计算机底层知识之CPU
❝Only the disciplined in life are free. 唯自律者得自由
❞
大家好,我是「柒八九」。
想必能看到这篇文章的小朋友,大都是有一定编程能力的「程序媛、程序猿」。无论,你是从事切图的前端工作,还是对数据有一种爱而不得的后端开发。更甚者,是和底层打交道的嵌入式开发人员。无论你平时在工作环节中,对编程语言API做到如何的得心应手,但是在遇到一些比较「底层」的逻辑和知识时。或多或少,有点「捉襟见肘」。
而今天,我们又准备开辟一个新的知识体系 --「计算机底层知识」。老话说的好,「不想当将军的士兵不是好士兵」。但是,在你想成为将军的时候,你需要拥有成为将军的知识储备和能力。这也是我们常说的「未雨绸缪」。
如果你对前端一些前沿技术比较了解的话,像WebAssembly/SWC/Rust(硬放到前端也不是不可以)等。他们内核中,无一不透露出,计算机底层的知识。套用唯心主义的话,「存在即合理」,既然是大势所趋,那么我们为什么不顺势而为呢。
而真正的想了解上述前沿技术,拥有扎实的计算机底层方法论是「必不可少」的。而该系列文章就是为了,帮助大家来夯实基础,为了能够在以后的编程道路中,走的更远。
该系列文章的第一篇文章,我们来讲讲「计算机CPU」的常规知识。
好了,天不早了,干点正事哇。 
你能所学到的知识点
❝❞
- CPU的内部结构 「推荐阅读指数」 ⭐️⭐️⭐️⭐️⭐️
- CPU是寄存器的集合体 「推荐阅读指数」 ⭐️⭐️⭐️⭐️
- 决定程序流程的程序计数器 「推荐阅读指数」 ⭐️⭐️⭐️⭐️⭐️
- 条件分支和循环机制 「推荐阅读指数」 ⭐️⭐️⭐️⭐️⭐️
- 函数的调用机制 「推荐阅读指数」 ⭐️⭐️⭐️⭐️⭐️
- 通过地址和索引实现数组
CPU的内部结构
❝CPU是中央处理器 Central Processing Unit的缩写,相当于计算机的大脑,它的内部由数百万至数亿个「晶体管」构成。
❞
在「程序运行流程」中,CPU所负责的就是「解释和运行」最终转换成「机器语言」的程序内容。
 程序运行流程
程序运行流程
CPU和内存是由许多晶体管组成的「电子部件」,通常成为集成电路 Integrated Circuit。
❝从功能方面来看,
❞CPU的内部是由「寄存器」、「控制器」、「运算器」、「时钟」等四个部分组成,各个部分之间由「电流信号」相互连通。
 CPU的四个组成部分
CPU的四个组成部分
- 「寄存器」
- 用来 「缓存」指令、数据等处理对象,可以将其看作是 「内存的一种」
- 根据种类的不同,一个
CPU内部户有20~100个寄存器
- 「控制器」
- 负责把 「内存」上的指令、数据等读入 「寄存器」
- 并根据指令的执行结果来 「控制」整个计算机
- 「运算器」
- 负责运算 「从内存读入寄存器的数据」
- 「时钟」
- 负责发出
CPU开始计时的 「时钟信号」
- 负责发出
内存
❝通常所说的「内存」指的是计算机的主要存储器 Main Memory,简称「主存」。
❞
主存通过「控制芯片」等与CPU相连,主要负责「存储指令和数据」。主存由「可读写」的元素构成,每个字节(1字节=8位)都带有一个「地址编号」。CPU可以通过该地址「读取」主存中的指令和数据,当然也可以「写入」数据。
程序运行机制
