混合时间戳
MemFireDB,带你体验不一样的云端飞翔。
原文链接:混合时间戳
翻译自论文: HybridTime - Accessible Global Consistency with High Clock Uncertainty
摘要
在物理时钟不确定的分布式系统中保证全局一致性是很多分布式系统 (如分布式数据库) 要解决的问题。Google的Spanner数据库通过使用高精度时钟,降低时钟不确定性,然后使用提交等待(commit wait)来实现副本组之间的一致性,这项技术可以确保因果相关的事务在时间上以超过时钟同步误差界限的方式区分(解读:Spanner通过引入原子钟来解决不同物理服务器时钟误差不一致的问题。spanner的TrueTime返回的不是一个时间点,而是一个时间范围[t-ε,t+ε],通过这个时间范围可以保证,只要两个事务之间的时间差大于原子钟的误差边界,就可以区分两个事务的因果关系,误差越小,就越精确)。然而,对于其他数据库厂商来说,在谷歌数据中心之外使用类似的技术可能很困难,甚至不可能(例如,当使用像amazonec2这样的云服务时)。
在本文中,我们介绍了混合时间HybridTime(物理时钟和逻辑时钟的混合),可以用来实现一个全局一致性数据库。与Spanner不同,对于大多数事务,HybridTime不需要等待时间误差(解读:Spanner的TrueTime是一个范围时间,为了确保时间的准确性,事务会等待时间超过该误差再提交),因此可以用于常见的时间同步系统。我们在同一个系统中实现了HybridTime和commit wait,并在一系列实际场景中对HybridTime与Spanner的commit wait进行了实验比较,结果表明HybridTime在延迟方面的性能相较于Spanner的commit-wait可以提高1个数量级。
1. 简介
越来越多的分布式系统,如Spanner这样的分布式数据库,以前所未有的规模部署,并跨多个数据中心进行分区/复制,以降低服务延迟并提升容错能力。在这样的系统中,事务常常跨越多个数据中心,并涉及多个服务器,每个服务器服务于一个数据集的不同分区。
为了提供良好的性能,许多可伸缩的分布式数据库,如Amazon的Dynamo和Facebook的Cassandra,放松了一致性模型,只提供最终的一致性。其他如HBase和BigTable只为涉及单个分区的操作提供了强一致性,而无法跨数据库作为一个整体提供强一致性。
这些松散的一致性模型给应用程序开发人员带来了困难,他们通常习惯于针对完全线性化的单节点数据结构进行编程。
此外,如果最终用户看到一致性方面的异常,他们可能会感到惊讶和不安:例如,一个按地理分布的服务(多数据中心),用户可能首先被路由到本地数据中心并执行某些操作,例如发送电子邮件。如果他们重新加载浏览器并被路由到另一个数据中心,他们仍然希望在电子邮件发件箱中看到他们发送的消息。更松散的一致性模型,如时间线一致性或最终一致性运行这种异常,在这种模型下,用户在不同的数据中心可能会看到不同的数据,这对于银行或在线商务等许多应用程序来说可能是不可接受的。
解决一致性问题的最简单方法是在所有服务器上具有完全准确和同步的时钟;但是,由于在分布式系统中不可能实现绝对精确的物理计时,因此实现全局一致性的传统方法是使用逻辑时钟,例如:Lamport Clocks或者Vector Clocks。这种时钟可以提供全局的、因果一致的数据和更新视图,但有两个缺点:第一,它们要求所有客户端必须传播时钟数据以获得一致的视图;第二,分配的时间戳与物理时间无关。
因此,它们无法提供在物理时间点上的快照读请求,这是商业系统(如Oracle Flashback和ibm db2)以及学术项目(如Immortal DB)提供的功能。此外,用户希望他们所知道的在现实世界中发生的操作看起来是有序的,与系统是否能在它们之间建立因果关系无关,而Lamport时钟的向量时钟无法提供这一点。
值得一提的是,我们所指的一致全局状态不仅是服务于相同数据的不同副本之间的一致状态,而且是在数据库的不同分区之间保持一致的状态,这种状态本身可能分布在地理分布的数据中心中。像Spinnaker这样的系统使用Paxos来实现前者,但是对于跨分区操作,它又回到了悲观的锁定方案中。许多可伸缩数据库的应用程序都涉及到大量的分析工作负载,其中只读事务常常在整个数据集上运行。对于这些类型的事务,可能要运行几分钟甚至几个小时,基于锁的跨分区一致性方案是不可接受的,因为它们会阻止任何其他并发操作。
Spanner引入了commit wait,这是一种确保基于物理时间的全局状态一致性的方法,方法是强制操作等待足够长的时间,以便所有参与者都同意操作的时间戳已经越过了基于最坏情况下的误差边界。虽然具有创新性,但系统性能高度依赖于时间同步基础设施的质量,因此,如果没有专用硬件(如原子钟和GPS接收器),系统性能可能无法接受。通常情况下,用户可能会将应用部署在公有云上,例如Amazon EC2,因此不具备添加此类高精度计时设备所需的基础设施的条件。在本文中,我们提出了混合时间(HybridTime,HT),一种物理时钟和逻辑时钟的混合体,并且我们展示了如何使用HT来实现与Spanner相同的语义,但是即使在通常可用的时间同步的情况下(如:NTP等不完全精确的时间同步情况下),它也具有良好的性能。
与Spanner一样,我们的方法依赖于带有有界误差的物理时间测量来为系统中发生的事件分配混合时间戳。然而,与Spanner不同的是,我们的方法通常不需要等待错误,因此允许在常见的部署场景中使用,在这些场景中,时钟同步通过诸如NTP之类的公共协议进行同步,在这种情况下,时钟同步误差通常高于使用Spanner的TrueTime。权衡是,为了避免提交等待,HybridTime要求时间戳在机器之间传播,以实现与Spanner相同的一致性语义。与向量时钟相反,矢量时钟可以随着集群中参与者数量的增加而扩展,而混合时间时间戳具有恒定且较小的大小。
