理,终端主机没有机会要求网络给某些包或流提供某些质量保证或优先服务。定义一个支持某种高优先级服务或质量保证的服务模型(例如,保证视频流所需的带宽),将产生支持多种服务质量(QoS)的体系架构。
实际上从纯粹的尽力而为服务模型到每个流都能获得QoS保证的模型之间有一系列的可能性。有一些互联网服务模型的扩展,包括额外的服务水平,但(1)没有在整个互联网上广泛部署,(2)即使部署了,仍然允许尽力而为的流量,这些流量依赖本书介绍的拥塞控制算法运行。
为完整起见,图5给出了IPv4包格式,但与我们的讨论相关的是8位的TOS(Type of Service, 服务类型)字段。多年来,这个字段以不同的方式被解释,但基本功能是允许根据应用程序的需要对数据包进行不同的处理。在后面的章节中,我们将看到各种拥塞控制机制如何随着时间的推移应用TOS字段的不同含义。
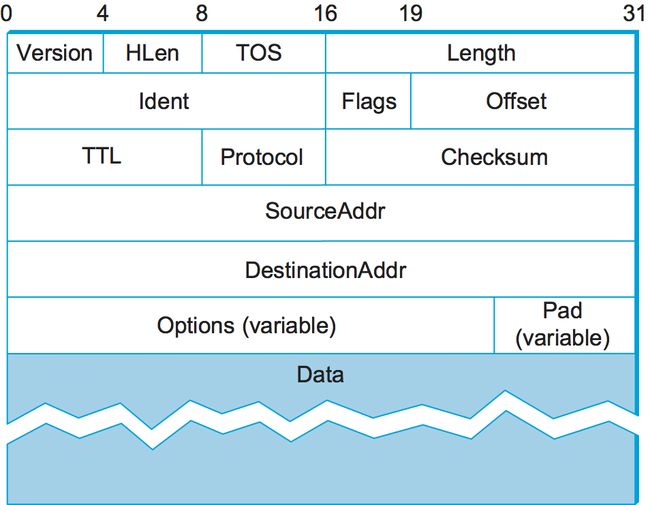 图5. IPv4数据包报头。
图5. IPv4数据包报头。
2.1.3 先入先出队列(FIFO Queuing)
每个路由器都实现了某些队列规则,该规则定义了等待传输时如何缓冲数据包。排队算法可以被认为是同时分配带宽(传输哪些包)和缓冲区空间(丢弃哪些包),还通过决定等待传输的时间长短,直接影响包的时延。
最常见的排队算法是先入先出(First-In/First-Out, FIFO) ,即第一个到达路由器的数据包就是第一个被传输的数据包。图6(a)中显示了一个具有"插槽(slots)"的FIFO队列,最多可以容纳8个包。数据包到达时被添加在尾部,并从头部传输,因此可以保证FIFO的顺序。
假设路由器的缓冲空间是有限的,如果一个数据包到达时,队列(缓冲空间)是满的,那么路由器就会丢弃这个数据包,如图6(b)所示。这一操作与数据包属于哪个流或包有多重要无关。因为到达FIFO尾部的数据包在队列满时被丢弃,因此有时这被称为尾丢弃(tail drop) 。
 图6. FIFO队列(a),FIFO队列的尾丢弃(b)。
图6. FIFO队列(a),FIFO队列的尾丢弃(b)。
请注意,尾丢弃和先入先出是两个独立的机制。FIFO是一种调度规则,决定了数据包传输的顺序。尾丢弃是一种丢弃策略,决定丢弃哪些数据包。由于FIFO和尾丢弃分别是调度规则和丢弃策略的最简单实例,有时被视为一个默认的包队列实现。第6章讨论了比通过判断"是否有空闲缓冲区?"更复杂的丢弃策略,这些丢弃策略可用于FIFO,或其他更复杂的调度规则。
公平队列(Fair Queuing)
公平队列(FQ, Fair Queuing)是FIFO队列的替代方案,通常用于实现QoS保证。FQ的思想是为路由器当前正在处理的每个流(针对某些流粒度)维护一个单独的队列。然后路由器按循环顺序(在FQ的最简单版本中)为这些队列服务。如果路由器由于多个流的流量而拥塞,FQ可以确保没有哪条流可以独占出链路,每条流都可以分得一条链路的份额。这样,某个给定数据源就不能随意以牺牲其他流为代价,增加网络容量所占的份额。
FQ可以与端到端拥塞控制机制结合使用。它只是简单的隔离流量,使行为不良的流量源不会干扰那些忠实实现端到端算法的流量源。FQ还在由良好的拥塞控制算法管理的流集合之间加强了公平性。
2.2 可靠字节流(Reliable Byte-Stream)
TCP在IP支持的尽力而为服务模型基础上实现了可靠的字节流(运行在终端主机上的一对进程之间)。本节对TCP进行了足够详细的介绍,以便理解后续章节介绍的拥塞控制机制。
2.2.1 端到端问题(End-to-End Issues)
TCP的核心是滑动窗口算法,除了熟悉的确认/超时/重传机制之外,还必须解决以下复杂问题。
首先,由于TCP支持在任意两台连接到互联网的计算机上运行的两个进程之间建立逻辑连接,因此需要明确的连接建立机制。在此阶段中,双方同意彼此交换数据。在连接建立期间发生的事情之一是,双方共享某些状态,以开始滑动窗口算法。需要断开连接时,每个主机都知道可以释放此状态。
