Mybatis(四)【select】【insert,update,delete】
XML映射文件-select,insert,update,delete
所有介绍Mybatis的文章都会提及的一句话就是Mybatis减少了百分之九十五的代码,让开发者能够专注于SQL本身。实际上所有的流程是都是JDBC那一套,变化的是Mybatis增加了一些标签以及属性来代替JDBC设置字段值及类型,以及获取结果集时的一些代码。 Mybatis中的映射文件有几个定级标签,分别是:
- cache:该命名空间的缓存配置
- cache-ref:引用其他命名空间的缓存配置
- resultMap:SQL语句返回值结果集,被称为最强大的元素
- sql:可以被其他语句引用的sql片段,一般使用标签
- select:映射查询语句
- insert:映射插入语句
- update:映射更新语句
- delete:映射删除语句
tip:这里的标签没有前后顺序,Mybatis核心配置文件的标签是有顺序的
select
示例
<select id="selectById" parameterType="integer" resultType="com.evader.pojo.User">
select * from User where id = #{id}
select>
这个语句的id是selectById,可以理解为是接口中selectById方法的具体实现,这个方法的参数是一个int/Integet,返回值是一个User对象。它对应的接口是这样的:
User selectById(Integer id);
可以看到参数是使用#{id}来接收的,这么写Mybatis就会使用预处理语句参数,在JDBC中执行这个语句之前需要对?进行替换,上面的语句使用Mybatis是这样的:
String sql = "select * from User where id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1,id);
示例是一个简单的语句,实际select标签拥有很多属性
| id | sql语句唯一标识,与接口中的方法名相同 |
|---|---|
| parameterType | 该sql/方法的参数的类名或别名,可选的的属性,Mybatis可以通过类型管理器推断出参数的类型 |
| resultType | sql返回结果集的类的全限定名/别名,返回集合与单个对象时都填对象的类名 |
| resultMap | 对映射文件内的resultMap的引用,这是Mybatis最强大的标签 |
| flushCache | sql语句执行时是否清空本地缓存/二级缓存。true-清空,false-不清空(默认) |
| useCache | 是否缓存二级缓存,默认对select为true |
| timeout | sql执行异常时,等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动) |
