《Linux从练气到飞升》No.16 Linux 进程地址空间
作者: 主页
我的专栏 C语言从0到1 探秘C++ 数据结构从0到1 探秘Linux 菜鸟刷题集 欢迎关注:点赞收藏✍️留言
码字不易,你的点赞收藏❤️关注对我真的很重要,有问题可在评论区提出,感谢阅读!!!
文章目录
-
- 前言
- 程序地址空间回顾
-
- 示例一
- 示例二
-
- 原因:
- 什么是地址空间?
-
- 小故事
- 历史上的地址 VS 现在的地址
- 虚拟地址
-
- 1.什么是虚拟地址?
- 2. 什么是页表?
- 3. 遗留问题
- 4. 当我们的程序编译的时候,形成可执行程序的时候,还没有被加载到内存中的时候,请问我们程序内部有地址吗?
- 5. 程序从编译到执行的过程中,步骤是什么样的?
- 地址空间的概念
- 为什么要有地址空间?
-
- 1. 隔离和保护
- 2. 资源管理
- 3. 内存分布有序化
- 重新理解什么是挂起?
前言
当你在电脑上运行一个程序时,你可能想知道它是如何在内存中存储和管理数据的。有没有一种方法可以使不同的程序在内存中有自己的专属空间,相互之间不会相互干扰呢?
今天,我们将探索一个令人着迷的概念——进程地址空间。进程地址空间是计算机系统中一项至关重要的技术,它为每个正在运行的程序提供了独立的内存空间,用于存储代码、数据和堆栈等信息。
想象一下,当你同时打开多个应用程序,如浏览器、音乐播放器和游戏时,它们能够在内存中各自存在而不相互干扰。这得益于进程地址空间的隔离和管理。通过进程地址空间,不同的程序拥有自己的内存区域,彼此之间不会相互干扰,从而确保了计算环境的稳定性和安全性。
了解进程地址空间的概念将帮助你更好地理解程序的执行过程、内存管理以及如何避免程序之间的相互影响。它在操作系统、编程和软件开发中都有着重要的应用。通过本次学习,我们将揭开进程地址空间的神秘面纱,探索其在计算机系统中的重要性和实际应用。
现在,让我们一起深入了解进程地址空间,探索程序运行背后的奥秘吧!
研究背景:5.14.0-344.el9.x86_64
程序地址空间回顾
示例一
在我们之前学习c语言的时候,老师可能给大家讲过这样的空间布局图。

我们可以看到。命令行参数环境变量高于栈的地址、高于堆的地址、高于未初始化数据的地址、高于初始化数据的地址、高于正文代码的地址。事实是否真的如此呢?
我们来验证一下。
测试代码如下:
#include 结果如下:

我们还能看到栈向下增长,所以后面的变量地址就越小,而堆向上增长,后面的变量地址就越大。堆和栈是相对而生的,因为他们之间有相当大的一块空间是共享的。
但是我们知道free是在堆上申请空间的,free时只传入堆起始地址,怎么知道要删除几个字节呢?其实在malloc时会把它的属性数据存起来,包括大小、地址等。
我们还需要了解到。用户空间是0~3GB,内核空间是3GB到4GB。
============================================================================
示例二
这里还要讲述一个例子,一开始有一个进程,后来 fork 成了两个,我们在子进程中修改全局变量的值。我们会发现最后子进程的值和父进程的值不相同,但是地址相同,为什么?怎么可能同一个地址同时读取的时候出现了不同的值呢?
测试代码如下:
#include 测试结果如下:

我们发现,父子进程,输出地址是一致的,但是变量内容不一样!能得出如下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明该地址绝对不是物理地址!
- 在Linux地址下,这种地址叫做
虚拟地址 - 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理
原因:
这里原因也和虚拟地址有关。当我们子进程没有改变父进程的那个全局变量的时候,他们在同一块内存中,但是如果子进程改变了全局变量的值,就会发生写时拷贝,他就到了另一块物理内存上了,但是这两块物理内存所对应的虚拟地址是同一个,也就造成了这样的现象。
在Linux和windows上面验证上面的代码,可能会跑出不一样的结果,我们上面的结论默认只在Linux上有效。
什么是地址空间?