HybridTime时钟遵循与Lamport时钟相似的更新规则,但是时间值不是纯逻辑的:每个时间值都有一个逻辑组件,它有助于保证与Lamport时钟相同的属性,还有一个物理组件允许事件与物理时间点相关联。与逻辑时间戳一样,HT时间戳也需要附加到每个来自客户端的消息上。HT时间戳不受向量时钟问题的影响,向量时钟可以随着时间的推移从不同的机器中积累状态而增长。相反,它们更像是Lamport时钟时间戳,因为它们具有恒定和较小的大小。此外,与Lamport时钟和向量时钟相比,当两个事件之间的间隔超过最大时钟误差时,即使它们没有因果关系,或者如果它们的因果关系是通过系统无法捕获的隐藏通道建立的,也可以建立事件的时间顺序。
本文主要贡献如下:
- 我们介绍了HybridTime时钟,包括更新算法和正确性证明。
- 我们介绍了在现实中如何使用HybridTime时钟,与TrueTime在Spanner中的应用场景类似。
- 我们基于相同的场景与Spanner的TrueTime进行了对比。
- 我们描述了如何使用常见的硬件和软件实现commit-wait。
2. 背景和相关工作
Spanner的一个主要优点是外部一致性(externally consistent),这被定义为完全线性化,即使在存在隐藏通道的情况下。在本文中,我们使用外部一致这一术语。此外,我们使用术语全局一致性(globally consistent)来描述一个系统,该系统提供相同的线性化语义,前提是不存在隐藏通道。
尽管副本组内的一致性在大型数据库中得到了广泛的实现,但副本组间的一致性却不是这样。Dynamo[9]作者指出,他们使用向量时钟在一行中执行2个冲突解决,但没有为多行事务提供等效的功能。Cassandra[13]与Dynamo有相似之处,它使用普通的挂钟时间戳,没有考虑时钟误差,因此无论是在副本组内部还是在副本组之间,都不能提供一致性。类似地,BigTable[4]和它的开源版本HBase[1]在每台服务器上本地分配时间戳,并且不提供跨副本组(tablets)的一致性保证。水平分区的SQL系统,如MySQL(通常被描述为“sharded MySQL”)类似地提供分区内的一致性,但是不能跨多个分区查询快照。
如果所有参与者都能访问一个完全同步的物理时钟,那么实现一致的系统将是微不足道的。然而,众所周知,分布式系统中的服务器不可能拥有完全同步的时钟。即使使用时间同步机制,如NTP[21],在系统中不同机器上运行的进程也有不精确的时钟,与理论参考时钟相比,这些时钟会存在一些绝对误差。此外,现实生活中的时钟会随着时间的推移而出现偏差:不同机器上的时钟可能会随着时间的推移而彼此之间的距离越来越远。因此,数据库通常求助于其他机制来为事务分配时间戳,从而可以计算出因果一致的快照。其中一种时间戳机制是使用逻辑时钟,例如Vector Clocks[10,20]或Lamport Clocks[15]。使用这种时钟来排序事件的系统可以是全局一致的;但是,它们不具有外部一致性,因为它们要求所有客户端参与者传播时钟。例如,如果客户端A通过隐藏通道与客户端B通信而不转发时间戳,则不能保证客户端B能够看到客户端A执行的任何修改。
其他系统,如Percolator[22]、HBaseSI[27]和Cloudtps[26]使用一个集中的时间戳服务来为事务分配单调递增的时间戳,并确定序列化顺序。因此,它们在全球和外部都是一致的。但是,这种方法不能很好地扩展到高事务吞吐量,并且如果是地理分布的设置,在远程数据中心运行的事务将不得不为每个事务付出到时间戳服务的昂贵往返开销,并且会增加不可接受的延迟。有些系统在广域网中实现某种形式的因果一致性。COPS[18]或ChainReaction[2]在地理分布系统中实施因果关系约束,但不在时间戳中嵌入物理意义。最后,在物理时间和时钟错误的推理方面有值得注意的工作[24],其目的是允许以与逻辑时间类似的方式使用物理时间,例如全局谓词检测,但据我们所知,它还没有应用于分布式数据库。
Spanner的关键创新在于,系统分配的时间戳既可以用来实现外部一致性,又具有物理意义,而Vector Clocks和Lamport Clocks的时间戳是纯逻辑的。此外,Spanner分配具有已知有界误差的时间戳。我们将展示HybridTime也提供了具有物理意义和有界误差的时间戳。
3. HybridTime
3.1 HybridTime假设
与如何获得物理时间测量无关,HybridTime依赖于某些假设。在本节中,我们将介绍这些假设,并说明在大多数现代分布式系统部署的环境下,这些假设是合理的,TrueTime也做出了类似的假设。HybridTime假设机器有一个相对精确的物理时钟,能够提供绝对时间测量值(通常从1970年1月1日起以毫秒或微秒为单位)。几乎所有的现代服务器都配备了这样的物理时钟。我们用PCi(e)函数表示该物理时钟,该函数输出物理时钟返回的数字时间戳,表示进程i读取事件e的时间,
此外,我们假设有一个底层的物理同步设施,它使不同服务器之间的物理时钟相对于参考服务器“参考”时间保持同步,由PCref(e)函数表示,该函数输出由事件e的“参考”过程返回的数字时间戳。此外,我们假设这样的设施能够随每次测量提供有界误差,由Ei(e)函数表示,该函数输出进程i在事件e发生时的误差值ε。同样,这是合理的假设,因为几乎所有大型集群都执行时间同步守护进程,例如前面提到的NTP,它既同步服务器的时钟,又在任何时候提供时钟错误的最大限制。值得一提的是,TrueTime也做出了类似的假设。最后,我们注意到,我们对时钟的实际精度没有任何假设,即服务器时钟返回的物理时间戳可能有一个任意大但有限的误差,只要这个误差的界限是已知的。假设1形式化了PCref(e)、PCi(e)和Ei(e)之间的预期关系。
假设1:物理时钟误差是有界的
∀i, e : |PCre f(e)−PCi(e)| ≤ Ei(e) --- (1)
也就是说,我们假设每个服务器的物理时钟返回的物理时间戳的误差都在由Ei(e)函数限定的范围内。这个假设是合理的,因为大多数NTP部署确实提供了相对master的最大误差保证。Spanner的作者提到,TrueTime API做了类似的事情,尽管精度要高得多。值得注意的是,Ei(e)是一个进程相关的误差函数,每个进程一个,该函数的输出随进程和时间而变化。
