Pytorch深度学习实战——加载数据集
看了一下刘二大人保姆级Pytorch教程,就先写个笔记记录一下,感兴趣的客官可以去B站看一下哦
教程地址:https://www.bilibili.com/video/BV1Y7411d7Ys?p=8
首先,区分一下Batch、Epoch 和 Iteration三个概念
Epoch:表示所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 ,简单地说就是一个Epoch就是将所有训练样本训练一次的过程
Batch-size:当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
batch-size就表示每次训练时所用到的样本数量
Iterations:训练一个Batch就是一次Iteration,加入一共有10,000个样本数,设置banchsize=1000,那么iteration=10,类似于迭代器的感觉。
这里如果还没有很明白的话可以去看:https://www.jianshu.com/p/22c50ded4cf7大大解释得还是很明白的~

加载数据集,即Dataloader,在这里直接up视频里讲得很详细(如下图),Dataloader:batch_size=2,shuffle=True,就表示两个样本为一个batch,并且shuffle=true表示每次迭代都需要打乱样本顺序
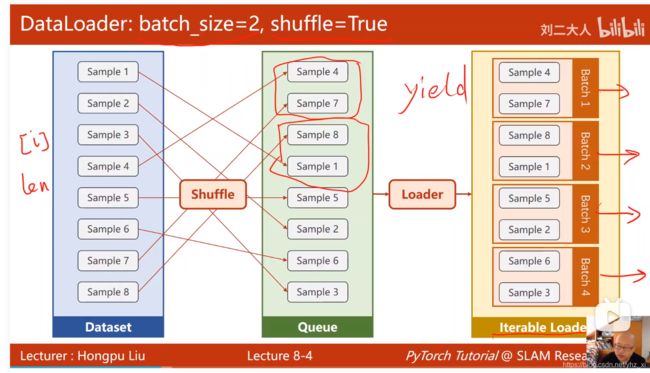
加载数据集代码:
import torch
from torch.utils.data import Dataset #抽象类,不能直接实例化
from torch.utils.data import DataLoader #用于加载数据,例如Batch_size,shuffle等,在使用时需要实例化
class MyDataset(Dataset):
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=xy.shape[0]
self.x.data=torch.frim_numpy(xy[:,:-1])
self.y.data=torch.frim_numpy(xy[:,[-1]])
def __grtitem__(self,index): #实现通过索引下标查找样本的操作
return self.x_data[index],self.y_data[index]
def __len__(self): #返回数据集的长度
return self.len
dataset = MyDataset()
train_loader=DataLoader(dataset=dataset, #数据加载器,numworker:多线程的线程数
batch_size=32,
shuffle=True,
num_workers=2)
#需要注意的是,因为windows系统和Linux系统实现多线程的函数不同,即windows为spawn,Linux为Fork,所以,加载代码必须封装一下,否则会出现RuntimeError问题
#因此写成以下形式:
if __name__ == 'main' :
for epoch in range(100):
for i, data in enumerate(train_loader,0) #或者也可以写成for i, (inputs,labels) in enumerate(train_loader,0)
#1. prepare data
inputs,labels=data
#2. Forward
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(epoch,i,loss,item())
#3. Backward
optimizer.zero_grad()
#4. Update
optimizer.step()torchvision.dataset
torch中自带的数据集包括:MINIST、Fashion-MINIST、EMMNIST、COCO、LSUN、ImageFolder、DatasetFolder、Imagenet-12、CIFAR、STL10、PhotoTour
调用方法:(以MINIST数据集为例)
import torch
from torch.utils.data import DataLoader
from torchvision import transfroms
from torchvision import datasets
train_dataset=dataset.MINIST(root='../dataset/minist' #训练集
train=True,
transform=transform.ToTensor(),
download=True)
test_dataset=dataset.MINIST(root='../dataset/minist' #测试集
train=False,
transform=transform.ToTensor(),
download=True)
train_loader=DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True) #训练阶段需要做shuffle,测试阶段可以不用做
test_loader=DataLoader(dataset=test_dataset,
batch_size=32,
shuffle=False)