【OpenCV学习笔记】我的OpenCV学习之路
刚开始接触OpenCV是因为需要进行图像的处理,由于之前没有接触过,所以只能自己进行学习,下面将学习的过程做简单记录分享。
OpenCV专栏链接
OpenCV学习笔记
一、引言
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。它广泛应用于图像处理、人脸识别、目标检测、机器视觉等领域。学习OpenCV编程语言对于计算机视觉领域的开发人员来说非常重要。
二、基础知识
1.安装与基本操作
在开始学习OpenCV编程之前,需要先安装OpenCV库和相应的基本操作。
1.1 OpenCV安装:
pip install opencv-python
pip install opencv-contrib-python
1.2 OpenCV基本操作
1.2.1 读取图片
img = cv.imread("a.jpg")
1.2.2 显示图片
cv.imshow("img", img)
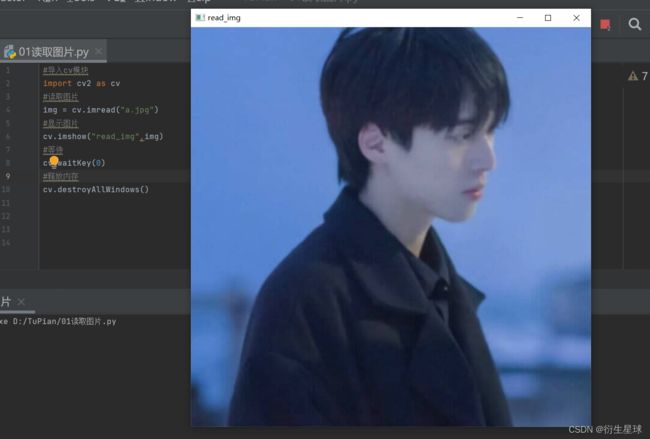
1.2.3 练习代码:
#导入cv模块
import cv2 as cv
#读取图片
img = cv.imread("a.jpg")
#显示图片
cv.imshow("read_img",img)
#等待
cv.waitKey(0)
#释放内存
cv.destroyAllWindows()
运行结果:
1.2.4 灰度转换
gray_img = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
1.2.5 修改尺寸
resize_img = cv.resize(img, dsize=(200, 200))
1.2.6 绘制矩形
cv.rectangle(img, (x, y, x + w, y + h), color=(0, 0, 255), thickness=1)
1.2.7 绘制圆形
cv.circle(img, center=(x + w, y + h), radius=100, color=(255, 0, 0), thickness=2)
2.图像的IO操作
2.1 读取图像
cv.imread()
1:彩色图像
0 :灰度图像
-1:alpha通道图像
2.2 显示图像
cv.imshow()/plt.imshow()
参数:
- 显示图像的窗口名称(以字符串表示);
- 要记载的图像;
注意:要调用**cv.waitKey()**给图像绘制留下时间,否则窗口会出现无响应情况,并且图像无法显示出来。
2.3 保存图像
cv.imwrite()
参数:文件名 要保存在哪里 要保存的图像
2.4 绘制直线
cv.line(img,start,end,color,thickness)
参数:
- img:要绘制直线的图像;
- start,end: 直线的起点和终点;
- color: 线条颜色;
- thickness: 线条密度;
2.5 绘制圆形
cv.circle(img, centerpoint, r, color, thickness)
参数:
- img:要绘制圆形的图像;
- centerpoint, r: 圆心和半径;
- color: 线条颜色;
- thickness: 线条密度,为-1时生成闭合图案并填充颜色;
2.6 绘制矩形
cv.rectangle(img, leftupper, rightdown, color, thickness)
参数:
- img:要绘制的图像;
- leftupper, rightdown: 左上角和右下角的坐标;
- color: 线条颜色;
- thickness: 线条密度;
2.7 向图像中添加文字
cv.putText(img, text, startion, font, fontsize, color, thickness, cv.LINE_AA)
参数:
- img:图像;
- text: 文本数据;
- startion: 字体放置位置;
- font:字体;
- fontsize:字体大小;
- color: 字体颜色;
- thickness: 字体密度;
2.8 展示效果
#导入cv模块
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 1 创建一个空白的图像
img = np.zeros((512, 512, 3), np.uint8)
# 2 绘制图像
cv.line(img, (0, 0), (511, 511), (255, 0, 0), 5)
cv.rectangle(img, (384, 0), (510, 128), (0, 255, 0), 3)
cv.circle(img, (447, 63), 63, (0, 0, 255), -1)
