【无监督】4、BYOL | 首个不使用负样本的对比学习框架

文章目录
-
- 一、背景和动机
- 二、方法
-
- 2.1 BYOL 网络结构
- 2.2 实现细节
- 三、效果
-
- 3.1 总体效果
- 3.2 和 SimCLR 的对比
- 四、BYOL 真的没有用到负样本吗?——BN 之讨论
论文:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
代码:https://github.com/deepmind/deepmind-research/tree/master/byol
出处:谷歌 DeepMind
贡献:
- 提出了使用两个模型 online network 和 target network 来实现的对比学习,这两个网络在训练的过程中会互相学习,输入两个网络的是一张图经过数据增强后两个图,训练 online 网络来预测 target 网络的输出,target 网络的更新是使用动量更新
- BYOL 不需要依赖于负样本也能很好的结果,也不会出现模型坍塌,这解决了之前基于负样本的对比学习对大的 batch size 的要求和 memory bank 的要求
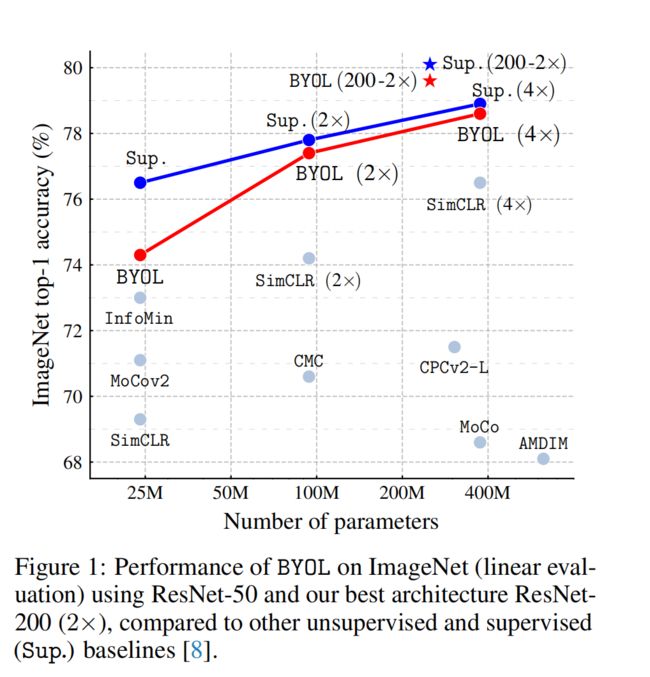
- BYOL 使用 linear evaluation 基于 ResNet50 在 ImageNet 上获得了 74.3% 的 top-1 acc
模型坍塌是什么意思:
- 对比学习中,假设使用一个网络来预测另一个网络的输出,那么当两个网络的输出非常接近的时候,loss 就会非常小
- 此时一个最简单的方法就是模型不管输入的是什么,都输出相同的向量,那么两个网络的输出自然完全相同了,loss 为 0,模型走了捷径,其实根本没有学习,偷懒了,这就是对比学习中的模型坍塌。
一、背景和动机
当前最好的对比学习方法同时 【最小化同一样本的不同 augmentation views 的差距(positive pairs)】和【最大化不同样本的 augmentation views 的差距】来实现的(negative pairs)
这些方法都需要使用较大的负样本,所以一般借助大的 batch size 或 memory bank 来实现,而且对使用的数据增强方式也比较敏感,使用不好的话容易不稳定
本文提出的 BYOL,在不需要使用负样本的情况下,都能达到 SOTA 的效果,作者认为不依赖负样本是 BYOL 模型鲁棒性较好的主要原因,而且 BYOL 对选用的数据增强方式也比较鲁棒
本文方法的名字中使用了 Bootstrap Your Own Latent,bootstrap 的意思就是提升、增强,latent 可以理解为特征。那么 BYOL 是怎么增强特征的呢,其没有使用 pseudo-label 等额外的东西,而是直接增强特征表达的