假设2: 物理时钟时间戳在一个进程内部是单调递增的
∀i, e, f : e → f ⇒ PCi(e) ≤ PCi(f) --- (2)
也就是说,当查询服务器的物理时钟的当前时间时,它从不输出小于先前结果的值。同样,这是合理的:可以将NTP配置为通过在相当长的时间段内减慢或加快服务器时钟来调整服务器时钟,以确保依赖时间读取的应用程序不会受到调整的很大影响。在某些情况下,NTP可能会向前或向后跳过时间,但这种情况非常极端,通过监视NTP守护进程状态很容易检测到。当检测到此类事件时,服务可以选择自行关闭或故障停机。
在这些假设的基础上,我们将介绍HybridTime所依赖的物理时间戳API,这些API是基于物理时钟和NTP实现的。
3.2 HybridTime时钟和协议
在本节中,我们将介绍HybridTime Clock(HTC)。HybridTime Clock时间戳是一个pair算法2描述了HTC算法。
从HTC时钟获取时间戳的工作原理如下:每次需要为事件或消息分配时间戳时,会调用HTC.Now()函数来获取最新的时间戳。这个“最新”时间戳的物理分量要么是从物理时钟(PC)获得的值,要么是存储在最后一个物理时钟中的值,以较大者为准。类似地,“最新”时间戳的逻辑值要么是0(如果选择了当前PC值),要么是序列中的下一个逻辑值(如果选择了最后一个物理值)。
更新HTC时钟的工作原理如下:对于任何传入的时间戳(算法2中的“in”):
- 如果传入值的物理分量低于
HTC.Now()则不需要执行任何操作 - 如果传入值的物理分量等于
HTC.Now()我们将next_logical设置为当前逻辑值和传入逻辑值的最大值,再加一。 - 如果传入值的物理分量高于
HTC.Now()我们将last_physical设置为它,next_logical设置为传入时间戳的逻辑组件加1。
我们随后指出,如果将HTC时间戳解释为一个简单的字典式可比值,则算法2实现了Lamport时钟,其附加优点是生成的时间戳具有物理意义,并且在限定误差范围内准确表示物理时间。
定义1: HCT(e)< HCT(f)被定义为时间戳二元组(物理、逻辑)的字典序。
算法1:The Physical Clock API
i = server id()
function NOW : int physical, int ε
physical = PC_i(now)
ε = E_i(physical)
return p, ε
end function
算法2: The HybridTime Clock Algorithm
types:
type Timestamp of {int physical, int logical}
var:
int last_physical = 0
int next_logical = 0
PhysicalClock pc ; 提供算法1的API
function NOW : Timestamp
Timestamp now;
int cur_physical = pc.now().physical;
if cur_physical ≥ last_physical then
now.physical = cur_physical;
now.logical = 0
last_physical = cur_physical;
next_logical = 1;
else
now.physical = last_physical;
now.logical = next_logical;
next_logical++;
end if
return now;
end function
function UPDATE(Timestamp in) : void
int Timestamp now = Now();
if now.physical > in.physical then
return;
end if
last_physical = in.physical;
next_logical = in.logical + 1;
end function
混合时钟为事件保证了一定的顺序:
定理1: HybriTime时钟的happened-before关系构成了事件的总顺序
定理1的证明是显而易见的,因为我们使用字典序来排序事件。
虽然HybriTime时钟并没有直接利用时间测量误差,但前面已经说过这种测量误差是有界的,因此算法不会随着时间累积误差。这一点很重要,因为如果没有界限存在,那么时间戳的物理组成部分将变得毫无意义,而排序也只不过是用逻辑时钟定义的顺序。
我们首先定义HybridTime时间戳分配中的误差。让HTCi(f)表示一个HybridTime时钟时间戳分配,其形式为二元组(物理、逻辑)值。让t_real_f是f发生的“实时”时间,让error(f)是HybridTime时钟分配物理时间戳组件的误差,即:error(f) = t_real_f − HTCi(f).physical。
对于任何事件f,如果f从物理时钟获取其物理时间戳组件,由于假设1,我们知道在进程i(PCi())读取的任何物理时钟都有函数Ei()给出的有界误差,这意味着,在算法2中,如果事件取当前时钟读取的值(第11行),则其误差等于从物理时钟获得的误差。翻译如下:
∀ f,i : HTCi(f).physical = PCi(f)
→ error(f) ∈ [−Ei(f),Ei(f)]
现在,我们将证明,即使事件采用其前面事件的物理时间戳组件,其误差仍然是有界的:
定理2: 对于因果链f中的任何事件,HTC时间戳的物理分量近似于事件发生的“实时”时间,其误差为:
∀e, f,(e → f)
∧(HTCi(e).physical = PCi(e))
∧(HTCi(f).physical = HTCj(e).physical) ⇒
error(f) ∈ ]−Ej(e),Ei(f)[