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(img, "OpenCv", (10, 500), font, 4, (255, 255, 255), 2, cv.LINE_AA)
plt.imshow(img[:, :, ::-1])
plt.show()
效果如下: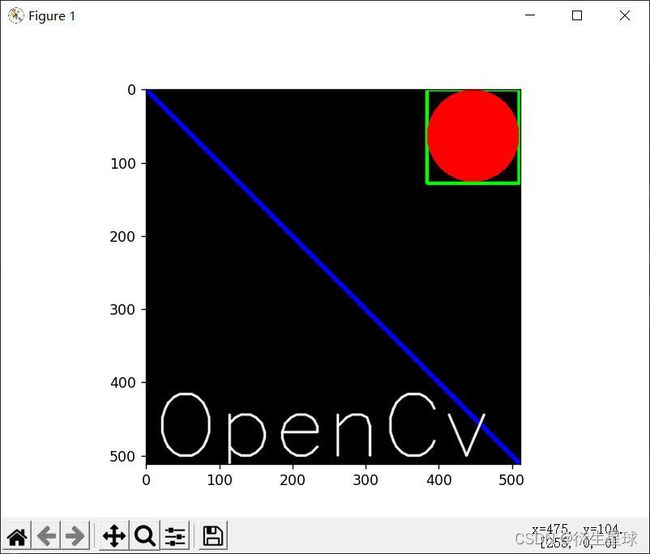
1.图像的加法
使用cv.add()函数将两幅图像相加(或者简单通过Numpy操作添加两个图像),两个图像应该具有相同的大小和类型,或者第二个图像可以是标量值。
区别:
- cv.add()–>饱和操作
- Numpy–>模运算
2.图像的混合
两个图像的权重不同
图像混合的计算公式如下:
g(x)=(1-α) f0(x)+α f1(x)
通过修改α的值(0–>1)实现炫酷的组合图。
函数cv.addWeighted()可以按下面的公式进行混合操作:
dst= α img1+β img2+Y
3.图像几何变换
3.1 图像缩放
cv2.resize(src,dsize,fx=0,fy=0,interpolation=cv2,INTER_LINEAR)
参数:
- src:输入图像。
- dsize:绝对尺寸,直接指定调整后图像的大小。
- fx,fy:相对尺寸。
- interpolation:插值方法。
| 插值 | 含义 |
|---|---|
| INTER_LINEAR | 双线性插值 |
| INTER_NEAREST | 最近邻插值 |
| INTER_AREA | 像素区域重采样 |
| INTER_CUBIC | 双三次插值 |
3.2 图像平移
cv.warpAffine(img, M, dsize)
参数:
- img:图像。
- M:2X3的移动矩阵。
- dsize:输出图像的大小。
注意:
- 将M设置为np.float32类型的Numpy数组。
- 输出图像的大小,应该是(宽度,高度)的形式,width:列数,height:行数。
4.图像旋转
在OpenCV中图像旋转首先根据旋转角度和旋转中心获取旋转矩阵,然后根据旋转矩阵进行变换,即可实现任意角度和任意中心的旋转效果。
API:
cv2.getRotationMatrix2D(center, angle, scale)
5.图像平滑
5.1 图像噪声
由于图像采集、处理、传输等过程不可避免的会受到噪声的污染,妨碍人们对图像理解及分析处理。常见的图像噪声有高斯噪声、椒盐噪声等。
5.1.1 椒盐噪声
椒盐噪声也称为脉冲噪声,是图像中经常见到的一种噪声,它是一种随机出现的白点或者黑点,可能是亮的区域有黑色像素或是在暗的区域有白色像素,或是两者皆有。
椒盐噪声的成因可能是影像讯号受到突如其来的强烈干扰而产生、类比数位转换器或位元传输错误等。例如失效的感应器导致像素值为最小值,饱和的感应器导致像素值为最大值。
5.1.2高斯噪声
高斯噪声是指噪声密度函数服从高斯分布的一类噪声。
5.2 图像平滑简介
图像平滑从信号处理的角度看就是去除其中的高频信息,保留低频信息。因此我们可以对图像实施低通滤波。低通滤波可以去除图像中的噪声,对图像进行平滑。
根据滤波器的不同可分为均值滤波,高斯滤波,中值滤波,双边滤波。
5.2.1 均值滤波
采用均值滤波模板对图像噪声进行滤除。令Pay表示中心在(x,y)点,尺寸为mxn的矩形子图像窗口的坐标组。均值滤波器可表示为:
由一个归一化卷积框完成的。它只是用卷积框覆盖区域所有像素的平均值来代替中心元素。
API:
cv.blur(src, ksize, anchor, borderType )
参数:
- src:输入图像
- ksize:卷积核的大小
- anchor:默认值(-1,-1),表示核中心
- borderType :边界类型
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1图像读取
img = cv. imread('./images/d1.jpg')
# 2均值滤波
blur = cv.blur(img, (5, 5))
# 3图像显示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img[:, :, ::-1]), plt.title('原图')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(blur[:, :, ::-1]), plt.title('均值波后结果')
plt.xticks([]), plt.yticks([])
plt.show()
运行结果:

5.2.2 高斯滤波
二维高斯是构建高斯滤波器的基础.