小故事
我们通过一个故事来学习它。
从前有一个大富翁,他有三个孩子。这个大富翁非常富有,拥有很多钱和财产。为了激励他的孩子们,他给每个孩子画了一个大饼。这个大饼代表了10亿美元的财富。每个孩子都认为自己拥有这10亿美元。
大富翁告诉大女儿,她将来会继承家族的产业,成为家族的掌门人。大女儿非常高兴,她开始努力学习,为将来的责任做准备。
大富翁告诉二女儿,她将来会接管他的生意,成为一位成功的商人。二女儿也非常兴奋,她开始学习商业知识,努力提升自己的能力。
大富翁告诉小儿子,他将来会成为街上最亮眼的人。小儿子非常开心,他开始锻炼自己的才艺,努力成为一个出色的表演者。
每个孩子都根据自己拥有10亿美元的想法,制定了自己的计划。大女儿想要投资房地产,二女儿想要扩大生意,小儿子想要在表演领域取得成功。
然而,事实上,这10亿美元只是大富翁给孩子们画的一个饼,他并没有真正给他们这笔钱。但是,每当孩子们向大富翁要钱时,大富翁通常会给他们一些零花钱。因此,每一个人都认为自己是富翁的合法继承人。但是站在上帝视角,我知道他们彼此的存在。我也知道,他们并不是唯一的合法继承人。但是这个老爹给儿子画的饼,我们就叫做地址空间。那么我们现实之中的饼相当于谁呢?他是看得见摸得着的,它叫做物理内存。
我们前面讲述操作系统的时候,讲过先描述再组织,那这里的地址空间就是我们所说的描述,但是他在将来也一定是一种数据结构,要和一个特定的进程关联起来。
历史上的地址 VS 现在的地址
其实在一开始的时候,并没有地址空间这个概念,地址访问的直接就是物理内存,这样的话内存本身是随时可以被读写的,他特别不安全,假如有野指针等问题就很麻烦。
但是现代计算机提出了下面这种方式:

他引入了虚拟地址的概念。将虚拟地址与物理地址映射起来,要访问物理内存就需要先映射,有人可能会说,最终还是会访问物理内存的,万一我的虚拟地址是一个非法地址呢?
不要急,这时候操作系统会禁止映射。就像小时候。你的父母可能会让你把你的压岁钱上交,说存在他那里,怕你弄丢了,等你什么时候要用的时候再给你,但是当你想买玩具的时候,想买很多玩具的时候,你妈觉得那不是必要的,就不会同意,不管你怎么撒泼打滚,是一个道理。
虚拟地址
1.什么是虚拟地址?
其实如硬盘,网卡等外设也有寄存器,我们想把内存的存储空间和外设的寄存器统一编制成当做内存看,但每一个硬件的本身是不同的,所以就需要引入一个虚拟地址空间的东西,它将不同的硬件对应的设备进行编制,所以实际上我们访问的某些硬件是它和虚拟地址就是这样一个关系。
几乎所有的语言,如果他有地址的概念,这个地址一定不是物理地址,而是虚拟地址,一般我们碰不到物理地址,操作系统设计者怕我们误操作导致系统崩溃。
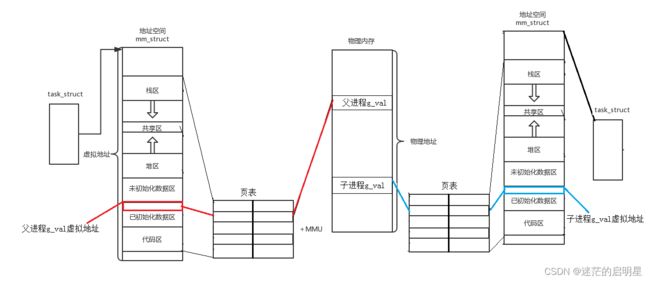
我们看上面的地址空间。它划分有栈区、共享区、堆区、被初始化数据区等区域。但是我们不用看也知道,为了有效管理内存资源、提供程序运行所需的运行环境,并确保不同程序之间的互相隔离和安全性,他肯定会划分成各个区域的。
事实也的确如此,我们看源码:

我们会发现它是有通过start或者end的标记值来划分区域。所谓的区域划分本质就是在一个范围里定义start和end。
所以到现在我们应该知道地址空间,它一定是一种数据结构,而且它里面要有各个区域的划分。我们要知道,每个进程都有他自己的地址空间。该地址空间包含了各种内存区域,如代码段、数据段、堆、栈等。这些区域在进程运行期间可以动态地进行分配和释放。
需要注意的是,不同进程的地址空间可以具有相同的布局,即相同的内存区域类型和相似的地址段,但它们在逻辑上是独立的,相互之间不会干扰或共享内部数据。每个进程都有自己的独立地址空间,使得进程可以在同一台计算机上独立地运行并与其他进程隔离开来。
2. 什么是页表?