其次,TCP连接的往返时间可能差别很大。例如,旧金山和波士顿之间相隔数千公里的TCP连接可能有100毫秒的RTT,而同一房间中两台主机之间的TCP连接可能只有1毫秒的RTT,同一TCP协议必须能够支持这两种连接。更糟糕的是,旧金山和波士顿之间的TCP连接可能在凌晨3点的RTT为100毫秒,但在下午3点的RTT为500毫秒,RTT的变化甚至可能发生在仅持续几分钟的单个TCP连接中。这对滑动窗口算法来说,意味着触发重传的超时机制必须是自适应的。
第三,由于互联网的尽力而为性质,数据包在传输过程中可能会被重新排序。由于滑动窗口算法可以通过序列号对数据包进行重排序,因此稍微混乱的数据包不会引起问题。真正的问题是数据包的顺序可能会混乱到什么程度,或者换句话说,数据包到达目的地的时间可能会延迟到什么程度。在最糟糕的情况下,数据包在互联网上几乎可以被任意的延迟。每个IP被路由器转发一次,它的TTL(生存时间, time to live)字段就会递减,并最终达到零,此时数据包就会被丢弃(因此没有延迟到达的危险)。注意,TTL也许会产生误导,在IPv6中被重命名为更精确的跳数(Hop Count)。TCP知道IP网络会在数据包TTL过期后丢弃,因此假定每个数据包都有最大生命周期,称为最大分片寿命(MSL, Maximum Segment Lifetime) ,这是一种工程选择,当前推荐设置为120秒。请记住,IP并不会直接强制执行120秒的值,这只是一个保守估计,TCP决定了一个包在互联网上可能存在的时间,这意味着TCP必须为非常旧的包突然出现在接收端做好准备,这可能会混淆滑动窗口算法。
第四,由于几乎任何类型的计算机都可以连接到互联网,特别是考虑到任何一台主机都可能同时支持数百个TCP连接,因此用于任何给定TCP连接的资源量是高度可变的。这意味着TCP必须提供某种机制,让每一方"了解"对方能够提供多少资源(例如,多少缓冲区空间,这就是流量控制问题。
第五,TCP连接的发送端不知道要通过哪些链接到达目的地。例如,发送端可能直连到一个相对较快的以太网,能够以10 Gbps的速率发送数据,但是网络中间的某个地方必须穿过一条1.5 Mbps的链路。而且,更糟糕的是,由许多不同来源的数据可能试图遍历相同的慢连接。如果汇聚了足够多的流量,即使是高速链路也会出现拥塞。这是导致拥塞的基本因素,我们将在后面的章节中讨论。
2.2.2 分片格式(Segment Format)
TCP是面向字节的协议,意味着发送方向TCP连接写入字节,接收方从TCP连接读取字节。尽管"字节流"描述了TCP提供给应用程序进程的服务,但TCP本身并不通过互联网传输单个字节。相反,源主机上的TCP从发送进程中获取足够的字节来填充一个大小合理的包,然后将此包发送到目标主机上的对等端。然后,目标主机上的TCP将数据包的内容导入接收缓冲区,接收进程在空闲时从缓冲区读取数据。这种情况如图7所示,为了简单起见,图7只显示了数据在一个方向上流动。
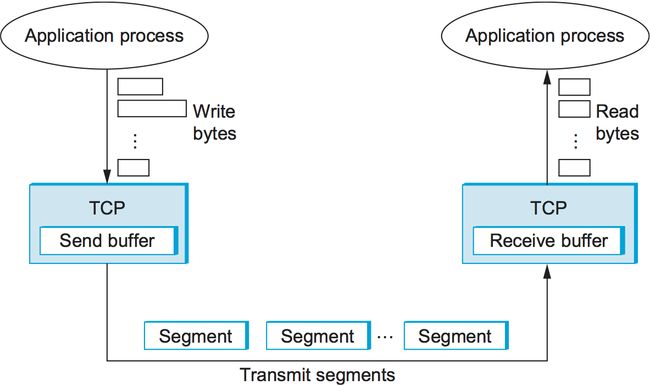 图7. TCP如何管理字节流。
图7. TCP如何管理字节流。
图7中TCP对等体之间交换的数据包称为分片(segments) ,每个包携带一个字节流的分片,每个TCP分片都包含图8示意图显示的报头。下面介绍与我们的讨论相关的字段。
 图8. TCP报头格式。
图8. TCP报头格式。
SrcPort和DstPort字段分别标识源端口和目的端口。这两个字段,加上源IP地址和目的IP地址,组合起来唯一标识了每个TCP连接。所有需要管理TCP连接的状态,包括后面章节介绍的拥塞相关的状态,都被绑定到4元组(SrcPort, SrcIPAddr, DstPort, DstIPAddr)。