附录A中提供了定理2的完整证明。定理2解释如下:如果分配给f的混合时间戳源于因果链中它前面的事件e,并且如果e的时间戳是从物理时钟获得的,那么将e的物理时间戳组件分配给f的物理时间误差在(−Ej(e), Ei(f))之间。
这意味着,使用本地物理时钟还是远端节点j的物理时钟的唯一区别是,误差的区间左值受节点j中发生e事件时测量的误差约束,而不是受本地误差的约束。
4. 实现
我们在一个研究原型上实现了HybridTime和commit-wait外部一致性,并在类似于Spanner设计的实际场景中进行了一系列实验。在这一部分中,我们介绍了研究原型数据库的一致性模式、体系结构和事务语义。
我们的实现同时支持多种外部一致性模式。客户端可以自由选择最适合该用例的模式,并为每个写请求选择一致性模式。支持以下一致性模式:
-
无一致性:在这种模式下,没有外部一致性保证,事务从每个服务器的物理时钟分配时间戳,并且不保证读取是一致的或可重复的。
-
HybridTime一致性:在这种模式下,我们使用HybridTime实现了与Spanner一样的全局一致性(没有隐藏通道)。在使用该一致性模型时,客户端必须确保将从服务器接收到的时间戳传播到其他服务器和客户端。在同一个客户端进程中,时间戳将代表用户自动传播。如果存在隐藏通道,即,如果写入或读取以没有传播时间戳,则无法保证外部一致性。
-
Commit-wait一致性:在这种模式下,我们的实现通过使用提交等待(Commit wait)来保证与Spanner相同的外部一致性语义。然而,我们没有使用TrueTime(它是一个专用的私有API),而是在广泛使用的网络时间协议(NTP)之上实现了提交等待。因此,在这种一致性模式下,我们支持隐藏通道。
这种灵活性意味着,当应用程序开发人员知道没有隐藏的通道,或者愿意传播时间戳时,他们不需要为commit-wait产生额外的开销。但是,如果应用程序开发人员确实使用了外部通道(例如企业服务总线或外部web服务),他们可能会在这些情况下选择性地应用commit-wait。根据作者在大型企业中使用大数据应用的经验,我们认为许多应用程序是完全封闭的系统,没有隐藏的通道,因此绝大多数事务可以使用HybridTime一致性。
注意: 为了防止恶意客户端操纵时钟,生产环境下的实现应该使用诸如HMAC之类的方案来验证时钟值。
4.1 架构
我们省略了研究原型数据库的完整实现细节,而是介绍了与不同一致性模式的实现相关的特性。我们的原型数据库对key space进行了分区,并将这些分区分布在多台机器上。这些分区类似于HBase中的regions或BigTable中的tablets。每个分区都有自己的副本组(Replica Group),通过类似Paxos的一致性算法来管理副本一致性,只有RG leader能处理写请求。在目前的实现中,每个分区都支持本地事务,即对单个分区的更新符合ACID,但跨分区的更新不是原子的(a)或孤立的(i)(尽管它们是持久的(D)和一致的©)。因此,想要读/写多个分区,客户端需要向每个分区发出独立的请求。
我们使用MVCC来存储每个数据的多个历史版本,每个版本都标有写入数据的时间戳,类似于BigTable或Vertica[14]/C-store[25]的设计。读取操作被分配一个时间戳,并且总是读取该时间戳之前最近写入的版本,忽略任何将来或过去的数据。
4.2 事务类型
我们的原型支持三种类型的操作,我们使用与Spanner相同的术语:
- Read-Write(RW) Transactions:RW事务包括所有改变现有数据的事务。一个RW事务之前可能有一个读操作或一系列读操作,并且需要在处理数据之前对每个要访问的行加锁。Spanner将RW事务分为两类:需要访问多个分区的事务和只需要访问一个分区的事务(Single RG Transaction)。在本文中,我们只实现和评估了后者,但解释了如何用HybridTime实现前者。
- Snapshot Transactions:Snapshot Transactions是针对
当前数据的无锁只读事务。也就是说,客户端请求某组数据的最新状态。然而,由于这些行可能跨越不同的分区,甚至数据中心,节点需要一致同意什么是当前数据,以及哪些数据是在当前之前提交的。 - Time-travel Read:Time-travel Read是针对
过去数据的无锁只读事务。也就是说,客户端请求的是过去某个物理时间点的某组数据的状态。同样,因为这些数据行可能跨越不同的分区或数据中心,所有参与的节点都需要就在选定的过去这个时间点之前提交了哪些操作达成一致。
值得注意的是,从客户端的角度来看,Snapshot Transactions和Time-travel Read之间的概念区别只是前者需要被分配一个与当前事务相对应的时间戳,而后者将其时间戳选为某个过去的时间点。由于这一点,在我们的实现中,我们只区分写事务和读事务,前者修改数据并为本次修改分配一个所有节点都同意的时间戳,后者在某个一致的时间点快照上执行读操作。Read-Write(RW) Transactions虽然从数据库的角度来看很有趣,但是在HybridTime的实现上没有什么区别,因为唯一相关的区别是它们经历了一个读阶段,在这个阶段中读锁是在写阶段之前获得的。
深入研究Spanner等数据库中的“外部一致性”概念,我们发现它非常接近两个基本概念:i)操作必须作用于并产生一致的全局状态[12](CGS);ii)操作必须是原子的,即当在单个事务下对多个分区执行操作时,某个观察者能同时观察到所有这些分区都产生了变更。实际上,i)意味着,如果一个客户端执行事务A,该事务涉及一组机器,然后执行另一个独立事务B,该事务涉及另一组不相交的机器,则其他客户端只能观察事务序列:[], [A], [A, B]。由于A和B是因果关系,所以序列[B]不是CGS,不应被观察到。另一方面ii)意味着如果一个客户端在一个分区上执行操作C,在另一个分区上执行操作D的事务,另一个客户端只能观察[]或[C, D]。
为了清晰起见,我们省略了这样一个事实:在几乎所有的消息交换中,客户端向服务器发送和从服务器接收它们最后一个已知的HT时间戳。类似地,这发生在服务器之间,区别在于服务器可以从HT时钟读取和发送当前值,而客户端不能获取HT,只能传播从其他服务器接收的HT时间戳。