程序启动后,根据「时钟信号」,「控制器」会从「内存」中读取指令和数据。通过对这些指令加以解释和运行,「运算器」就会对数据进行运算,「控制器」根据该运算结果来控制计算机。
CPU是寄存器的集合体
CPU的四个构成部分中,我们只需要了解寄存器即可。这是因为,「程序是把寄存器作为对象来描述的」。
假设,我们存在如下用汇编语言编写的代码。
❝「汇编语言」采用助记符 Memonic来编写程序,每一个原本是「电气信号」的「机器语言指令」都有有一个与其「相对应的助记符」。
❞
助记符通常为指令功能的英语单词的缩写。
 汇编代码
汇编代码
例如,mov和add分别是数据的存储和相加的简写。
❝「汇编语言和机器语言基本上是一一对应的」
❞
- 通常我们将 「汇编语言」编写的程序转化成 「机器语言」的过程称为 「汇编」
- 反之, 「机器语言」程序转化成 「汇编语言」的程序的过程称为 「反汇编」
从上述的「汇编代码」中,我们可以看出,「机器语言级别的程序是通过寄存器来处理的」,也就是说,「CPU是寄存器的集合体」。eax和ebp表示的都是寄存器。并且,内存的存储场所「通过地址编号来区分」,而寄存器的种类「通过名字来区分」。
CPU处理程序的大致过程如下:
❝使用「高级语言」编写的程序会在「编译」后转化成「机器语言」,然后再通过
❞CPU内部的寄存器来处理。
寄存器的种类
❝不同类型的
❞CPU,其内部寄存器的数量、种类以及寄存器存储的数值范围都是不同的。
不过,根据功能的不同,我们可以将寄存器大致分为「8类」。
 寄存器的主要种类和功能
寄存器的主要种类和功能
可以看出,寄存器中存储的内容既「可以是指令也可以是数据」。其中,数据分为「用于运算的数据」和「表示内存地址的数据」
 CPU是寄存器的集合体
CPU是寄存器的集合体
决定程序流程的程序计数器
只有1行的有用程序是很少见的,机器语言的程序也是如此。接下来,我们看一下程序是如何按照流程运行的。
下图是程序启动后的内存内容的模型。
❝用户发出启动程序的指示后,「操作系统」会把「硬盘」中保存的程序「复制」到「内存」中。
❞
实例中的程序实现的是将123和456两个数值相加,并将结果输出到显示器上。 
前面我们已经介绍过,存储指令和数据的内存,是通过地址来划分的。由于使用机器语言难以清晰地表明各地址存储的内容,因此我们对各地址的存储内容添加注释。实际上,「一个命令和数据通常被存储在多个地址上」,但是为了便于说明,上面的图例中,把指令、数据分配到一个地址中。
大致流程如下:
- 地址
0100是程序运行的开始位置。 - 操作系统把程序从 「硬盘」复制到 「内存」后,会将 「程序计数器」(
CPU寄存器的一种)设定为0100,然后程序便开始运行。 - 「
CPU每执行一个指令,程序计数器的值就会自动加1」 - 然后,
CPU的 「控制器」就会参照程序计数器的数值,从内存中读取命令并执行。
❝程序计数器决定着程序的流程
❞
条件分支和循环机制
程序的流程分为「顺序执行」、「条件分支」和「循环」三种。
- 「顺序执行」是指按照地址内容的顺序执行指令
- 「条件分支」是指根据条件执行任意地址的指令
- 「循环」是指重复执行同一地址的指令
「顺序执行」的情况比较简单,每执行一个指令「程序计数器」的值就「自动加1」.但若程序中存在「条件分支」和「循环」,机器语言的指令就可以将「程序计数器」的值设定为「任意地址」(不是加1)。这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意地址。
