【多线程】JUC的常见类

1. Callable 接口
首先先来认识下什么是 JUC,JUC 全称为 java.util.concurrent,这个包里面放了并发编程(多线程相关的组件)
Callable 接口类似于 Runnable 一样,Runnable 用来描述一个任务,而 Callable 也是用来描述一个任务的。
但是他俩有一个本质的区别,Callable 描述的任务是有返回值的!Runnable 描述的任务并没有返回值!
现在我们就简单的使用下 Callable:
public static void main(String[] args) {
Callable callable = new Callable() {
@Override
public Integer call() throws Exception {
System.out.println("hello world");
return 100;
}
};
} Callable
此时我们把任务描述出来了,也就是说,这个任务要打印 "hello wrold",并且返回 100。
由于我们这里仅仅是描述任务,但任务是要让线程去执行的,此时我们还需要用 Thread 类去创建一个线程出来:
Thread t = new Thread(callable); // error当我这样尝试发现,居然报错了,其实是不能直接像 Runnable 一样传递进去,而是需要套上一层其他的辅助类:FutureTask
FutureTask futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask); 这样就解决了,通过 t.start() 启动线程,然后就可以通过 futureTask.get() 获取返回值了:
public static void main(String[] args) {
Callable callable = new Callable() {
@Override
public Integer call() throws Exception {
System.out.println("hello world");
return 100;
}
};
FutureTask futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
try {
Integer result = futureTask.get(); // 获取任务的返回值
System.out.println(result);
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
} 总结:
Callable和Runnable 相对,都是描述一个任务,Callable描述的是带有返回值的任务,Runnable 描述的是不带有返回值的任务
Callable通常需要搭配FutureTask 来使用,FutureTask 用来保存Callable的返回结果,因为Callbale往往是在另一个线程中执行的,啥时候执行完,是不确定的
FutureTask 就可以负责这个等待结果出来的工作
FutureTask就好比你去吃麻辣烫,当餐点好了,后厨就开始做了,同时前台会给你一张小票,这个小票就是FutureTask,后面就可以凭这张小票去查看这份麻辣烫好了没(查询Callable任务的返回值)
2. ReentrantLock 可重入锁
2.1 认识 ReentrantLock
从里面意思理解就是可重入锁,这里的 ReentrantLock 是标准库给我们提供的另一种锁,也是可重入的。
这里思考一个问题,为什么有了 synchronized 还提供了 ReentrantLock 呢?
synchronized 是直接基于代码块的方式来加锁解锁的。
ReentrantLock 更传统,使用 lock 和 unlock 方法进行加锁和解锁。
比如:
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
reentrantLock.lock(); // 加锁
// 中间的代码.....
reentrantLock.unlock(); // 解锁
}这样的写法,就导致可能执行不到解锁了,为什么呢?因为假设中间的逻辑太复杂了,是有可能执行不到 unlock了,就像 C++ 中,new 了对象,但忘记释放了!
如果是下述的情况呢?
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
reentrantLock.lock();
if (cond1) {
// code...
reentrantLock.unlock();
return;
}
if (cond2) {
// code...
reentrantLock.unlock();
return;
}
reentrantLock.unlock();
}这里我们每次进入一个分支都要解锁,这样写代码不够优雅,太麻烦了,所以我们建议把 unlock 放到 finllay 中,因为 finllay 中的代码都会执行。
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
reentrantLock.lock();
try {
if (cond1) {
// code...
reentrantLock.unlock();
return;
}
if (cond2) {
// code...
reentrantLock.unlock();
return;
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
reentrantLock.unlock();
}
}看到这啊,可能大家发现,这咋都是 ReentrantLock 的劣势呢?怎么相比于 synchronized 一点优势都没有了。
下面我们就来看看 ReentrantLock 的优势在哪。
2.2 ReentrantLock 的优势
-
ReentrantLock 提供了公平锁版本的实现,也就是基于"先来后到"的公平策略
ReentrantLock reentrantLock = new ReentrantLock(true);构造方法中传入 true 表示是公平锁,false 表示非公平锁,默认是非公平锁!
-
ReentrantLock 不会"死等"
对于 synchronized 来说,如果没有获取到锁,就会一直阻塞等待!
而 ReentrantLock 则提供了更灵活的等待方式,这里我们主要认识两个方法:
tryLock(); 这个无参版本表示只要获取不到锁,就放弃,并且返回false
tryLock(timeout, unit); 这个带参版本表示最长等待时间,unit 是等待的时间单位,可以是分,秒...
看一段代码:
public class Test {
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
Thread t1 = new Thread(() -> {
reentrantLock.lock();
System.out.println("t1 获取到锁了!");
try {
Thread.sleep(100_000); // 获取到锁休眠100秒
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
reentrantLock.unlock();
}
});
t1.start();
Thread t2 = new Thread(() -> {
boolean flag = false;
try {
flag = reentrantLock.tryLock(10, TimeUnit.SECONDS); // 最多等待10秒
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
if (flag) {
// 加锁成功执行的逻辑...