4.3 Write Transactions
使用HybridTime执行Write Transactions与在Spanner中执行RW事务有相似之处。对于单个分区的Write事务,该分区的RG leader(Replica Group Leader)首先获取所有相关锁,然后为事务分配一个时间戳ts(ht)。当副本复制事务时,它们根据第3.2节中介绍的更新规则更新其HT时钟。一旦leader收到大多数复制确认,它就会应用更改,认为事务已提交,并通知客户客户端。因为对于每个事务,参与副本的HT时钟都会更新,所以它们同意ts(ht)x是过去的,这与执行读事务相关。由于所有Single RG Transaction都必须经过leader,因此可以保证,如果事务B在事务a的时间戳之后分配了一个时间戳,那么所有副本都将同意B跟在a之后。
涉及多个分区的事务需要一个协调器RG(coordinator RG),该协调器在每个分区RG的一致协议之上执行两阶段提交协议。在收到客户端的请求后,协调器RG的leader向所有参与者RG发出Prepare命令。每个参与者RG(participant RG)的leader获取相关锁并用其当前的HT时间戳进行应答。然后协调器RG leader选择接收到的时间戳中最高的一个,并将该时间戳分配给事务,在它向参与者RG leaders发送Apply命令时附带这些信息。在收到所有参与者已应用该事务的确认后,协调器RG负责人回复客户端。注意,在Spanner中,客户端驱动两阶段提交协议。这在这里也是一个类似的选择,但为了简单起见我们省略了这个选项。
客户端在每一个后续请求时都会携带从任何服务器获得的最后一个已知时间戳,很容易看出,根据HT时钟更新规则,从同一客户端启动到不同分区的顺序事务具有顺序时间戳,从而保证了所需的“全局一致性”属性。如果交易有因果关系,但其因果关系是通过隐藏渠道(即最后已知的HT时间戳未传播的渠道)建立的,例如,客户端1执行交易A,然后通过隐藏渠道使客户端2执行交易B,单靠时钟不能保证外部一致性。在这种情况下,用户可以显式地启用commit-wait来执行事务A,从而以提交延迟为代价来确保外部一致性属性。如果客户端1在通道上通信之前执行了许多写事务,则它们可以只在这些事务的最后一个操作上启用commit-wait,以便在对总体性能影响不大的情况下实现相同的一致性。
4.4 Read Transactions
所有读取事务都在全局状态的一致快照上执行,而不需要获取锁。单节点读取通过实现多版本并发控制[3](MVCC)来实现这一点,这是一种众所周知的数据库技术。客户端可以选择为事务指定时间戳,也可以不指定时间戳,在这种情况下,事务将以最新的状态执行。对于访问单个分区的读事务,如果客户端没有指定时间戳,则事务将由该分区的RG leader执行,因为它是唯一保证具有最新状态的节点。当接收到来自客户端的请求时,leader为事务分配一个HT时间戳,对应于从HT时钟获得的最新时间戳,获得MVCC快照并执行事务。对于单个分区的read事务,客户端可以指定一个过去的时间戳。RG中的副本需要在固定的、预先配置的时间间隔内跟上主机,否则将被逐出。这意味着,如果客户端希望读取某个时间点的数据,并且知道该时间点相较于目前的时间差大于副本之间同步的最大时间差,它可以将请求路由到任何副本,而不必强制将请求路由到leader,因为它可以保证,如果副本仍在活动状态,它将包含包括请求时间点之前的所有数据。如果客户端指定的时间点比前面提到的时间段更近,则事务将被路由到leader。跨多个分区的Read事务的执行方式与单个分区的事务非常相似,但有一些细微差别。如果客户端没有提供时间戳,或者如果指定的时间戳与当前非常接近,以至于它落在至少一个副本的最大物理时间测量误差(通常设置为1秒)之内,则必须执行初始协商回合,其中客户端从所有参与者获得当前时间戳并选择最旧的作为快照的时间戳。然后,读事务继续进行,就像在单个分区情况下一样。在这种情况下,Spanner的作者选择让客户端在所有情况下选择时间戳,这避免了最近事务的初始协商回合,但可能会迫使读取事务等待所选时间戳是安全的(即肯定是在过去)。我们选择不采用这种方法,因为客户端可能经常运行在不同步的机器上。由于在本文中没有足够的时间,我们没有实现协商阶段,在协商阶段,客户端从leader那里获得最新的时间戳,而将我们的评估重点放在单个分区Read事务上。我们注意到,Spanner论文也没有衡量这类事务,我们没有进行比较的依据。
5. 实验和评估
在本节中,我们将展示我们的实验结果和搭建过程,并演示HyBrid Time如何跟commit-wait以前使用,以及它在延迟方面的比较。
5.1 压力测试工具
我们使用众所周知的YCSB[6]作为所有实验的压力测试工具。我们使用了最多三个并发的客户端,每个运行8个线程,其中60%是插入,20%是更新,20%是单行读取。这三个客户端对应于三种不同的一致性模式:每个客户端使用一种模式执行所有写操作。
5.2 实验配置
我们在Google Compute Engine中进行了所有实验。所有实验均在美国中部1-a和欧洲西部1-a“区域”进行。在每个“区域”中,我们组装了10台n1-standard-8型机器。这种类型的机器有8个“虚拟CPU”,每个CPU对应于“2.6GHz Intel Sandy Bridge Xeon或Intel Ivy Bridge Xeon(或更高版本)处理器上的单个超线程”,因此,更准确地说,每台机器都有4个带超线程的内核。每台机器也有30GB的内存,我们在每台机器上附加了一个容量为350GB的“持久磁盘”,格式化为ext4格式,我们在其中存储数据库的持久数据和WAL日志。我们的原型数据库运行在Linux上,因此每台机器都被引导到debian-7-wheezy映像。操作系统安装到与存储该数据库数据的分区不同的磁盘分区。
服务器运行NTP版本为4.2.6,并修改如下配置:
- 时间服务器配置为Google Compute Engine提供的时间服务器。我们假设这个时间服务器与我们进行测试用的服务器在一个数据中心,从而提供较低的RTT和良好的时钟质量。我们相信,大多数数据中心在短时间内就已经有了NTP源,随着使用HybridTime等技术的数据库变得越来越普遍,云提供商会将高质量的NTP服务器作为标准基础设施。
- 最大轮询间隔设置为8秒,以确保时钟误差边界经常同步。
- Allan intercept配置修改为8秒。
这些非标准配置降低了时钟误差同时也降低了实际时钟精度。也就是说,因为频繁的时钟同步带来的抖动对会影响实际时钟质量,但是提供给内核的最大误差会持续保持在比较小的范围。对于HybridTime这样的系统,与较小的平均时钟偏移相比,更严格的误差限制对应用程序更有好处。下表显示了我们从集群中提取的一个和两个数据中心的最大错误差:
| NTP Max. Error | Min. | Max. | Avg. | Stddev |
|---|---|---|---|---|
| Single DC | 11.5 | 16.7 | 14.73 | ± 2.468 |
| Two DCs | 12.3 | 20.1 | 16.36 | ± 2.581 |
除非明确说明,所有实验结果都是在启用了完全持久性的情况下获得的,也就是说,如果系统没有为客户端的数据调用fsync()/fdatasync(),则数据不可见,从而将机器崩溃时丢失数据的机会就降到了最低。这与一些广泛使用的大型数据库的设置不相上下,例如Cassandra使用一个后台线程周期性地调用fsync(),在发生断电时就存在一个丢失数据的时间窗口,而撰写本文时HBase还没有“适当的fsync支持”。
由于我们的实验室在IaaS上进行的,所以我们无法获得存储系统的硬件/软件布局,因此无法完整描述Google Compute Engine中的“持久磁盘”是如何实际实现的。但是,由于持久性通常是任何数据库的主要关注点,而fsync()系统调用通常需要在硬件上完成,因此我们对存储介质的延迟特性进行了一些测量,在这些介质中,我们保存了数据和WAL。我们使用“flexible I/O tester”基准测试工具,配置了有2个writer和2个reader,每个writer对每个写操作进行fsync()/fdatasync()调用,写入块大小时1KB,与数据库基准工作负载中的一行大小大致相同。对于本文来说,最相关的结果是写延迟,因为它们可能代表了total request time的一个重要部分,测试结果是(毫秒):min=1,max=39,avg=1.93,stdev=2.08。这意味着,平均而言,每个客户端请求将花费至少2毫秒的时间等待I/O,这是我们在下一节描述的实验中的一个重要因素。
5.3 实验1:Single datacenter, no consensus
实验1的目标是揭示每种一致性模式对请求延迟的影响,而不考虑其他数据库问题,如持久性或容错性,因为满足这两个需求对数据库性能有很大的影响。我们在这个实验中要回答的问题是,撇开其他数据库问题不谈,不同一致性模式的独立影响是什么:no consistency、HybridTime consistency、Commit-Wait consistency在total request latency上的不同。因此,对于这个实验,我们禁用了fsync()调用,依靠操作系统缓冲区来最好地选择实际保存数据的时间。此外,对于这个实验,我们禁用了一致性复制,从而将客户端请求中的数据写入单个节点。

我们在单个数据中心的10节点集群上执行了实验1。图1显示了我们获得的主要结果。图1中的图表描绘了与时钟误差重叠的每种一致性模式在服务器上测量的任意时间段的延迟。延迟时间是移动平均值,每个数据点表示自上一个数据点以来的平均延迟(以微秒为单位)。no consistency、HybridTime consistency这两种模式的平均延迟在100微妙(0.1毫秒)以内,Commit-Wait consistenc则在25000微妙(25毫秒)以上。
图3中的图表描绘了在YCSB客户端上测量的50%、75%、90%、99%和99.9%的延迟直方图。no consistency、HybridTime consistency 99%的请求都能在2毫秒返回。而Commit-Wait consistenc 99%的请求在30毫秒内返回。
一个重要的结论是HybridTime的一致性对延迟几乎没有影响。尽管是预期的,但这表明,正如所声称的那样,通过简单地要求客户端传播单个时间戳,就可以通过混合时间获得Commit-Wait相同的一致性好处。这两个图表的另一个好处是,撇开持久性和复制性,时钟错误对Commit-Wait一致性的总延迟有非常大的影响。Commit-Wait一致性请求比非Commit-Wait请求慢2个数量级(没有fsync和replication),最大的时钟误差是我们能够从传统的NTP设置中提取出来的,尽管稍微做了一些调整。正如预期的那样,Commit-Wait请求的延迟与时钟误差密切相关,并随时钟误差的变化而增减。这可以作为以下实验的基线。
另一个非常重要的结论是,虽然我们能够从NTP获得的最大时钟误差值高于TrueTime和Spanner的最大时钟误差值(11-15毫秒vs.5-7毫秒),但它们并不高很多,通常是2-2.5倍。虽然两倍的时间是重要的,我们注意到,我们使用公共服务器来同步时间主机,而时间主机本身的最大错误是6-9毫秒。我们认为,这意味着,使用commit-wait的设置与典型的NTP协议一起使用,同时保持延迟时间接近Spanner中的延迟时间,这不仅是合理的,而且是可能的,例如,对于具有公共、良好时间源的足够近的数据中心。
5.4 实验2:Single datacenter with consensus
对于实验2,我们评估了启用了持久性和一致性复制的请求延迟。我们的目标是通过这个实验回答两个问题:i)在启用复制和持久性的情况下,commit-wait一致性模式在整个request time中所占的时间百分比;ii)在某些情况下,是否HyBridTime一致性成为首选选项。