| fetchSize | 给驱动的建议值,尝试让驱动程序每次批量返回的结果行数等于这个设置值。 默认值为未设置(unset)(依赖驱动)。 |
| statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。其中CallableStatement能够提高CPU的性能。 |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖数据库驱动)。 |
| databaseId | 数据库厂商标识(databaseIdProvider) |
| resultOrdered | 这个设置仅针对嵌套结果 select 语句:如果为 true,将会假设包含了嵌套结果集或是分组,当返回一个主结果行时,就不会产生对前面结果集的引用。 这就使得在获取嵌套结果集的时候不至于内存不够用。默认值:false。 |
| resultSets | 这个设置仅适用于多结果集的情况。它将列出语句执行后返回的结果集并赋予每个结果集一个名称,多个名称之间以逗号分隔。 |
insert,update,delete
插入,更新,删除的都是写操作,所以语句是差不多的,除了标签名之外,三者标签的属性也有一些差异。
<insert
id="insertAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
keyProperty=""
keyColumn=""
useGeneratedKeys=""
timeout="20">
<update
id="updateAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
timeout="20">
<delete
id="deleteAuthor"
parameterType="domain.blog.Author"
flushCache="true"
statementType="PREPARED"
timeout="20">
| id | sql语句唯一标识,与接口中的方法名相同 |
|---|---|
| parameterType | 该sql/方法的参数的类名或别名,可选的的属性,Mybatis可以通过类型管理器推断出参数的类型 |
| flushCache | sql语句执行时是否清空本地缓存/二级缓存。true-清空,false-不清空(默认) |
| timeout | sql执行异常时,等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动) |
| statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。其中CallableStatement能够提高CPU的性能。 |
| useGeneratedKeys | (仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
| keyProperty | (仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