System.out.println("t2 加锁成功!");
reentrantLock.unlock();
} else {
// 加锁失败执行的逻辑...
System.out.println("t2 加锁失败!");
}
});
t2.start();
}
}上述代码显然是t1会先获取到锁,t1的任务是获取到锁后,阻塞等待100s,显然此时t2线程是无法获取到锁的,如果 t2 10s还未获取到锁,就会执行加锁失败的逻辑,上述代码也就是会打印加锁失败! !!
有了这一点,我们程序猿就能很好的控制,加锁成功和失败需要执行的不同逻辑!
-
ReentrantLock 提供了一个更强大,更方便的等待通知机制
synchronized 搭配的是 wait notify,而 notify 的时候是随机唤醒一个等待的线程。
ReentrantLock 搭配的是 Condition 类,唤醒的时候可以唤醒指定线程(感兴趣可以下去自行学习)。
结论:虽然ReentrantLock有一定的优势,但是实际开发中,大部分情况下还是使用的 synchronized,毕竟写法上synchronized还是简单一点
注意:如果我们执行reentrantLock.lock() 和 synchronized(reentrantLock), 此时是针对同一个对象加锁吗?
synchronized和 ReentrantLock是无法针对同一个对象加锁的!
因为synchronized是针对()里的对象,本质上是操作对象的"对象头”里的特殊的数据结构,这个部分是JVM内部C++代码实现的。
而ReentrantLock 的锁对象就是你定义的RenntrantLock 实例,此时都是在Java代码层面上进行的锁对象的控制。
3. Semaphroe 信号量
3.1 认识信号量
此处我们谈到的信号量是 Java 把操作系统原生的信号量封装了一下。
如何理解信号量这个概念呢?举个例子:
停车场只有 100 个车位,就表示有 100 个可用资源,此时停车场进入了一辆车,就减少一个车位可用了,剩余 99 个可用车位了。
如果出去了一辆车,就增加 1 个车位,剩余 100 个可用车位。
如果可用车位为 0 了,还尝试开车进去停车的话,就没有车位可用了,就会在外面阻塞等待!
信号量 Semaphroe 本质上就是一个计数器,描述了可用资源个数!
主要涉及到两个操作:
-
P 操作:申请一个资源,计数器就要 -1
-
V 操作:释放一个资源,计数器就要 +1
P 操作时,如果计数器为0,那么就会阻塞等待,V 操作时,如果计数器满了(有上限),那么也会阻塞等待。
3.2 信号量与锁
这里我们考虑一个计数器初始值为 1 的信号量,所以这个信号量的值就只有 1 和 0 的范围(信号量不能为负数)
针对这样的信号量,执行一次 P 操作, 1 -> 0,执行一次 V 操作,0 -> 1
如果已经执行了一次 P 操作,继续执行 P 操作就会阻塞等待...
奇怪,这里是不是有点似曾相识,有点像锁!
锁其实就可以视为计数器为 1 的信号量,也叫做二元信号量,锁是信号量的一种特殊情况,信号量是锁的一般表达。
现在我们就来简单的看一下 Java 给我们提供的信号量:
public class Test {
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(1);
semaphore.acquire();
semaphore.release();
}
}在英文中,一般 P 操作使用 acquire 表示申请,V 操作使用 release 表示释放。
在实际开发中,锁虽然是常用的,但是信号量偶尔也会用得到,主要还是要看当前需求。
比如图书馆有一本书《Java》,这本书一共有10本,那么就可以使用一个初始值为10的信号量来表示每次有同学借书,就是Р操作,每次有同学还书,就是V操作,如果计数器已经为0了,还有同学想借书的话,就只能等了......
4. CountDownLatch
CountDownLatch这里简单了解即可,用的不是特别多
这个就类似于100米短跑,当裁判一声令下,运动员开始跑步,开始的时间是知道的,但是什么时候结束这场比赛?等所有人都冲过了终点线即结束了比赛,所以为了等待跑步比赛结束,就引入了这个CountDownLatch
主要是两个方法:
-
await ->全部等待-→>开始,等待比赛结束
-
ountDown表示选手冲过了重点线
在使用CountDownLatch构造的时候,指定一个计数(选手个数)
例如指定四个选手进行比赛
初始情况下,调用await 就会阻塞
每个选手都冲过终点->当有线程完成了自己的任务都会调用countDown方法
前三次调用countDown方法,await没有任何影响
第四次调用(最后一名冲线)countDown方法,await就会被唤醒,解除阻塞,此时就可以认为是整个比赛都结束了
5. 多线程环境使用集合类
5.1 多线程使用ArrayList
关于 ArrayList 的底层原理我们就不介绍了,当前主要了解如何在多线程环境下使用 ArrayList 类
接下来就介绍常用的几种方法:
-
加锁,使用 synchronized 或者 ReentrantLock(常见)
-
使用 Collections.synchronizedList(),这里会提供一些对 ArrayList 相关的方法,同时都是带锁了,说白了这个方法就是把集合类给套一层了。
-
使用 CopyOnWriteArrayList 这个类。
这里我们主要了解下 CopyOnWriteArrayList,这个类简称 CWO,也叫做 "写时拷贝"。
如果针对 ArrayList 进行读操作,则不做任何额外工作,如果进行写操作,则拷贝一份新的 ArrayList,针对新的 ArrayList 进行插入元素,插入完成后,再将原引用指向新的 ArrayList。
所以 CopyOnWriteArrayList 也是一种读写分离的思想。
优点:在读操作很多,写操作很少的情况,性能很高,不需要加锁。
缺点:占用内存较多,新写的数据不能第一时间被读到。
5.2 多线程使用 HashMap (重点)
HashMap 是线程不安全的,但是 Java 也提供了一个线程安全的 HashMap 叫做 HashTable。
HashTable 是线程安全的,给关键的方法加了 synchronized。
但是我们不推荐使用 HashTable,因为有更好的方案,ConcurrentHashMap,这是更优化的线程安全的 HashMap!