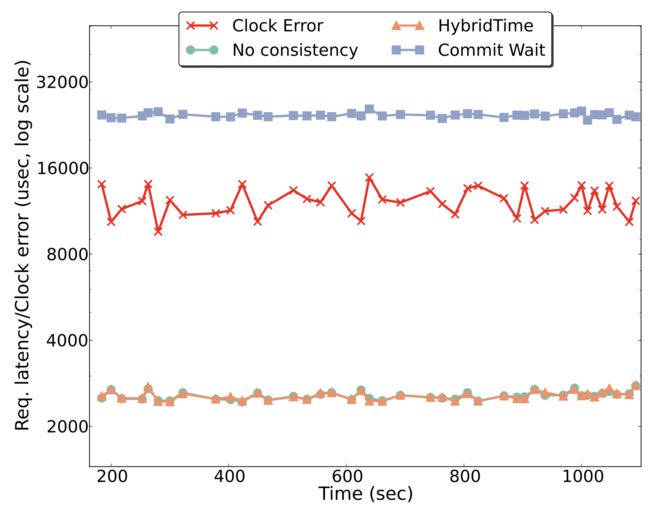
图2中的图表再次描绘了与时钟误差重叠的每个一致性模式在任意时间段内的延迟。在图2中可以看到,即使启用了持久性和复制,HyBridTime一致性请求完成所需的时间(2.5ms)比commit-wait请求(30ms)少一个数量级。事实上,HybridTime请求完成所需的时间是Spanner论文中报告的单个副本组写入所需时间的5倍左右,这使得HybridTime成为延迟敏感场景中的一个可能选择,即使TrueTime之类的精确时钟也是可能的。
图2显示,即使有一个完整的数据库堆栈,commit-wait一致性请求的许多时间仍要花费在等待时钟误差。也就是说,即使是将数据传输到其他节点(在应答之前必须调用fsync())和本地WAL,99.9%的请求花费86%的时间等待时钟误差。我们不直接将等待时间与Spanner上公布的数字进行比较,因为它们是单副本、无提交等待的,请求时间比我们的数据库原型开启了一致性副本的时间还要高。我们推测这可能是由于在Spanner中实现的其他功能尚未发布,或者我们的研究原型还不支持,比如多分区写入事务。
5.5 实验3:Two datacenters
对于实验3,我们将我们的原型数据库部署到两个不同的数据中心,并让每个数据中心的客户端写入所有分区。这个实验的目的是为了证明,和Spanner的commit-wait一样,HybridTime也可以在geo-distributed集群上工作,并且YCSB客户端的吞吐量对于HybridTime一致性比commit-wait一致性要高得多。
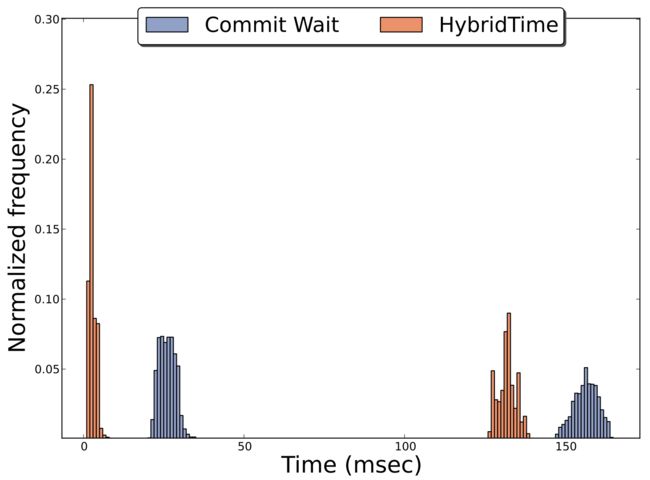
图3显示了实验3的延迟数据正态直方图。这个实验的一个重要结论是,HybridTime不仅显示出较低的延迟值,而且这些值也更稳定,例如,在YSCB中,25%的请求属于同一个bin。这是有意义的,因为commit-wait延迟随时钟误差而变化,而HybridTime延迟仅取决于服务器实现,这表明当延迟需要遵循严格的sla时,HybridTime可能是更好的选择。
在整个实验评估过程中,我们没有关注吞吐量,因为吞吐量高度依赖于服务器和客户端的数量,但是值得一提的是,使用HybridTime一致性的单个YSCB客户端的吞吐量大约是使用commit-wait一致性的客户端的20倍。
6. 结论
本文介绍了一种新的全局一致性算法:HybridTime,该算法基于NTP的时间同步之上进行实现,相较于Spanner的commit-wait,延迟低了一个数量级。HybridTime为全局分布式数据库的事务提供了happend-before排序特性及误差边界,同时提供了物理上有意义的时间戳,以支持point-in-time查询。我们还演示了如何在广泛使用的NTP协议之上实现commit-wait一致性,虽然相较于Spanner延迟更差,但在同一数量级内。此外,我们还展示了HybridTime和commit wait可以共存于同一个系统中,以便用户可以根据需要自由选择。如果可能存在隐藏通道,那么commit-wait是更好的选择,也是唯一一个确保全局一致性的方法,代价是响应客户端请求的速度慢1个数量级。另一方面,如果系统是封闭的,并且没有隐藏的通道,那么HybridTime可以提供整个集群的一致性,即使对于地理分布的集群也是如此,且延迟要低得多。
附录A - HybridTime时间戳分配的误差有界性证明
证明:设e为在节点i发生事件f之前发生在节点j的事件,其时间戳随消息一起传输并用于调用HTC.Update(). 假设e的物理时间戳组件高于PCi(f),使得算法2中第24行中的测试通过,使得最后一个物理时间戳的值被更新为e的物理时间戳组件的值,并且随后被分配为fs物理时间戳。
如果e的时间戳是从物理时钟(PCj(e))获得的,那么,由于假设1,e发生的real时间必须在以下时间间隔内:
t_real_e ∈ [PCj(e)−Ej(e),PCj(e) +Ej(e)] ---- (5)
我们也知道,f发生的real时间是在如下区间内:
t_real_f ∈ [PCi(f)−Ei(f),PCi(f) +Ei(f)] ---- (6)
我们知道,e和f发生的顺序如为:e → f,因此e和f的real时间之间的关系如下:
t_real_f > t_real_e ---- (7)
由于e → f,从(5)和(7)我们可以断言t_real_f必须发生在e的最早可能值之后,即:
PCj(e)−Ej(e) < t_real_f ---- (8)
在区间的右侧,我们可以断言t_real_f一定发生在PCi(f)+Ei(f)之前,即:
t_real_f ≤ PCi(f) +Ei(f) ---- (9)
将(8)和(9)结合在一起,我们得到:
PCj(e)−Ej(e) < t_real_f ≤ PCi(f) +Ei(f) ---- (10)
如果我们从(10)的不等式中减去分配给f时间戳物理分量的值PCj(e),我们得到:
−Ej(e) < t_real_f −PCj(e) ≤ PCi(f)−PCj(e) +Ei(f) ---- (11)
由于我们选择了PCi(e)作为f的物理时间戳,即(HTCi(f).physical=HTCj(e).physical)∧(HTC(e).physical=PCi(e)),我们从算法2知道:
PCi(f) < PCj(e) ---- (12)
从(12)我们知道PCi(f)−PCj(e)<0,HTCi(f).physical=PCj(e),我们之前将error(f)定义为t_real_f−HTCi(f),因此(11)变为:
−Ej(e) < error(f) < Ei(f) ---- (13)
也就是说在时间戳分配时,将PCi(e)作为f的时间戳的物理部分引起的绝对误差为:
error(f) ∈ (−Ej(e),Ei(f)) ---- (14)
参考
[1] HBase. https://hbase.apache.org/.