| keyColumn | (仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
| databaseId | 数据库厂商标识(databaseIdProvider) |
示例
<insert id="insert" parameterType="map">
insert into user (id,name,password) values (#{id},#{name},#{password})
insert>
<update id="update" >
update user
set name = #{name},
password = #{password}
where id =#{id}
update>
<delete id="delete" >
delete from user where id = #{id}
delete>
小结:在大多数场景下,读操作开始比写操作要多的。因此select相关的属性就会多一些。插入操作时需要返回插入对象的主键时,可以使用对应的标签属性。
insert获取id的两种方式
方式一:通过useGeneratedKeys=“true” keyProperty="id"来获得插入对象的id
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
insert into user (id,name,password) values (#{id},#{name},#{password})
insert>

方式二:通过来获取插入对象的id
<selectKey keyProperty="id" resultType="int" order="AFTER">
select LAST_INSERT_ID()
selectKey>
insert into user (id,name,password) values (#{id},#{name},#{password})

小结:第一种方式是推荐的使用方式,第二种方式是执行标签中的语句获取到一个id后。在执行下方的插入语句,第二种方式相当于执行了两个SQL。两种方式的配置描述如下:
XML映射文件-参数
只有一个且是普通类型的参数 示例:
<select id="selectById" resultType="com.evader.pojo.User">
select * from User where id = #{idABC}
select>
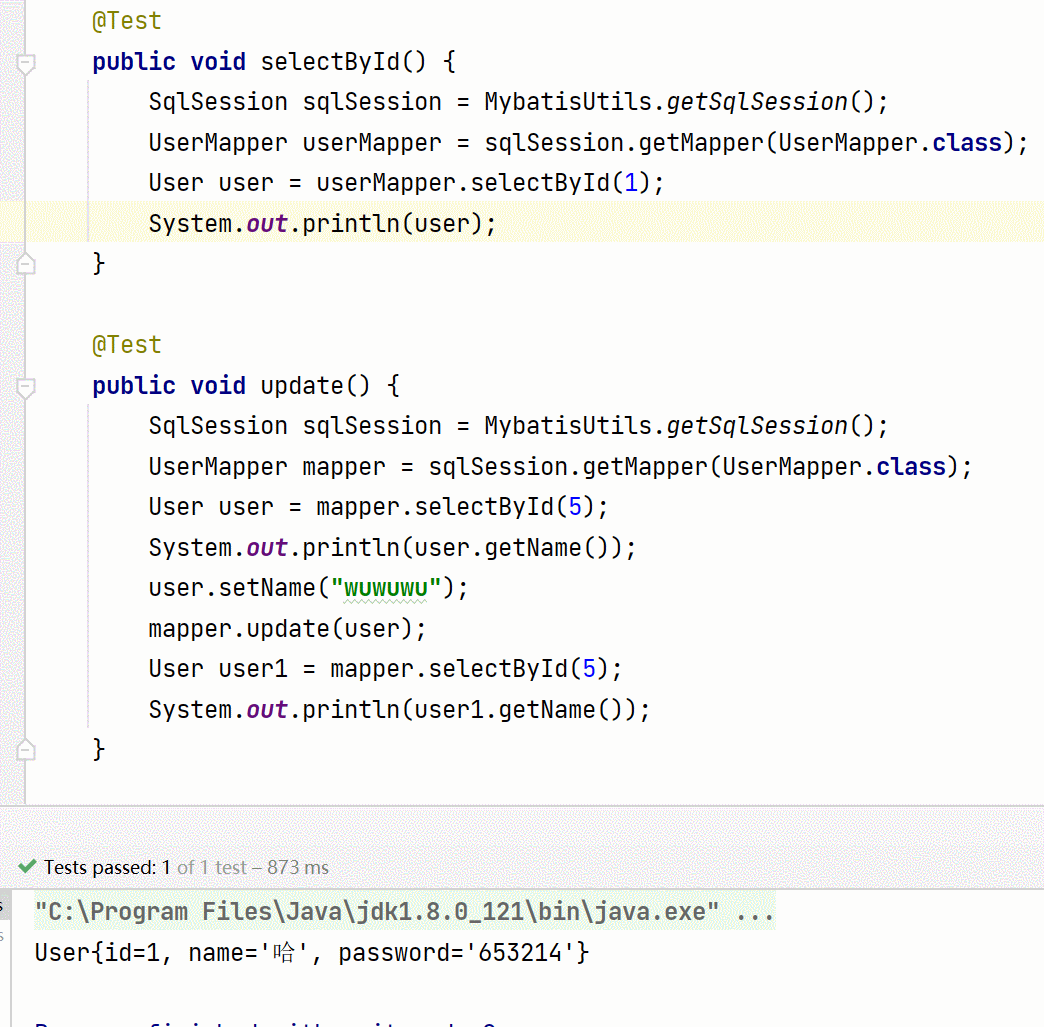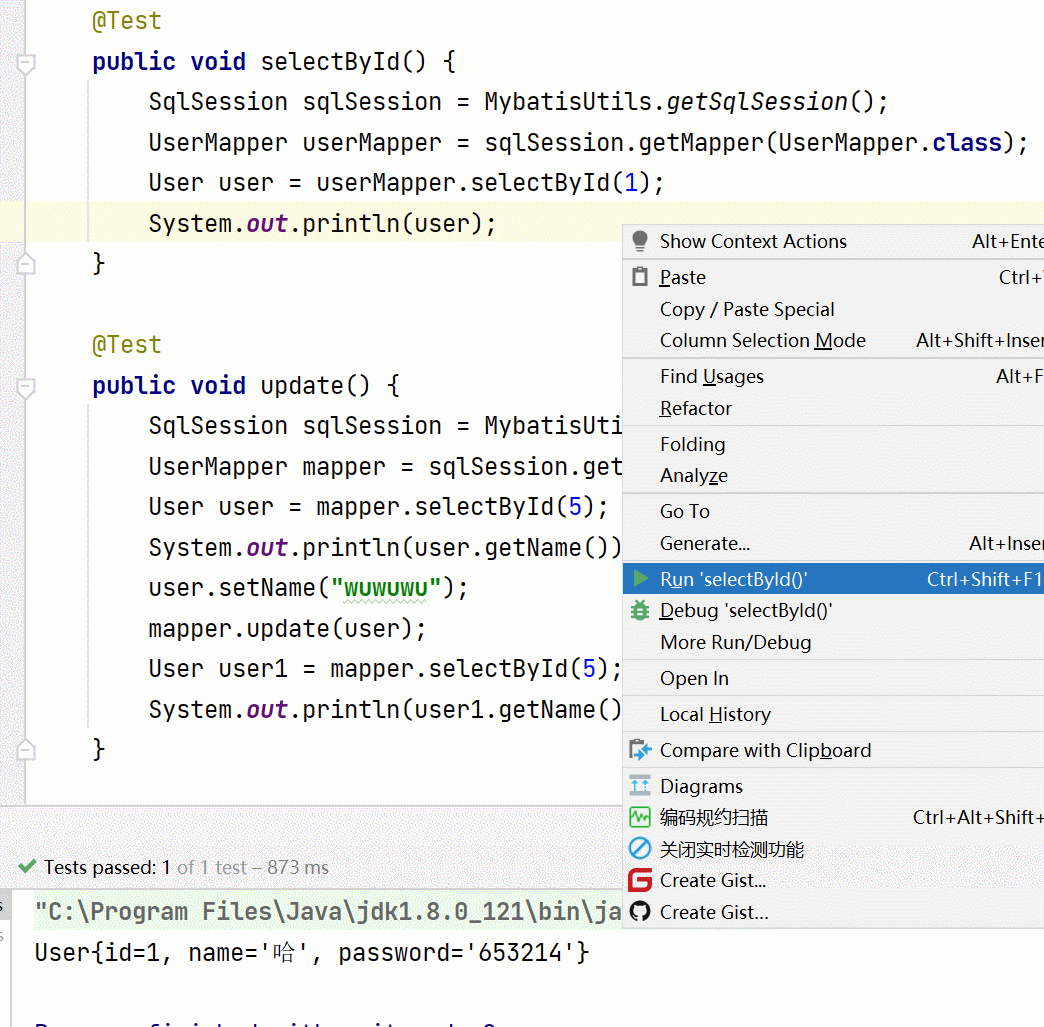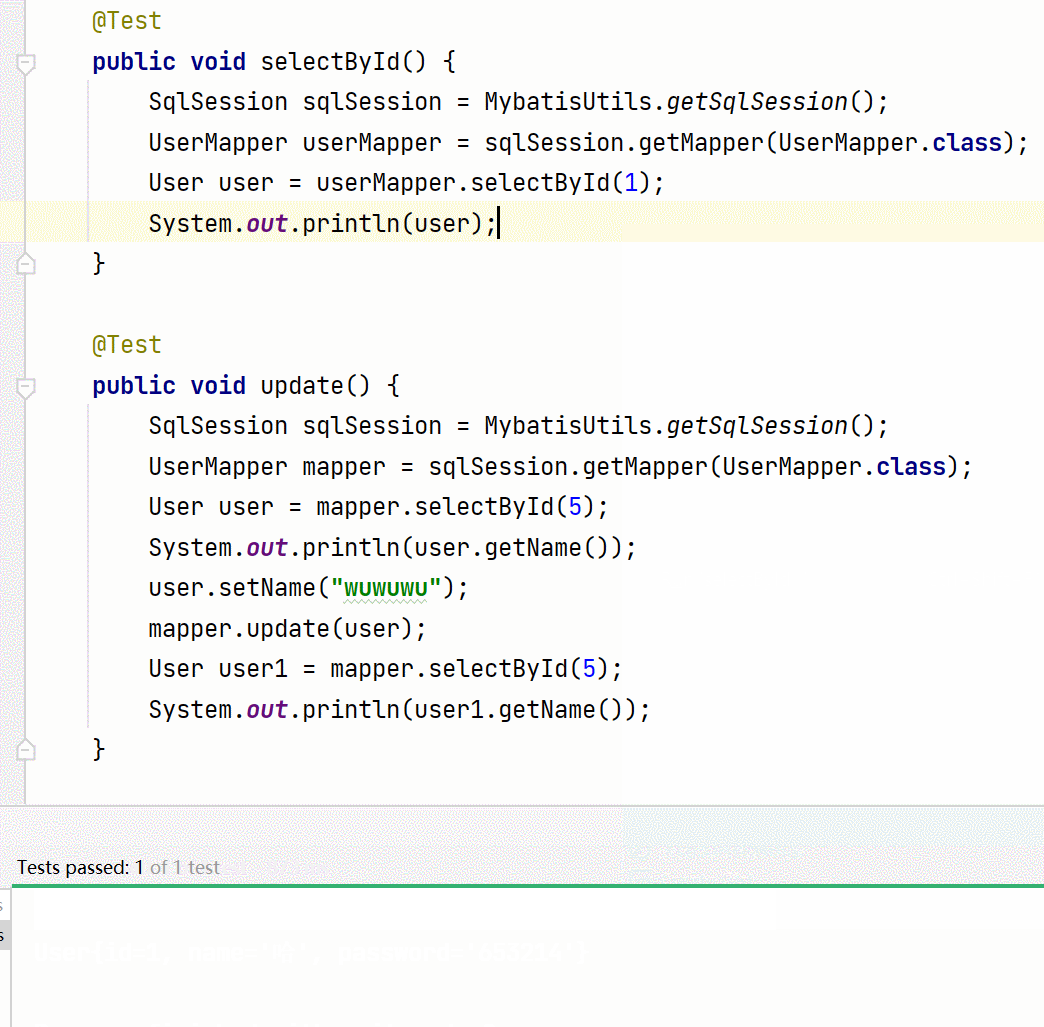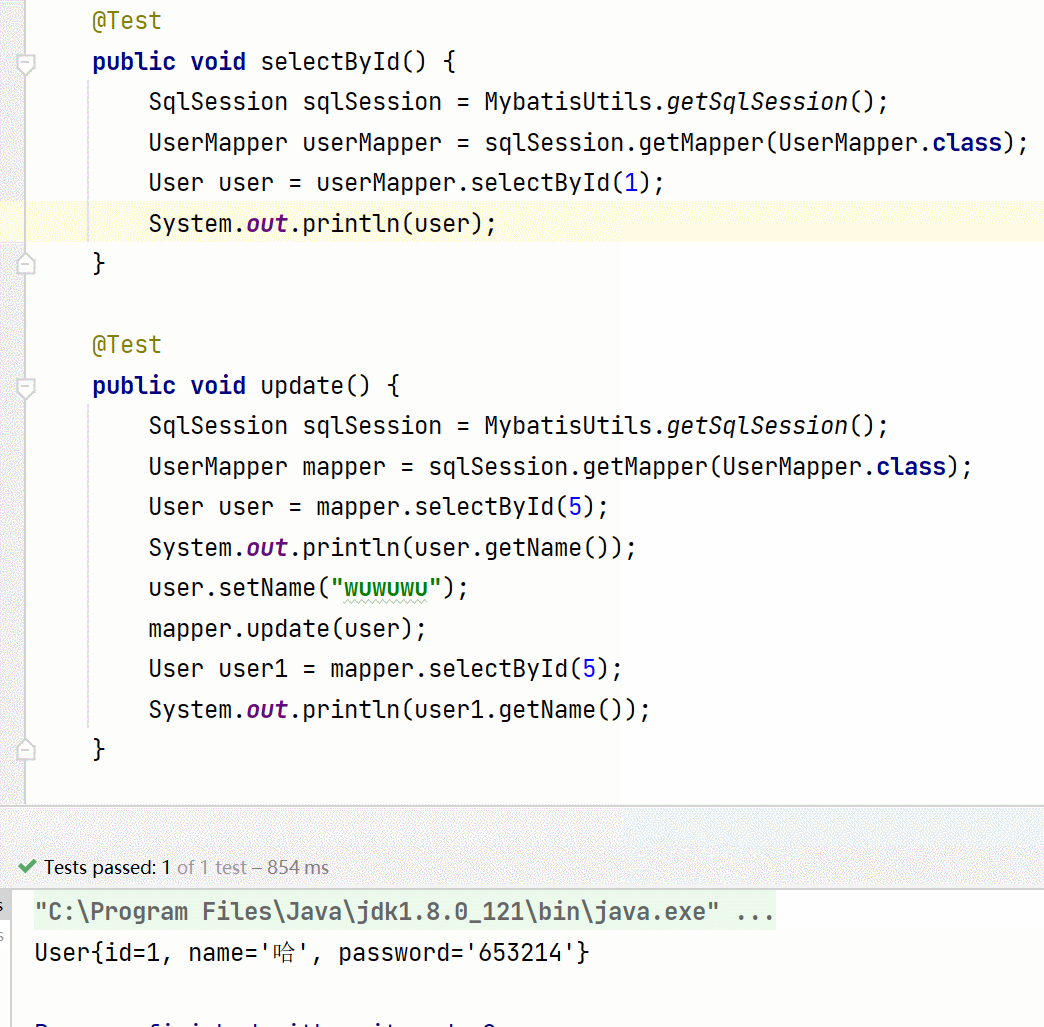
如果是一个参数且是简单类型时,#{}里面是可以不用与具体字段id对应的。因为就此时就只有一个参数,Mybatis的类型处理器能够自动推断出来。
参数是对象类型 示例:
<insert id="insertUser1" >