页表是处理地址空间和物理内存对应的一种数据结构,是地址空间对象的重要组成部分,用于将进程的虚拟地址映射到物理内存。页表中的每个表项记录了虚拟页和物理页之间的映射关系。当进程访问虚拟地址时,操作系统会根据页表的映射关系将虚拟地址转化为物理地址,从而访问对应的物理内存。
3. 遗留问题
在前面的文章中,我们讲述到fork之后return会被执行两次,它的本质就是对ID进行写入,此时发生了写时拷贝,所以父子进程各自其实在物理内存中有属于自己的变量空间,只不过在我们看到的它是用同一个变量,也就是说,同一个虚拟地址来标识了。
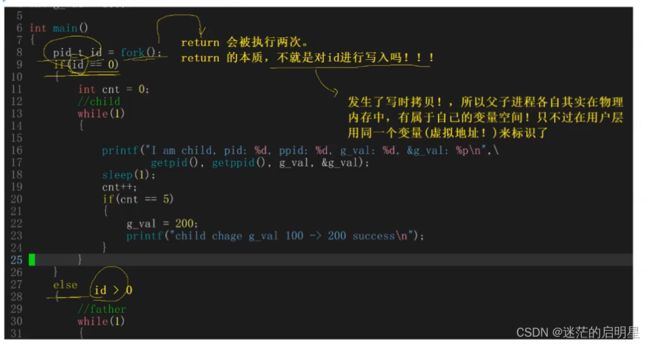
在fork函数中,父进程和子进程都会执行fork函数内部的return语句。这是因为return语句是一条语句,它在执行时会被两个指令分别执行。所以,当fork函数内部的return语句被执行时,它会被父进程和子进程各自执行一次。
这样的执行机制导致了fork函数的返回值有两个,分别是父进程的返回值和子进程的返回值。父进程的返回值是子进程的进程ID,而子进程的返回值是0。
需要注意的是,当执行return语句时,实际上是对ID进行写入操作。尽管这个ID只有一个是属于父进程的,但是当fork成功之后,当执行return语句时,会发生写入操作,写入之后,父进程和子进程都会执行if和else判断。父进程在判断时使用的是自己的ID,而子进程在判断时使用的是自己的ID。这是因为在fork函数内部的return语句执行时,对ID的写入操作发生了写时拷贝,所以父进程和子进程各自拥有自己的ID。
4. 当我们的程序编译的时候,形成可执行程序的时候,还没有被加载到内存中的时候,请问我们程序内部有地址吗?
答案是已经有地址了。地址空间不仅仅理解成为是操作系统要遵守的,其实编译器也要遵守,在编译器编译代码的时候,就已经给我们形成了各个区域代码区,数据区的,并且采用了和Linux内核中一样的编址方式,给每一个变量,每一行代码都进行了编址,故,程序在编译的时候,每一个字段早已经具有了一个虚拟地址。
在编译器的视角里,在一个程序内部的各种地址关系,其实这个地址不叫做虚拟地址,它叫做逻辑地址。只不过在 Linux 下,逻辑地址、线性地址和物理地址其实是一模一样的,因为我们的 Linux 认为所有的那么起始地址全部都是从 0 开始的。
可执行程序在编译阶段就已经具有地址。在编写C或C++代码时,编译器会为每个函数和变量分配对应的地址。这些地址是相对于程序内部的,可以理解为虚拟地址。编译器会根据程序的结构和代码逻辑,为每个函数和变量分配合适的地址。
当程序被加载到内存中时,操作系统会为其分配一块地址空间,这个地址空间是操作系统给进程分配的,也被称为虚拟地址空间。在这个虚拟地址空间中,程序的代码、数据和其他区域会被映射到对应的物理地址上。
因此,可以说在程序编译阶段,程序内部已经具有地址,这些地址是相对于程序内部的虚拟地址。当程序加载到内存后,操作系统会将虚拟地址映射到物理地址上,使得程序可以在内存中正确执行。
5. 程序从编译到执行的过程中,步骤是什么样的?