API:
cv2.GaussianBlur(src, ksize,sigmaX,sigmay, borderType )
参数:
- src:输入图像
- ksize:高斯卷积核的大小,注意:卷积核的宽度和高度都应为奇数,且可以不同
- sigmaX:水平方向的标准差
- sigmaY:垂直方向的标准差,默认值为0,表示与sigmaX相同
- borderType :填充边界类型
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1图像读取
img = cv.imread('./images/d2.jpg')
# 2高斯滤波
blur = cv.GaussianBlur(img, (3, 3), 1)
# 3图像显示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img[:, :, ::-1]), plt.title("原图")
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(blur[:, :, ::-1]), plt.title("高斯滤波后结果")
plt.xticks([]), plt.yticks([])
plt.show()
运行结果:

5.2.3 中值滤波
中值滤波是一种典型的非线性滤波技术,基本思想是用像素点邻域灰度值的中值来代替该像素点的灰度值。
中值滤波对椒盐噪声(salt-and-pepper noise)来说尤其有用,因为它不依赖于邻域内那些与典型值差别很大的值。
API:
cv.medianBlur(src, ksize)
参数:
- src:输入图像
- ksize:卷积核的大小
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1图像读取
img = cv.imread('./images/d3.jpg.jpg')
# 2中值速波
blur = cv.medianBlur(img, 5)
# 3图像展示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img[:, :, ::-1]), plt.title("原图")
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(blur[:, :, ::-1]), plt.title("中值滤波后结果")
plt.xticks([]), plt.yticks([])
plt.show()
运行结果:

6.边缘检测
边缘检测是图像处理和计算机视觉中的基本问题,边缘检测的目的是标识数字图像中亮度变化明显,图像属性中的显著变化通常反映了属性的重要事件和变化。
图像边缘检测大幅度地减少了数据量,并且剔除了可以认为不相关的信息,保留了图像重要的结构属性。有许多方法用于边缘检测,它们的绝大部分可以划分为两类:基于搜索和基于零穿越。
-
基于搜索:通过寻找图像一阶导数中的最大值来检测边界,然后利用计算结果估计边缘的局部方向,通常采用梯度的方向,并利用此方向找到局部梯度模的最大值,代表算法是Sobel算子和Scharr算子。
-
基于零穿越:通过寻找图像二阶导数零穿越来寻找边界,代表算法是Laplacian算子。
7.Sobel检测算子
Sobeli边缘检测算法比较简单,实际应用中效率比canny边缘检测效率要高,但是边缘不如Canny检测的准确,但是很多实际应用的场合,sobel边缘却是首选,sobel算子是高斯平滑与微分操作的结合体,所以其抗噪声能力很强,用途较多。尤其是效率要求较高,而对细纹理不太关心的时候。
sobel边缘检测的API是:
Sobel_x_or_y = cv2.Sobel(src,ddepth,dx,dy,dst,ksize,scale,delta,borderType)
参数:
- src:传入的图像。
- ddepth:图像的深度。
- dx和dy:指求导的阶数,0表示这个方向上没有求导,取值为0、1。
- ksize:是Sobel算子的大小,即卷积核的大小,必须为奇数1、3、5、7,默认为3。注意:如果ksize:=-1,就演变成为3x3的Scharr算子。
- scale:缩放导数的比例常数,默认情况为没有伸缩系数。
- borderType:图像边界的模式,默认值为cv2.BORDER_DEFAULT。
Sobel算子是在两个方向计算的,最后还需要用cv2.addWeighted()函数将其组合起来。
Scale_abs = cv2.convertScaleAbs(x)#格式转换
result = cv2.addWeighted(src1,alpha,src2,beta)#图像混合
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1读取图像
img = cv.imread('./images/ma.jpg',0)
# 2计算Sobel卷积结果
x = cv.Sobel(img, cv.CV_16S, 1, 0)
y = cv.Sobel(img, cv.CV_16S, 0, 1)
# 3将数据进行转换
# convert转换 scale缩放
Scale_absX = cv.convertScaleAbs(x)
Scale_absY = cv.convertScaleAbs(y)
# 4结果合成
result = cv.addWeighted(Scale_absX, 0.5, Scale_absY, 0.5, 0)