<selectKey keyProperty="id" resultType="int" order="AFTER">
select LAST_INSERT_ID()
selectKey>
insert into user (id,name,password) values (#{idABC},#{name},#{password})
insert>
插入方法通常传入的是一个对象,那么这个时候需要#{}中的字段与对象中的字段一一对应才会被识别。正如案例中的idABC执行失败,id执行成功了。
插入的对象可以为null时需要指定类型
这里的注释大概意思是如果设置一个参数为null,那么你应该写上这个参数的jdbcTpye,尽管Mybatis不会去读取它,如果不设置,数据库会抛出SQLException。
谁说${}一无是处?
面试中经常出现的一道题,Mybatis中#与KaTeX parse error: Expected 'EOF', got '#' at position 9: 的区别?但是对于#̲与,开发中大家基本没见过 , 所 以 它 淡 出 了 很 多 开 发 者 的 视 线 。 下 面 通 过 一 个 案 例 来 讲 讲 这 个 ,所以它淡出了很多开发者的视线。下面通过一个案例来讲讲这个 ,所以它淡出了很多开发者的视线。下面通过一个案例来讲讲这个的妙用。
<select id="selectPlus" resultType="com.evader.pojo.User">
select * from User where ${column} = #{value}
select>
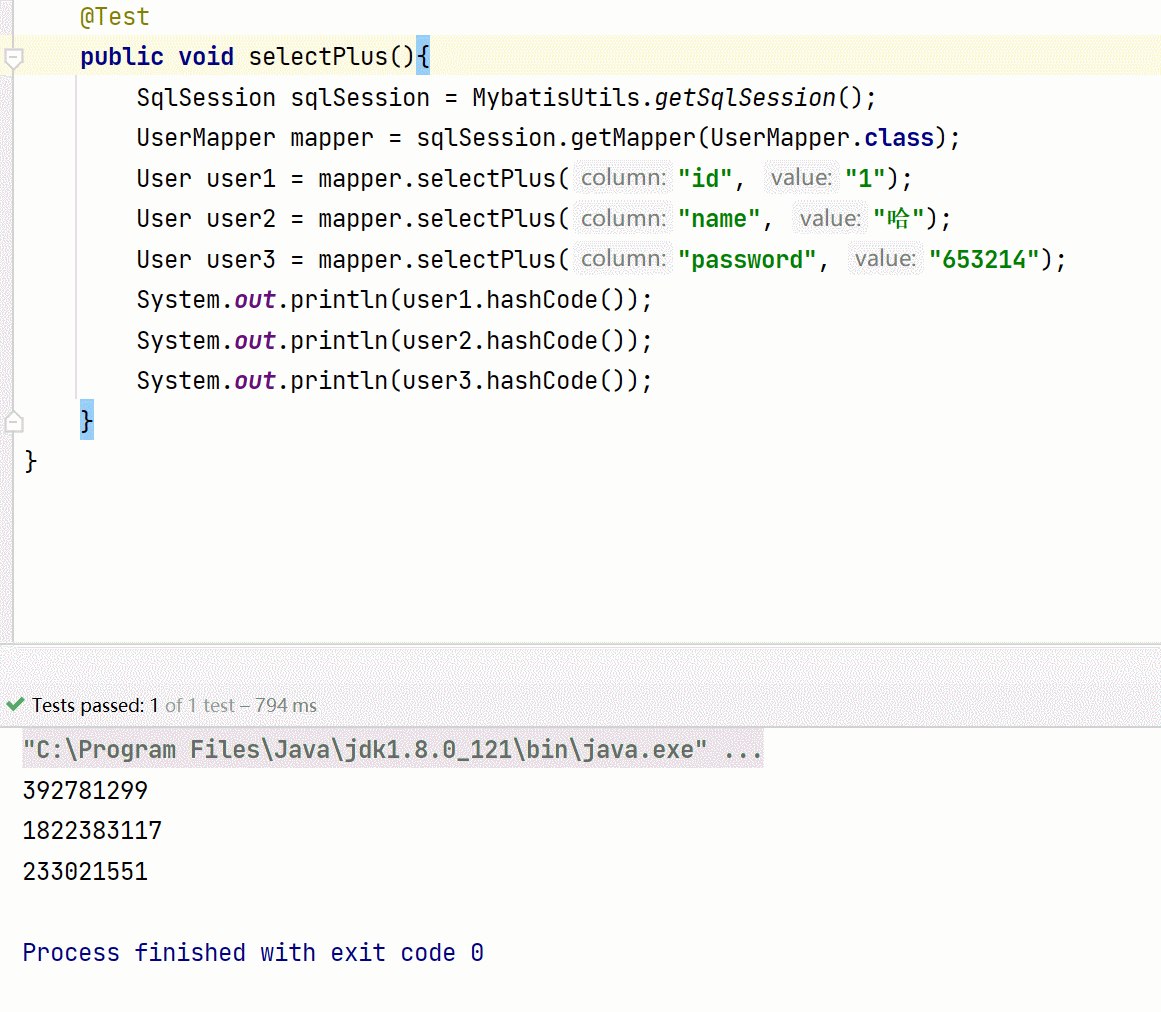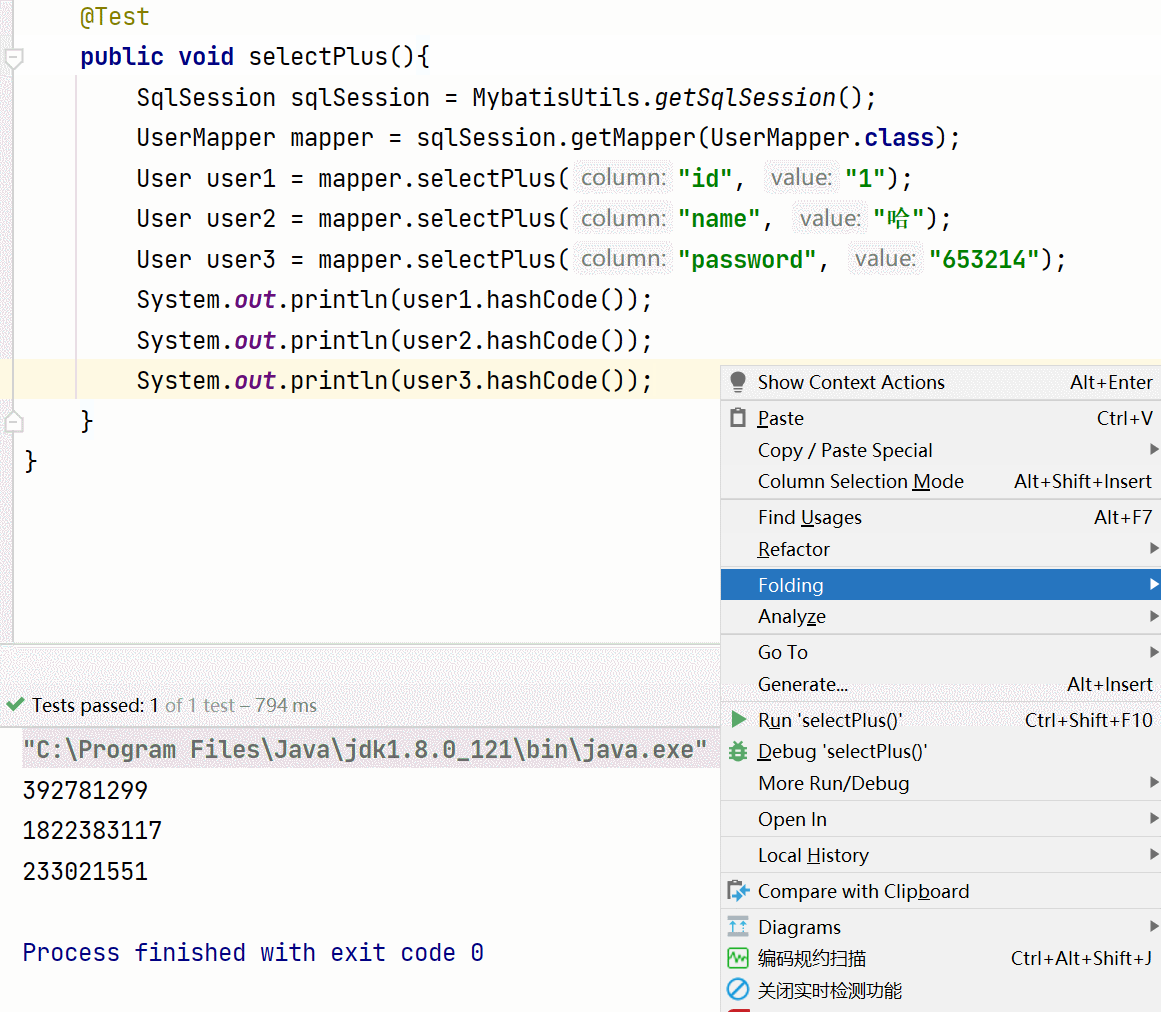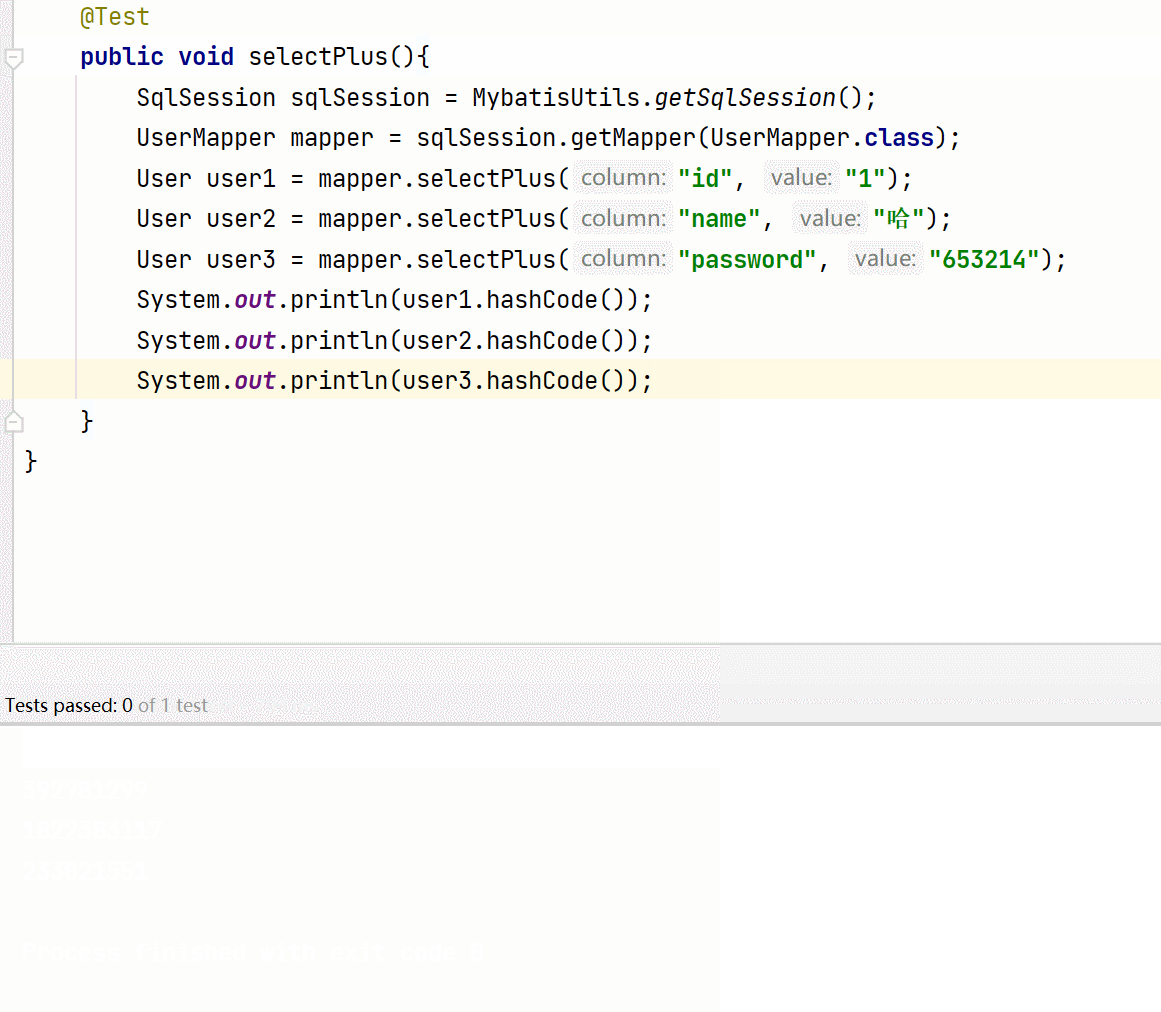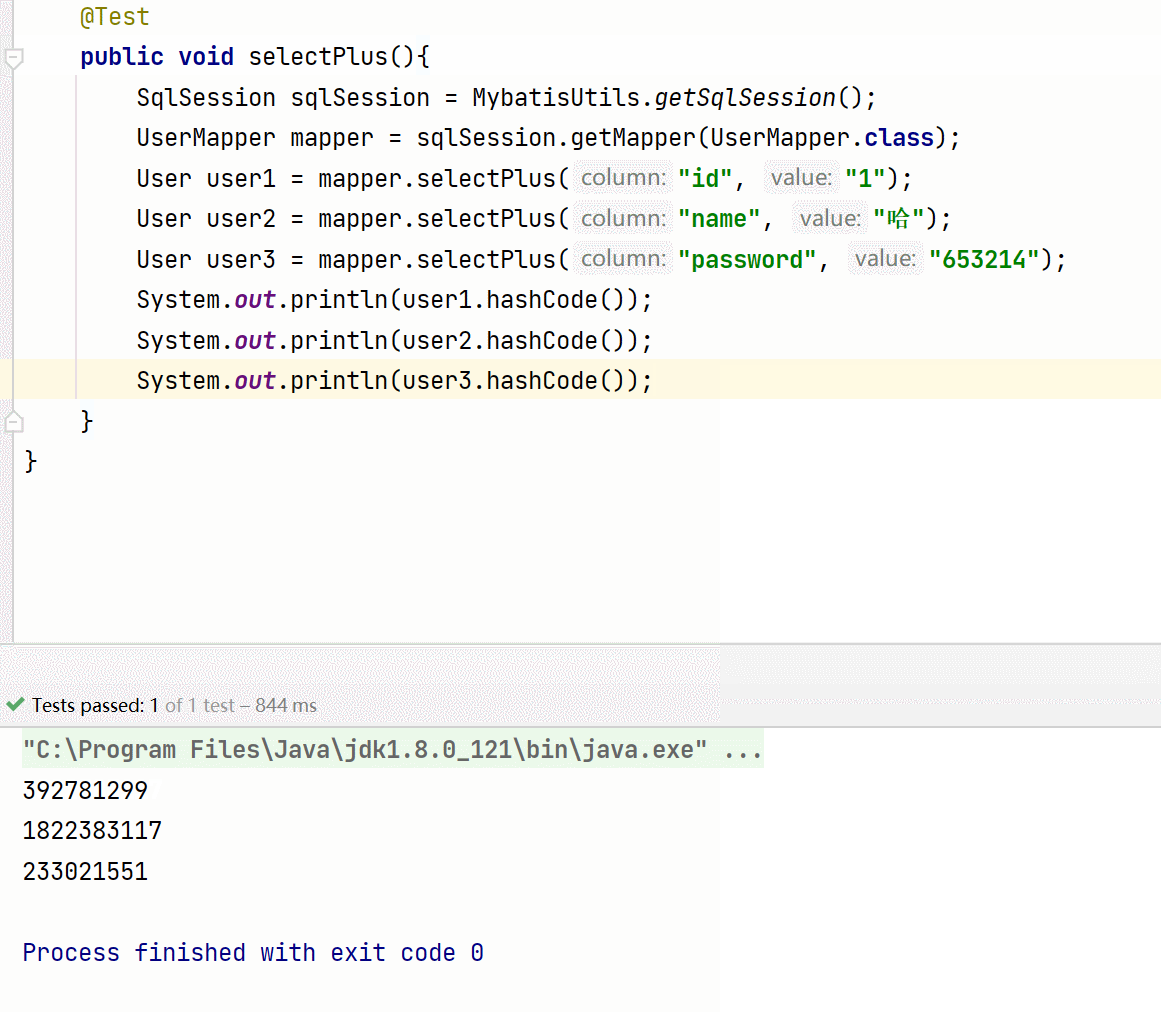
这个案例同时使用了KaTeX parse error: Expected 'EOF', got '#' at position 2: 与#̲,只用了一条sql就实现了通过…{column}直接被替换,而#{value}被预编译成了?
扩展知识,看看就行?
开发中使用generator生成的映射文件中的参数通常都是这样的:id = #{id,jdbcType = INTEGER},实际参数可配置的属性还很多,如下:
- typeHandler–指定类型处理器的名称或别名
- numericScale–指定保留的小数位数,只针对数字类型可用 、
- mode–指定IN,OUT,INOUT三种参数。
- structs–指定结构体
小结:通常我们使用Mybatis时只会用到jdbcType,其他的就交给Mybatis去推断吧。和 MyBatis 的其它部分一样,几乎总是可以根据参数对象的类型确定 javaType,除非该对象是一个 HashMap。这个时候,你需要显式指定 javaType 来确保正确的类型处理器(TypeHandler)被使用。