TCP的滑动窗口算法涉及到Acknowledgment、SequenceNum和AdvertisedWindow字段。因为TCP是面向字节的协议,每个字节的数据都有一个序列号。SequenceNum字段标识了该分片中携带的数据的第一个字节的序列号,而Acknowledgment和AdvertisedWindow字段携带关于反向数据流的信息。为了简化讨论,我们忽略了数据可以在两个方向上流动的事实,而专注于这样的数据,即特定的SequenceNum在一个方向流动,而Acknowledgment和AdvertisedWindow在相反方向流动,如图9所示。
 图9. TCP处理简化图(只显示一个方向),数据流在一个方向,ack在另一个方向。
图9. TCP处理简化图(只显示一个方向),数据流在一个方向,ack在另一个方向。
6位Flags字段用于在TCP对等体之间传输控制信息,包括SYN和FIN标志,在建立和终止连接时使用,以及ACK标志,该标志在Acknowledgment字段有效时设置(暗示接收方应该注意)。
最后,TCP报头的长度是可变的(选项可以附加在强制字段之后),因此HdrLen字段被包括进来,以32位给出报头的长度。当TCP扩展被附加到报头末尾时(ll例如支持拥塞控制),该字段就有了意义。将这些扩展添加为可选项而不是更改TCP头的核心意义在于,即使主机没有实现这些选项,仍然可以基于TCP进行通信,而实现了可选扩展的主机可以在TCP连接建立阶段使用这些选项。
2.2.3 可靠和有序的传递(Reliable and Ordered Delivery)
TCP滑动窗口算法的变体有两个主要目的:(1)保证可靠、有序的数据传递,(2)强制发送方和接收方之间进行流量控制。为了实现流量控制,接收端选择一个滑动窗口大小,并通过TCP报头中的AdvertisedWindow字段将其通告给发送端。然后,发送方被限制在任何给定时间保留不超过AdvertisedWindow字节的未确认数据。接收端根据分配给连接用于缓冲数据的内存数量为AdvertisedWindow选择合适的值,这样做的目的是防止发送方占用接收方的缓冲区。
要了解TCP滑动窗口是如何工作的,请考虑图10所示情况。TCP在发送端维护发送缓冲区,这个缓冲区用于存储已经发送但尚未确认的数据,以及发送应用程序已经写入但尚未传输的数据。在接收端,TCP维护接收缓冲区,这个缓冲区保存了到达时顺序不正确的数据,以及顺序正确(即中间没有丢失的字节)但应用程序进程还没有机会读取的数据。
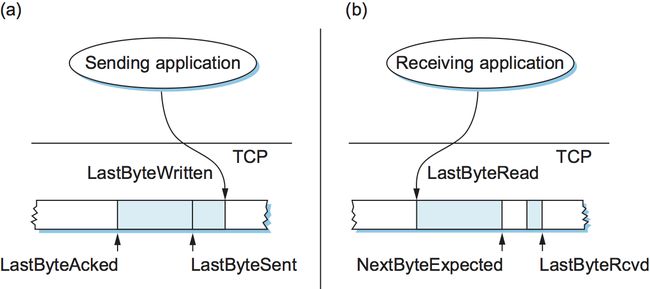 图10. TCP发送缓冲区(a)和接收缓冲区(b)的关系。
图10. TCP发送缓冲区(a)和接收缓冲区(b)的关系。
为了使下面的讨论更简单,我们忽略了缓冲区和序列号都是有限大小的,因此最终会绕回来。同样,我们不区分存储特定字节数据的缓冲区指针和该字节的序列号。
首先来看发送端,发送缓冲区维护三个指针,每个指针都有明显的含义: LastByteAcked, LastByteSent和LastByteWritten。因为接收端不可能确认一个还没有发送的字节,而TCP也不可能发送一个还没有被应用进程写入的字节,因此很明显:
在接收端维护一组类似的指针(序列号): LastByteRead、NextByteExpected和LastByteRcvd。然而,由于无序交付的问题,这些不等式有点不那么直观。由于只有当某个字节被接收并且之前所有字节也被接收后,应用程序才能读取,因此在这种情况下:
如果数据是按顺序到达的,则NextByteExpected指向LastByteRcvd之后的字节,而如果数据是乱序到达的,则NextByteExpected指向数据中第一个缺口的开始,如图10所示。
2.2.4 流量控制(Flow Control)