# 5图像显示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img, cmap=plt.cm.gray), plt.title("原图")
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(result, cmap=plt.cm.gray), plt.title("Sobel滤波后结果")
plt.xticks([]), plt.yticks([])
plt.show()
结果显示:

8.Laplacian算子
Laplacian是利用二阶导数来检测边缘。
АРI:
laplacian = cv2.Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]])
参数:
- src:需要处理的图像,
- ddepth:图像的深度,-1表示采用的是原图像相同的深度,目标图像的深度必须大于等于原图像的深度;
- ksize:算子的大小,即卷积核的大小,必须为1,3,5,7。
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1读取图像
img = cv.imread('./images/ma.jpg', 0)
# 2laplacian转换
result = cv.Laplacian(img, cv.CV_16S)
Scale_abs = cv.convertScaleAbs(result)
# 3图像展示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img, cmap=plt.cm.gray), plt.title('原图')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(Scale_abs, cmap=plt.cm.gray), plt.title('Laplacian检测后结果')
plt.xticks([]), plt.yticks([])
plt.show()
结果显示:

9.Canny边缘检测
Canny边缘检测算法是一种非常流行的边缘检测算法,是John F.Canny于1986年提出的,被认为是最优的边缘检测算法。
API:
canny = cv2.Canny(image, threshold1, threshold2)
参数:
- image:灰度图
- threshold1:minval,较小的阈值将间断的边缘连接起来
- threshold2:maxval,较大的阈值检测图像中明显的边缘
示例:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1读取图像
img = cv.imread('./images/ma.jpg', 0)
# 2Canny边缘检测
lowThreshold = 0
max_lowThreshold = 100
canny = cv.Canny(img, lowThreshold, max_lowThreshold)
# 3图像展示
plt.figure(figsize=(10, 8), dpi=100)
plt.subplot(121), plt.imshow(img, cmap=plt.cm.gray), plt.title('原图')
plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(canny, cmap=plt.cm.gray), plt.title('Canny检测后结果')
plt.xticks([]), plt.yticks([])
plt.show()
结果显示如下:

10.模板匹配
10.1 模板匹配
模板匹配:在给定的模板中查找最相似的区域
实现流程:
- 准备两幅图像
(1)原图
(2)模板图 - 滑动模板块和原图像进行比对
- 对于每个像素位置。将计算结果存在矩阵中,输入图像大小(WH),模板图像大小(wh),则输出矩阵的大小为(W-w+1,H-h+1)
- 查找最大值所在位置——最匹配的
10.2 实现
OpenCV中的方法实现模板匹配。
API:
res = cv.matchTemplate(img, template,method)
参数:
- img:要进行模板匹配的图像
- Template:模板
- method:实现模板匹配的算法,主要有:
(1)平方差匹配(CV_TM_SQDIFF):利用模板与图像之间的平方差进行匹配,最好的匹配是O,匹配越差,匹配的值越大。
(2)相关匹配(CV_TM_CCORR):利用模板与图像间的乘法进行匹配,数值越大表示匹配程度较高,越小表示匹配效果差。
(3)利用相关系数匹配(CV_TM_CCOEFF):利用模板与图像间的相关系数匹配,1表示完美的匹配,-1表示最差的匹配。
完成匹配后,使用cv.minMaxLoc0方法查找最大值所在的位置即可。如果使用平方差作为比较方法,则最小值位置是最佳匹配位置。
10.3 示例:
(1)原图:
(2)模板图:

(3)代码如下:
import cv2 as cv
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1图像和模板读取
img = cv.imread('images/wulin.jpg')
template = cv.imread('images/wulinmoban.jpg')
# 2模板匹配
# 2.1模板匹配
res = cv.matchTemplate(img, template, cv.TM_CCORR)