在这里我们简单说一下为什么对比学习需要负样本:
- 对比学习如果没有负样本的话,就只有了一个目标就是让所有正样本的物体的特征尽可能的相似
- 从 loss 函数上来说,如果没有负样本,只有一对正样本,那么 loss 函数就是这两个样本特征之间的距离,距离越小则 loss 越小
- 那什么时候 loss 最小的,就是当所有样本的特征完全一样的,loss 就是 0 了
- 这个时候模型就有一个捷径:无论输入是什么,我的输出都是一样的(比如无论输入什么,输出全都是 [0,0,0,0,0] 这种的),那么 loss 就是 0 了,模型就找到了一个捷径
- 所以对比学习需要负样本的 loss ,不光相似的物体要有相似的特征,不相似的物体也有不相似的特征,这样模型才有动力去学习,当输出全都一样的时候
BYOL 的动机:能不能不使用负样本的同时,还能避免模型坍塌呢。
BYOL 的具体做法:
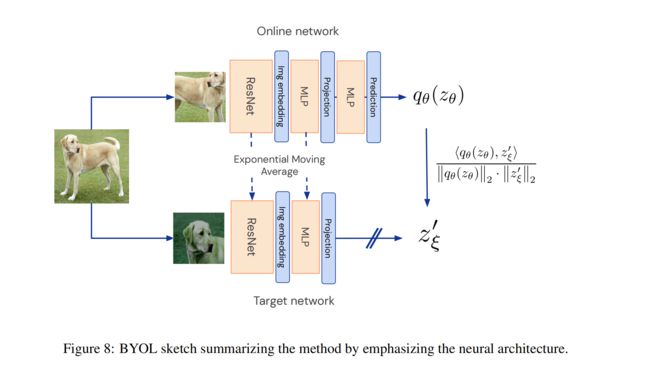
- 使用两个不对称的网络结构 online 和 target,online 比 target 多了 predictor,这样两个模型的输出很大概率是不会相同的,避免坍塌。下图紫色的三个部分的结构是相同的
- 而且使用 slow-moving 的方式来更新 target,能够让 target 网络编码更多信息,也能避免坍塌。
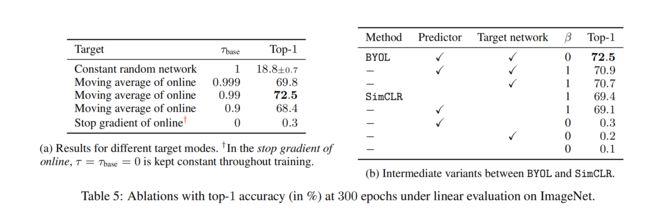
使用 EMA 方法更新 target 到底能带来怎样的效果:更新相对缓慢一些的话,效果越好(0.99 最好)
BYOL 使用 target 网络的输出作为 online 网络的学习目标,target 网络参数不使用梯度反传来更新,而是使用指数移动平均的方式来更新,所以 target 网络的参数相对于 online 网络的参数来说是一个 “延迟且稳定” 的版本。如果 target decay 为 1,则 target 网络不更新,网络非常稳定但效果很差。如果 target decay 为 0,则 target 网络实时从 online 网络更新,效果也不是很好。
图 5a 展示了如何平衡参数对模型更新的控制带来的最终效果,效果最好的 0.99 训练 300 epoch 的效果,说明 target 模型更新的越慢,模型越稳定,最终的效果越好。第一行是随机初始化一个 target 网络,且不更新其参数,最终效果为 18.8。最后一行是随着 online 实时更新,模型非常不稳定,最终的结果也很不好。
BYOL 具体是怎么直接 boostrapping 的呢:
- BYOL 训练的目标是让 online 网络来预测 target 网络的输出,target 的更新是根据 online 的模型参数动量更新的,随着训练的进行,target 模型的输出会越来越好,online 模型的学习也会越来越好,这里就体现了一种 boostrapping 的模式
二、方法

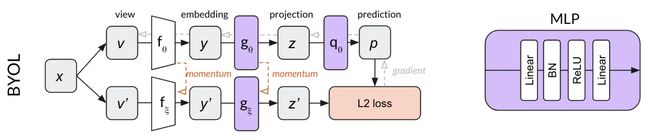
2.1 BYOL 网络结构
BYOL 的目标是学习一个特征表达 y θ y_{\theta} yθ,在推理的时候用作图像的特征表达
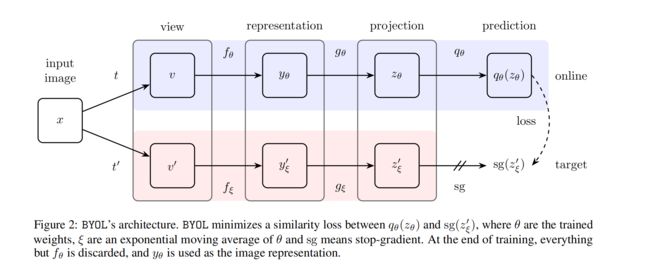
BYOL 的训练:
-
假设输入样本为 x,则会将其经过两种数据增强方式来获得两张不同的 augmentation view,分别作为 online network 和 target network 的输入
-
online network:根据梯度反传实时更新模型,参数为 θ \theta θ,输入图像先经过 encoder f θ f_{\theta} fθ,得到特征表达 y θ y_{\theta} yθ,再经过 projector g θ g_{\theta} gθ 得到映射结果 z θ z_{\theta} zθ,最后经过 predictor q θ q_{\theta} qθ 得到预测的输出
-
target network:参数为 ξ \xi ξ, ξ \xi ξ 是通过对 online network 的参数做动量更新而来的,即 ξ ← τ ξ + ( 1 − τ ) θ \xi \gets \tau \xi +(1-\tau)\theta ξ←τξ+(1−τ)θ,图中的 sg 表示 stop grident
-
图中能看出只有 online 模型有 predictor,target 模型是没有的,这样能让模型具有不对称性,提高模型效果
-
然后计算 online 输出和 target 输出 MSE,注意这里只展示了将 v 送入 online v’ 送入 target 的 loss,在训练时还会 v’ 送入 online v 送入 target,也会计算一遍 loss,loss 是两个 loss 的总和
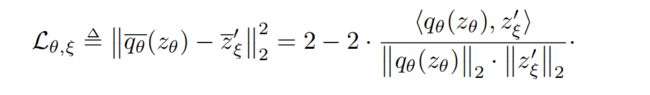
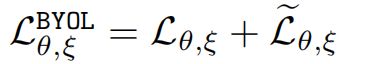
-
最后的更新方式为:
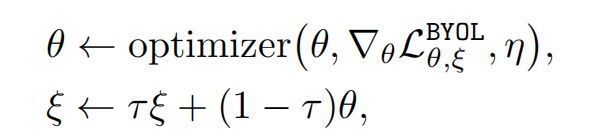
BYOL 的推理:
- 在训练完成后,只需要保留 f θ f_{\theta} fθ 即可,作为特征提取器,其他部分全部会舍弃掉
2.2 实现细节
1、数据增强