[2] ALMEIDA, S., LEITAO˜ , J., AND RODRIGUES, L. ChainReaction: a causal+ consistent datastore based on chain replication.the 8th ACM European Conference (Apr. 2013), 85–98.
[3] BERNSTEIN, P. A., AND GOODMAN, N. Concurrency Control in Distributed Database Systems. ACM Comput. Surv. 13, 2 (June 1981), 185–221.
[4] CHANG, F., DEAN, J., GHEMAWAT, S., HSIEH, W., AND WALLACH, D. Bigtable: A distributed storage system for structured data. Proceedings of the 7th USENIX Symposium on Operating Systems Research (Jan. 2006).
[5] COOPER, B., RAMAKRISHNAN, R., SRIVASTAVA, U., SILBERSTEIN, A., JACOBSEN, H.-A., PUZ, N., WEAVER, D., AND YERNENI, R. PNUTS: Yahoo!’s hosted data serving platform. Proceedings of the VLDB Endowment 1, 2 (Aug. 2008).
[6] COOPER, B. F., SILBERSTEIN, A., TAM, E., RAMAKRISHNAN, R., AND SEARS, R. Benchmarking cloud serving systems with YCSB. the 1st ACM symposium (June 2010), 143–154.
[7] CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google’s Globally Distributed Database. Transactions on Computer Systems (TOCS 31, 3 (Aug. 2013).
[8] DAVIS, J. IBM/DB2 Universal Database: Building Extensible, Scalable Business Solutions., 1999.
[9] DECANDIA, G., HASTORUN, D., JAMPANI, M., KAKULAPATI, G., LAKSHMAN, A., PILCHIN, A., SIVASUBRAMANIAN, S., VOSSHALL, P., AND VOGELS, W. Dynamo: amazon’s highly available key-value store. SOSP ’07: Proceedings of twenty-first ACM SIGOPS symposium on Operating systems principles (Oct. 2007).
[10] FIDGE, C. J. Timestamps in message-passing systems that preserve the partial ordering. In Proceeding of the th Australian Computer Science Communication (1988).
[11] HERLIHY, M. P., AND WING, J. M. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems (TOPLAS) 12, 3 (July 1990), 463–492.
[12] KEITH MARZULLO, K. M. Consistent global states of distributed systems: Fundamental concepts and mechanisms. Distributed Systems (1993).
[13] LAKSHMAN, A., AND MALIK, P. Cassandra: a decentralized structured storage system. ACM SIGOPS Operating Systems Review 44, 2 (Jan. 4), 35–40.
[14] LAMB, A., FULLER, M., VARADARAJAN, R., TRAN, N., VANDIVER, B., DOSHI, L., AND BEAR, C. The vertica analytic database: C-store 7 years later. In Proceedings of the VLDB Endowment (Aug. 2012), VLDB Endowment.
[15] LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM 21, 7 (July 1978).
[16] LAMPORT, L. Paxos made simple. ACM SIGACT News (2001).
[17] LEE, J. W., LOAIZA, J., STEWART, M. J., HU, W.-M., AND WILLIAM H BRIDGE, J. Flashback database.
[18] LLOYD, W., FREEDMAN, M. J., KAMINSKY, M., AND ANDERSEN, D. G. Don’t settle for eventual: scalable causal consistency for wide-area storage with COPS. SIGMOD ’05: Proceedings of the 2005 ACM SIGMOD international conference on Management of data (Oct. 2011), 401–416.
[19] LOMET, D., BARGA, R., MOKBEL, M. F., SHEGALOV, G., WANG, R., AND ZHU, Y. Immortal DB: transaction time support for SQL server. In SIGMOD ’05: Proceedings of the 2005 ACM SIGMOD international conference on Management of data (June 2005), ACM, pp. 939–941.
[20] MATTERN, F. Virtual Time and Global States of Distributed Systems. Parallel and Distributed Algorithms (1989).
[21] MILLS, D. L. Network Time Protocol (NTP). Network (1985).
[22] PENG, D., AND DABEK, F. Large-scale incremental processing using distributed transactions and notifications. In OSDI’10:Proceedings of the 9th USENIX conference on Operating systems design and implementation (Oct. 2010), USENIX Association.
[23] RAO, J., SHEKITA, E. J., AND TATA, S. Using Paxos to build a scalable, consistent, and highly available datastore. In Proceedings of the VLDB Endowment (Jan. 2011), VLDB Endowment.
[24] STOLLER, S. D. Detecting global predicates in distributed systems with clocks. Distributed Computing 13, 2 (2000), 85–98.
[25] STONEBRAKER, M., ABADI, D. J., BATKIN, A., CHEN, X., CHERNIACK, M., FERREIRA, M., LAU, E., LIN, A., MADDEN, S., O’NEIL, E., O’NEIL, P., RASIN, A., TRAN, N., AND ZDONIK, S. C-store: a column-oriented DBMS. VLDB Endowment, Aug. 2005.
[26] WEI, Z., PIERRE, G., AND CHI, C.-H. CloudTPS: Scalable Transactions for Web Applications in the Cloud. Services Computing, IEEE Transactions on 5, 4 (2012), 525–539.
[27] ZHANG, C., AND DE STERCK, H. HBaseSI: Multi-row Distributed Transactions with Global Strong Snapshot Isolation on Clouds. Scalable Computing: Practice and Experience 12, 2 (Jan. 2011).
MemFireDB,带你体验不一样的云端飞翔。