目前为止的讨论都假设接收端能够与发送端保持同步,但实际情况并非如此,而且发送端和接收端都有一定大小的缓冲区,所以接收端需要一些方法来减慢发送端速度,这就是流量控制的本质。
虽然我们已经指出了流量控制和拥塞控制是不同的问题,但重要的是首先要理解流量控制是如何工作的,因为用于实现流量控制的窗口机制在拥塞控制中也发挥了重要作用。窗口为发送者提供了关于有多少数据正在"传输中"(尚未确认)的明确指示,这对两个问题都至关重要。
下面我们重新考虑两个缓冲区大小都是有限的事实,分别表示为SendBufferSize和RcvBufferSize。接收方通过发布不大于可以缓冲的数据量的窗口来限制发送方。注意接收端TCP必须保证
从而避免缓冲区溢出。因此,接收端公告窗口大小为
表示其缓冲区中剩余可用空间量。当数据到达时,只要前面所有字节也已经到达,接收方就会认可。此外,LastByteRcvd向右移动(递增),这意味着通告窗口可能会缩小,不过是否收缩取决于本地应用程序进程消费数据的速度。如果本地进程读取数据的速度和到达数据的速度一样快(导致LastByteRead以与LastByteRcvd相同的速度递增),那么通告窗口将保持打开状态(即AdvertisedWindow = RcvBufferSize)。但是,如果接收进程落后了(可能因为对读取的每个字节的数据执行非常昂贵的操作),那么通告窗口将随着每一个到达的分片而变小,直到最终变为0。
然后,发送端TCP必须遵循从接收端获得的通告窗口,这意味着在任何给定时间,必须确保
换句话说,发送方需要计算出有效(effective) 窗口来限制可以发送的数据量:
很明显,如果源想要发送更多数据,EffectiveWindow必须大于0。因此,有可能发生这样的情况,收到一个分片包确认了x字节,从而发送方的LastByteAcked增加了x,但因为接收进程没有读取任何数据,现在通过窗口比之前小了x字节。在这种情况下,发送方可以释放缓冲区空间,但无法发送更多数据。
在此过程中,发送端还必须确保本地应用程序进程不会造成发送缓冲区溢出,即,
如果发送进程试图向TCP写入b字节,但是
TCP需要阻塞发送进程,不允许它发送更多的数据。
现在可以理解慢接收进程如何最终阻塞了快发送进程。首先,接收缓冲区被填满,这意味着通告窗口将收缩为0。通告窗口为0意味着发送方不能传输任何数据,即使之前发送的数据已经被成功确认。最后,不能传输任何数据意味着发送缓冲区被填满,这最终会导致TCP阻塞发送进程。一旦接收进程再次开始读取数据,接收端TCP就能够打开窗口,允许发送端TCP传输缓冲区数据。当这些数据最终被确认后,LastByteAcked增加,缓冲区空间变得空闲,发送过程被解除阻塞并允许继续发送。
只剩下一个细节必须解决,发送端如何知道通告窗口不再是0?TCP总是发送一个分片响应接收到的数据,并且这个响应包含了Acknowledge和AdvertisedWindow字段的最新值,即使这些值自上次发送以来没有改变。问题是一旦接收端通告窗口为0,发送端就不允许发送任何数据,这意味着它没有办法发现通告窗口在未来的某个时间不再为0。接收端TCP不会自发发送非数据分片,只会发送作为对到达数据的响应。
对于这种情况,TCP是这样处理的。当另一方通告窗口大小为0时,发送方坚持每隔一段时间发送1字节的数据。它知道这个数据可能不会被接受,但还是会尝试,因为每个1字节的分片都会触发包含当前通告窗口的响应,最终该响应携带了非零值。这些1字节的消息被称为零窗口探测(Zero Window Probes) ,实际上每5到60秒会发送一次。
2.2.5 触发传输(Triggering Transmission)
接下来我们考虑TCP如何决定传输一个分片,这是个令人惊讶的微妙问题。如果我们忽略流控制,并假设窗口是完全打开的,那么TCP有三种机制来触发一个分片的传输:
- TCP维护了一个通常称为 最大分片大小(MSS, maximum segment size) 的变量,一旦从发送进程中收集到