BYOL 使用的和 SimCLR 中一样的数据增强,首先使用 random crop 抠出部分图像,然后 resize 到 224x224 并使用随机水平翻转和颜色变换,最后使用了 gaussian blur
2、网络结构
online network 和 target network 的网络结构是完全一样的,基础版本是 R50
3、优化器
LARS 优化器,cosine decay learning rate
三、效果
3.1 总体效果
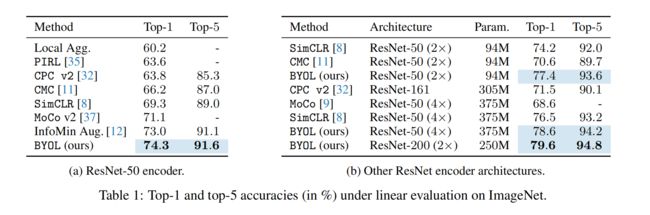
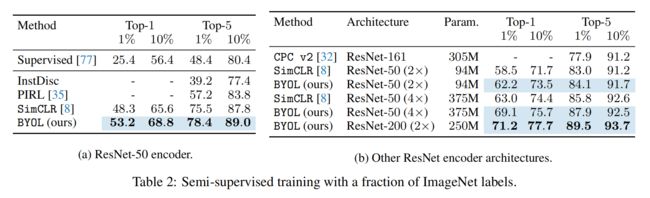
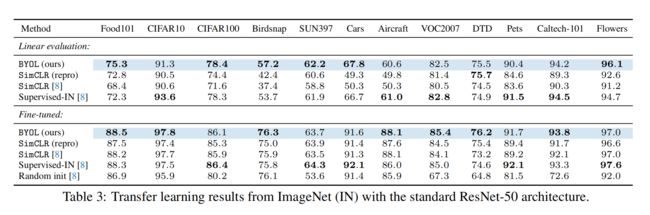

3.2 和 SimCLR 的对比
1、batch size 的对比
我们已知 SimCLRv1 为了引入更多的负样本,使用的 batch size=4096,这对硬件机器要求非常高
BYOL 由于没有负样本的限制,所以 batch size 就无需设置的很大
两者在不同 batch 下的效果对比如下图 3a,当 batch size 下降时,SimCLR 的效果下降的非常快,而 BYOL 的 batch 从 256 到 4096 时,效果变化不是很大
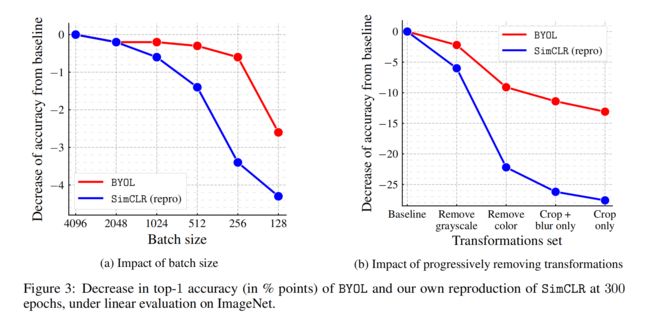
2、数据增强的对比
BYOL 没有 SimCLR 那样受是否有颜色变换的影响那么大
四、BYOL 真的没有用到负样本吗?——BN 之讨论
BYOL 论文出来后,出现了一个博文,讨论 BYOL 是真的没有用到负样本吗,因为有些人他们在复现的使用在 MLP 中没有使用 BN 层,导致效果特别差,而加上了 BN 层效果就好了,所以这些人就质疑说是 BYOL 其实是依靠 BN 获得了负样本的信息
BN 的操作是把一个 batch 中的所有特征拿来,计算均值和方差,然后用计算得到的方差来对这个 batch 做归一化,这也就意味着模型不止看到了一个图片,而是看到了这个 batch 中的所有图片的特征,也就相当于间接的看到了其他的样本,就出现了信息泄露,所以因为有信息泄露的存在,所以会把 batch 中的其他样本看做是隐式的负样本来学,所以 BYOL 这里不仅仅是在和自己学,而也在和其他样本做对比,它做的对比就是当前的正样本和平均图片的差别。
那究竟真的是这样吗?BYOL 是不是真的使用了负样本呢?BYOL 作者使用了丰富的实验证明了——否!
batch norm 主要是为了帮助模型训练的稳健,从而不会发生模型坍塌,也就是如果模型一开始初始化的比较好呢,就算不需要 bn 也能训练的很好
BYOL 的作者使用 GN 和 WS 训练,没有使用 BN 的时候,也能获得 73.9% 的效果,所以证明了 BYOL 的成功并不来源于 BN!