那么面试官会经常问:ConcurrentHashMap 进行了哪些优化?比 HashTable 好在哪里?和 HashTable 之间的区别在哪?
现在我们就来讨论他俩的区别:
HashTable的做法是直接在方法上加synchronized,等于是给this 加锁,只要操作哈希表上的任意元素,都会产生加锁,也就都能会发生锁冲突
但是实际上根据哈希表的结构特点,在有些元素上进行并发操作时,是不会触发线程安全的问题的!也就是不需要使用锁控制! ! !

情况1∶我们发现,如果线程t1修改元素A, t2修改元素B,是可能会出现线程安全问题! ! !
(修改:增加,删除,修改,都可能会操作节点的next指针域),那么这种情况是需要加锁的! !
情况2∶如果是线程t1修改元素C,t2修改元素D,这样是否会有线程安全问题呢?这样显然是没有的!这就相当于多个线程修改不同的变量,上图也就是多个线程修改不同的链表! !!这种情况不需要加锁
而 HashTable 保证线程安全的方案会导致锁冲突的概率太大了,任意两个元素的操作都会有锁竞争,即使在不同的链表上操作,也会产生锁竞争,这就是没必要的加锁,也是我们不使用 HashTable 的主要原因!
-
ConcurrentHashMap 的做法是每个链表都有各自的锁,而不是针对整个 this 对象加锁了。
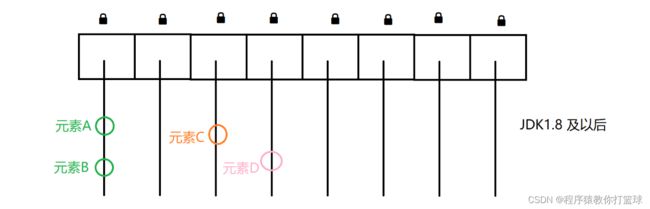
具体来说,是将每个链表的头节点作为锁对象,所以这样一来,操作不同链表里的元素,是不会发生锁竞争的。
此时也是相当于把锁的粒度变小了,像上述两个线程分别操作 元素A 和 元素B 是会发生锁竞争的,但是操作 元素C 和 元素D 就不会发生锁竞争了!
那么这种解决方案是 JDK 1.8 及以后的解决方案,那么在 JDK 1.7 及之前却不是这样的:

这里就是几个链表共用一个锁对象,本质上也是缩小了锁的范围,从而降低锁冲突的概率但是这种做法不够彻底,一方面是锁的粒度切分的不够细,另一方面代码的实现也更为繁琐了。
-
ConcurrentHashMap 还做了一个激进的操作
针对读操作,不加锁,只针对写操作加锁!
那么这里就会出现一个问题,只针对写加锁,也就意味着,读写之间是没有锁冲突的,如果写操作不是原子的,是不是就意味着读到了一个错误的数据呢?
针对这个问题,ConcurrentHashMap 采用了 volatile + 原子写的操作,具体实现我们不深究
-
ConcurrentHashMap内部充分的使用了CAS,通过这个也来进一步的削减加锁操作的数目
比如维护元素个数-> size就使用了CAS操作
-
ConcurrentHashMap针对扩容,采取了"化整为零"的方式
HashMap/HashTable 针对扩容,都是创建一个更大的空间,将原来数组上的链表每个元素都重新 hash 到新的数组对应的链表上(删除+插入),这个扩容操作会在某次 put 的时候进行触发,如果元素个数特别多,这就会导致扩容整体操作比较耗时。
ConcurrentHashMap 则是采取每次搬运一小部分元素的方式,每次扩容创建新数组的时候,旧的数据保留。
每次 put 的时候,都往新数组上添加,同时搬运一部分旧的数据,
每次 get 的时候,旧数组和新数组都会查询,
每次 remove 的时候,直接删除元素即可。
由此一来经过一段时间,所有的元素都搬运好了,最终再释放掉旧的数组。
多线程文章系列【完】