MSS字节,就发送一个分片。 - 发送进程可以通过调用 push操作显式请求TCP发送一个分片,这将导致TCP清空未发送字节缓冲区。
- 计时器触发,产生一个包含当前缓冲字节数的分片。
当然,我们不能忽视流量控制。如果发送方有MSS字节的数据要发送,并且窗口是打开的,那么发送方将发送一个完整的分片。然而,假设发送方正在积累要发送的字节,但窗口当前是关闭的。现在假设ACK到达,打开了足够的窗口让发送方传输,比如MSS/2字节。发送者应该发送一半分片还是等待窗口打开到完整的MSS?
规范一开始没有定义,TCP的早期实现决定传输一半分片。但事实证明,积极利用任何可用窗口的策略导致了一种现在被称为愚蠢窗口综合征(silly window syndrome) 的情况,部分分片无法合并回一个完整的分片。这导致引入了被称为Nagle算法的更复杂的决策过程,并成为了后面章节介绍的拥塞控制机制所采用的策略的核心部分。
Nagle回答的中心问题是: 当有效窗口小于MSS时,发送者应该等待多长时间?如果等待太久,就会影响到交互式应用的性能。如果等待时间不够长,就有可能发送一堆小包,陷入愚蠢窗口综合征。
虽然TCP可以使用基于时钟的计时器(例如,每100毫秒触发一次),但Nagle引入了一种优雅的自时钟解决方案。其思想是,只要TCP有任何数据在传输,发送方最终将收到一个ACK。可以将此ACK视为计时器触发,从而触发传输更多数据。Nagle算法提供了一个简单而统一的规则来决定何时发送:
When the application produces data to send
if both the available data and the window >= MSS
send a full segment
else
if there is unACKed data in flight
buffer the new data until an ACK arrives
else
send all the new data now
换句话说,如果窗口允许,总是可以发送一个完整分片。如果目前没有传输中的分片,也可以立即发送少量数据,但如果有数据正在传输中,发送方必须等待ACK,然后再发送下一个分片。 因此,一个交互式应用每次持续写入一个字节,将以每个RTT一个分片的速率发送数据。有些分片将包含单个字节,而其他分片将包含用户在一个RTT时间内能够输入的所有字节。因为某些应用程序无法承受每次写入TCP连接时的这种延迟,所以套接字接口允许应用程序设置TCP_NODELAY选项,这意味着数据将被尽可能快的传输。
2.3 高速网络(High-Speed Networks)
TCP在20世纪80年代初首次部署,当时骨干网链路带宽以每秒几十kbps计。为适应不断增长的网络速度而调整TCP已经引起了很大的关注,这也没啥好奇怪的。原则上,TCP的变化是独立于后面章节中将介绍的拥塞控制机制的变化的,但这些变化是被部署在一起的,因此很不幸的合并了两个问题。为了进一步模糊灵活高速网络和寻址拥塞之间的界限,对TCP报头的扩展在处理两个问题中都扮演着重要角色。最后,请注意增加带宽时延积(bandwidth-delay product)确实会对拥塞控制产生影响,后面章节讨论的一些方法会处理这个问题。
本节主要关注高速网络的挑战,我们将用于解决这些挑战的TCP扩展的细节推迟到第四章,在第四章中我们也将相关的拥塞控制机制考虑在内。现在,我们主要关注SequenceNum和AdvertisedWindow字段的限制,以及它们对TCP正确性和性能的影响。
2.3.1 队列循环保护(Protecting Against Wraparound)