a. 编译,将每个函数和变量分配对应的地址,这个地址是虚拟地址
b. 加载,程序被加载到内存中,操作系统会为其分配一块地址空间,这个地址空间是操作系统给进程分配的,也被称为虚拟地址空间。程序会把自己编译时分配的虚拟地址与地址空间的虚拟地址相对应,在这个虚拟地址空间中,程序的代码、数据和其他区域会被映射到对应的物理地址上。
c. 运行,task_struct会被加载到CPU中,CPU在运行过程中需要调用哪一个函数,就会通过虚拟地址找到对应的物理地址,然后调用该函数,调用该函数后也会通过页表、地址空间、PCB来返回对应的地址,往复循环。
地址空间的概念
地址空间是操作系统为进程专门设计的一种内核数据结构。它是进程在运行时所使用的虚拟内存空间的抽象表示。在计算机系统中,每个进程都有自己独立的地址空间,用于存储程序的指令、数据和堆栈等信息。
地址空间的定义包括了进程的线性区域的划分,每个区域由起始地址和结束地址来标定。这些区域可以包括代码段、数据段、堆和栈等。每个区域内的地址可以不连续,但在指定的范围内都可以被访问。
地址空间的设计目的是为了提供一种抽象的方式来管理进程的内存使用。它使得每个进程都可以拥有自己独立的地址空间,而不会相互干扰。通过地址空间的映射机制,操作系统可以将进程的虚拟地址转化为物理内存地址,从而避免了进程对内存的直接访问。
总之,地址空间是操作系统为进程提供的一种抽象概念,用于管理进程的内存使用。它定义了进程的虚拟内存空间的划分和映射机制,确保每个进程都可以独立地访问自己的内存空间,保证了进程之间的隔离和安全性。
为什么要有地址空间?
1. 隔离和保护
- 凡是非法的访问或者映射,操作系统都会识别到并终止你这个进程,
- 它可以有效的保护物理内存,因为地址空间和页表是操作系统创建并维护的,
- 也就意味着凡是想使用地址空间和页表进行映射,也一定要在操作系统的监管之下来进行访问,
- 他还保护了物理内存中所有的合法数据,包括各个进程以及内核的相关有效数据。
2. 资源管理
因为有地址空间的存在,也因为有页表的映射的存在,我们的物理内存中,是不是可以对未来的数据进行任意位置的加载?
当然可以,物理内存的分配可以做到和进程的管理没有关系。这样就实现了内存管理模块和进程管理模块的解耦合。
所以我们在C、C++语言上new和malloc空间的时候,本质是在虚拟地址空间上申请的。试想一下,如果我申请了物理空间,但是我不立马使用,是不是就会造成了空间的浪费了?当然会。 而本质上因为有地址空间的存在,上层申请空间其实是在地址空间上申请的,物理内存可以甚至一个字节都不给你,而当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存构建列表映射关系。然后再让你进行内存的访问。而对物理地址空间访问是由操作系统自动完成的,用户包括进程完全灵感知。这样也就是延迟分配的策略,它可以提高整机的效率,它使内存的有效使用几乎为100%。有了地址空间的存在,我们可以以有序化的视角去看待进程的代码和数据在物理内存中的分布情况。这样可以更好地确定代码和数据的起始地址,并且便于操作系统进行统一管理。同时,有序化的内存分布也使得我们能够更好地检测越界访问等问题。
3. 内存分布有序化
因为在物理内存中理论上可以任意位置的加载,那是不是物理内存中的几乎所有的数据和代码在内存中是乱序的呢?
确实如此,因为有页表的存在,它可以将地址空间上的虚拟地址和物理地址进行映射。
他就可以做到说,所有的内存分布有序化。我们知道地址空间是操作系统给进程画的大饼。
进程的独立性可以通过地址空间加页表的方式实现,结合上一条来说,进程要访问的物理内存中的数据和代码,可能目前并没有在物理内存中存在,也可以让不同的进程映射到不同的物理内存,这样就很容易实现了进程的独立性。
因为有地址空间的存在,每一个进程都认为自己拥有4GB空间,并且各个区域是有序的。进而可以通过列表映射到不同的区域来实现进程的独立性,每一个进程不知道,也不需要知道其他进程的存在。
重新理解什么是挂起?
加载的本质就是创建进程,那么是不是非得立马把所有的程序的代码和数据加载到内存中,并创建内核数据结构,建立映射关系?
不是这样的,在最极端情况下,只有内核结构被创建出来了,是什么情况的,此时,他并没有被调用的时候,就是这种情况,这个状态也就是新建状态,理论上我们是可以实现对程序的分批加载的,既然可以分批加载,当然也可以分批换出。进程的数据和代码被换出了,就叫做挂起了。
页表映射的时候不仅仅映射的是内存,磁盘中的位置也可以映射。
比如说加载一些大型的游戏,如果一次性全部加载,物理内存肯定是不够的,然而我们分批加载,加载了一部分,又换出一部分,如此往复便实现了游戏的加载。还有就是当我们加载游戏时。某个进程可能需要等待其他资源,甚至这个进程短时间不会再被执行了,他此时的状态就是阻塞了,他此时可能就会把物理内存唤出到磁盘中,等待下一次的唤入。