# 2.2返回图像中最匹配的位置,确定左上角的坐标,并将匹配位置绘制在图像上
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# 使用平方差时最小值为最佳匹配位置
# top_left = min_loc
top_left = max_loc
h, w = template.shape[:2]
bottom_right = (top_left[0] + w, top_left[1] + h)
cv.rectangle(img, top_left, bottom_right, (0, 255, 0), 2)
# 3图像显示
plt.imshow(img[:, :, ::-1])
plt.title('匹配结果'),plt.xticks([]),plt.yticks([])
plt.show()
(4)运行结果:

11.霍夫变换
11.1 霍夫线检测
11.1.1 API:
cv.HoughLines(img, rho, theta, threshold)
参数:
- img:检测的图像,要求是二值化的图像,所以在调用霍夫变换之前首先要进行二值化,或者进行Canny边缘检测
- rho、theta:精确度
- threshold:阈值,只有累加器中的值高于该阈值时才被认为是直线。
11.1.2 示例:
import numpy as np
import random
import cv2 as cv
import matplotlib.pyplot as plt
#1.加载图片,转为二值图
img = cv.imread('images/rili.jpg')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray, 50, 150)
#2.霍夫直线变换
lines = cv.HoughLines(edges, 0.8, np.pi / 180, 150)
#3.将检测的线绘制在图像上(注意是极坐标噢)
for line in lines:
rho, theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0=a * rho
y0=b * rho
x1 = int(x0+1000*(-b))
y1 = int(y0+1000*a)
x2 = int(x0-1000*(-b))
y2 = int(y0-1000*a)
cv.line(img, (x1, y1), (x2, y2), (0, 255, 0))
#4.图像显示
plt.figure(figsize=(10, 8), dpi=100)
plt.imshow(img[:, :, ::-1]), plt.title('霍夫变换线检测')
plt.xticks([]), plt.yticks([])
plt.show()
11.2 霍夫圆检测
在OpenCV中检测图像中的圆环使用的是API是:
v.HoughCircles(image, method, dp, minDist, paraml=100, param2=100, minRadius=0,maxRadius=0
参数:
- image:输入图像,应输入灰度图像
- method:使用霍夫变换圆检测的算法,它的参数是CV_HOUGH_GRADIENT
- dp:霍夫空间的分辨率,dp=1时表示霍夫空间与输入图像空间的大小一致,dp=2时霍夫空间是输入图像空间的一半,以此类推minDist为圆心之间的最小距离,如果检测到的两个圆心之间距离小于该值,则认为它们是同一个圆心
- param1:边缘检测时使用Canny算子的高阈值,低阈值是高阈值的一半。
- param2:检测圆心和确定半径时所共有的阈值minRadius和maxRadius为所检测到的圆半径的最小值和最大值
返回:
- circles:输出圆向量,包括三个浮点型的元素一一圆心横坐标,圆心纵坐标和圆半径
11.3 总结:
1.模板匹配
原理:在给定的图片中查找和模板最相似的区域
API:利用cv.matchTemplate0进行模板匹配,然后使用cv.minMaxLoc0搜索最匹配的位置。
2.霍夫线检测
原理:将要检测的内容转换到霍夫空间中,利用累加器统计最优解,将检测结果表示处理
API: cv2.HoughLines
注意:该方法输入是的二值化图像,在进行检测前要将图像进行二值化处理
3.霍夫圆检测
方法:霍夫梯度法
12.视频读写
12.1 从文件中读取视频并播放
在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件:
12.1.1 创建读取视频的对象
cap = cv.VideoCapture(filepath)
参数:
- filepath:视频文件路径
12.1.2 视频的属性信息
(1)获取视频的某些属性
retval = cap.get(propId)
参数:
- propld:从0到18的数字,每个数字表示视频的属性
常用属性有:
| flags | 意义 |
|---|---|
| cv2.CAP_PROP_POS_MSEC | 视频文件的当前位置(ms) |
| cv2.CAP_PROP_POS_FRAMES | 从0开始索引帧,帧位置 |
| cv2.CAP_PROP_POS_AVI_RATIO | 视频文件的相对位置(0表示开始,1表示结束) |
| cv2.CAP_PROP_FRAME_WIDTH | 视频流的帧宽度 |
| cv2.CAP_PROP_FRAME_HEIGHT | 视频流的帧高度 |