32位序列号空间的问题在于,给定连接上的序列号可能会出现循环,即发送了一次序列号为S的字节,然后在稍后时间需要发送相同序列号S的第二个字节。同样,我们假设数据包在互联网上存活的时间不能超过建议的MSL。因此需要确保序列号在120秒的时间内没有循环。这种情况是否会发生取决于数据在互联网上传输的速度,也就是32位序列号空间消耗的速度。(本讨论假设我们试图以尽可能快的速度消耗序列号空间,当然如果我们始终保持流水线处于满负荷状态,就可以达到这一点。) b表1显示了在不同带宽的网络上,序列号循环所需的时间。
表1. 32位序列号空间循环时间。
| 带宽 | 循环时间 |
|---|---|
| T1 (1.5 Mbps) | 6.2 小时 |
| T3 (44.7 Mbps) | 12.8 分钟 |
| OC-3 (148.6 Mbps) | 3.9 分钟 |
| OC-48 (2.4 Gbps) | 14.3 秒 |
| OC-192 (9.5 Gbps) | 3.6 秒 |
| 10GigE (10 Gbps) | 3.4 秒 |
32位序列号空间在中等带宽下是足够的,但考虑到OC-192链路现在在互联网主干中很常见,而且现在大多数服务器都有10G以太网接口(或10 Gbps),现在已经远远超过了32位的临界点。TCP扩展将序列号字段的大小增加了一倍,以防止SequenceNum字段循环,这个扩展在拥塞控制中扮演着双重角色,我们将在第4章中介绍细节。
2.3.2 保持流水线满负荷(Keeping the Pipe Full)
16位AdvertisedWindow字段的问题在于,它必须足够大,才能让发送方流水线处于满负荷状态。显然,接收方可以自由决定是否打开AdvertisedWindow字段允许的最大窗口,我们感兴趣的是接收端是否有足够的缓冲区空间来处理尽可能多的AdvertisedWindow允许的数据。
在这种情况下,决定AdvertisedWindow字段大小的条件不仅是网络带宽,还有带宽时延积,窗口需要打开的足够大,才能允许传输带宽时延积所定义的数据。假设RTT为100毫秒(这是美国跨国连接的典型数字),表2给出了几种网络技术的带宽时延积。注意,对于OC-n链接,我们使用的链路带宽删除了SONET开销。
表2. 所需的窗口大小为100毫秒RTT。
| 带宽 | 带宽 × 时延 积 |
|---|---|
| T1 (1.5 Mbps) | 18.8 KB |
| T3 (44.7 Mbps) | 546.1 KB |
| OC-3 (148.6 Mbps) | 1.8 MB |
| OC-48 (2.4 Gbps) | 28.7 MB |
| OC-192 (9.5 Gbps) | 113.4 MB |
| 10GigE (10 Gbps) | 119.2 MB |
换句话说,TCP的AdvertisedWindow字段比它的SequenceNum字段更糟。因为16位字段允许通告的窗口只有64KB,因此不够大,甚至不能处理横跨美国大陆的T3连接。
TCP的一个扩展对此做出了修复,允许接收方发布更大的窗口,从而允许发送方填充更大的带宽时延积,从而使高速网络成为可能。该扩展涉及到一个可选项,定义了通告窗口的规模(scaling) 因子。也就是说,与其将出现在AdvertisedWindow字段中的数字解释为发送方还有多少字节没有被确认,不如双方同意将AdvertisedWindow字段用来计数更大的块(例如,发送方有多少16字节的数据单位没有被确认)。换句话说,窗口规模选项指定TCP在用AdvertisedWindow字段内容计算有效窗口的时候,应该向左偏移多少位。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
[1]TCP Congestion Control: A Systems Approach: https://tcpcc.systemsapproach.org/index.html
- END -本文由 mdnice 多平台发布