| cv2.CAP_PROP_FPS | 帧率 |
| cv2.CAP_PROP_FOURCC | 编解码器四字符代码 |
| cv2.CAP_PROP_FRAME_COUNT | 视频文件的帧 |
(2)修改视频的属性信息
cap.set(propId, value)
参数:
- proid:属性的索引,与上面的表格相对应。
- value:修改后的属性值
(3)判断图像是否读取成功
isornot = cap.isOpened()
- 若读取成功则返回true,否则返回False
(4)获取视频的一帧图像
ret, frame = cap.read()
参数:
- ret:若获取成功返回True,获取失败,返回False
- Frame:获取到的某一帧的图像
调用cv.imshow0显示图像,在显示图像时使用cv.waitkey0设置适当的持续时间,如果太低视频会播放的非常快,如果太高就会播放的非常慢,通常情况下我们设置25ms就可以了。
最后,调用cap.realease0将视频释放掉。
示例:
import numpy as np
import cv2 as cv
#1.获取视频对象
cap = cv.VideoCapture('路径')
#2.判断是否读取成功
while(cap.isOpened()):
#3.获取每一帧图像
ret, frame = cap.read()
#4.获取成功显示图像
if ret == True:
cv.imshow('frame',frame)
#5.每一帧间隔为25ms
if cv.waitKey(25)& 0xFF == ord('q'):
break
#6.释放视频对象
cap.release()
cv.destoryAllwindows()
12.2 保存视频
在OpenCV中我们保存视频使用的是VedioWriter对象,在其中指定输出文件的名称,如下所示:
创建视频写入的对象
out = cv2.VideoWriter(filename,fourcc, fps, frameSize)
参数:
- filename:视频保存的位置
- fourcc:指定视频编解码器的4字节代码
- fps:帧率
- frameSize:帧大小
- 设置视频的编解码器,如下所示:
retval = cv2.Videowriter_fourcc( c1, c2, c3, c4 )
参数:
-
c1,c2,c3,c4:是视频编解码器的4字节代码。
常用的有:
在Windows中:DIVX(.avi)
在OS中:MJPG(.mp4),DIVX(.avi),X264(.mkv)。 -
利用cap.read0获取视频中的每一帧图像,并使用out.write(将某一帧图像写入视频中。
-
使用cap.release0和out.release(释放资源。
示例:
import cv2 as cv
import numpy as np
#1.读取视频
cap = cv.VideoCapture("路径")
#2.获取图像的属性(宽和高,),并将其转换为整数
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
#3.创建保存视频的对象,设置编码格式,帧率,图像的宽高等
out = cv.Videowriter('outpy.avi',cv.Videowriter_fourcc('M','J','P','G'), 10,(frame_width,frame_height))
while(True):
#4.获取视频中的每一帧图像
ret, frame = cap.read()
if ret == True:
#5.将每一帧图像写入到输出文件中
out.write(frame)
else:
break
#6.释放资源
cap.release()
out.release()
cv.destroyAllWindows()
13.字符画效果
13.1 代码:
from PIL import Image
ascii_char = list('"$%_&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-/+@<>i!;:,\^`.')
def get_char(r, b, g, alpha=256):
if alpha == 0:
return ' '
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
unit = 256 / len(ascii_char)
return ascii_char[int(gray//unit)]
def main():
im = Image.open('A.jpg')
WIDTH, HEIGHT = 100, 60
im = im.resize((WIDTH, HEIGHT))
txt = ""
for i in range(HEIGHT):
for j in range(WIDTH):
txt += get_char(*im.getpixel((j, i)))
txt += '\n'
fo = open("A.txt","w")
fo.write(txt)
fo.close()
main()
13.2 原图

13.3 字符画效果

三、总结与展望
学习OpenCV编程语言对于计算机视觉领域的开发人员来说非常重要。通过掌握OpenCV的基础知识、函数和控制流程、面向对象编程等技术,可以更好地应用于图像处理、人脸识别、目标检测、机器视觉等领域。未来,随着计算机视觉技术的不断发展,OpenCV将会发挥更加重要的作用。