条件分支运行流程
 上图表示把内存中存储的数值(示例中是123)的绝对值输出到显示器的程序的内存状态。
上图表示把内存中存储的数值(示例中是123)的绝对值输出到显示器的程序的内存状态。
大致流程如下:
- 程序运行的开始位置是
0100地址 - 随着 「程序计数器」数值的增加
- 当到达
0102地址时,如果 「累加寄存器」的值是 「正数」,则执行 「跳转指令」(jump指令)跳转到0104地址 - 此时,由于 「累加寄存器」的值是
123,为 「正数」,因此0103地址的指令被跳过,程序的流程 「直接」跳转到了0104地址
❝「条件分支」和「循环」中使用的「跳转指令」,会参照当前执行的「运算结果」来判断是否跳转。
❞
前面我们提到过「标志寄存器」。无论当前「累加寄存器」的运算结果是负数、零还是正数,「标志寄存器」都会将其保存。
CPU在进行运算时,「标志寄存器」的数值会根据运算结果「自动设定」。至于是否执行「跳转指令」,则由CPU在参考「标志寄存器」的数值后进行判断。运算结果的正、零、负「三个状态」由「标志寄存器」的三个位表示。
 32位
32位 CPU(寄存器的长度是32位)的标志寄存器的示例
「标志寄存器」的第一个字节位、第二个字节位和第三个字节位的值为1时,表示的运算结果分别为正数、零和负数。
CPU比较机制
假设要比较「累加寄存器」中存储的XXX值和「通用寄存器」中存储的YYY值,执行比较的指令后,CPU的运算装置就会在内部进行XXX-YYY的「减法运行」。
无论减法运算的结果是正数、零还是负数,都会被保存到「标志寄存器」中。
- 结果为 「正」表示
XXX比YYY大 - 结果为 「零」表示
XXX和YYY相等 - 结果为 「负」表示
XXX和YYY小
❝程序中的比较指令,就是在
❞CPU内部做减法运算
函数的调用机制
❝函数调用处理也是通过把「程序计数器」的值设定成函数的存储地址来实现的
❞
和「条件分支」、「循环」的机制不同,因为单纯的跳转指令无法实现函数的调用。
❝函数的调用需要在完成函数内部的处理后,处理流程再返回到函数调用点(「函数调用指令的下一个地址」)
❞

上图的示例为 变量a和b分别代入123和456后,将其赋值给参数来调用MyFunc函数的C语言程序。图中的地址是将C语言编译成机器语言后运行时的地址。由于1行C语言程序在编译后通常会变成多行的机器语言,所以图中的地址是「离散」的。
此外,通过「跳转指令」把「程序计数器」的值设定为0260也可以实现调用MyFunc函数。函数的「调用原点」(0132地址)和「被调用函数」(0260地址)之间的数据传递,可以通过内存或寄存器来实现。
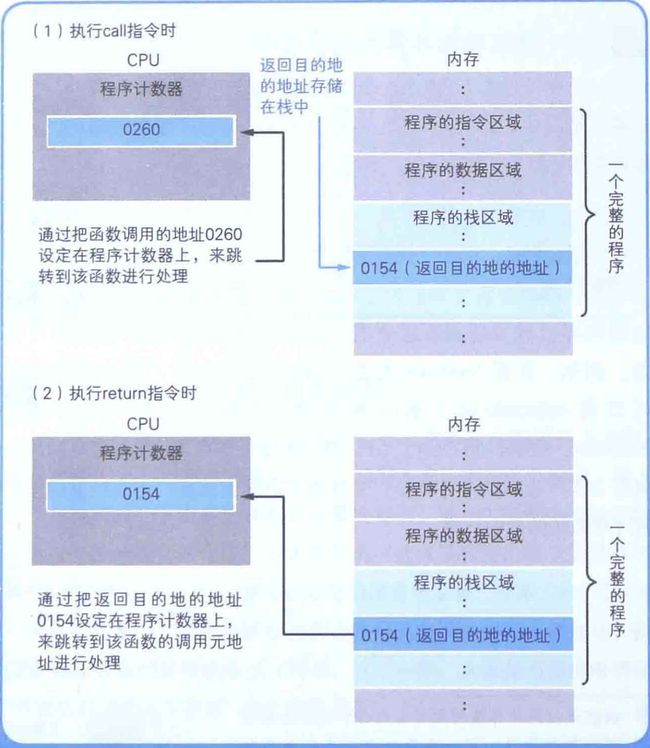
当函数处理进行到最后的0354地址时,我们应该将「程序计数器」的值设定成函数调用后要执行的0154地址。我们通过机器语言的call指令和return指令能实现该功能。
call 指令和return 指令
❝函数调用使用的是
❞call指令,而不是跳转指令。
在将函数的入口地址设定到「程序计数器」之前,「call指令」会把调用函数后要执行的指令地址存储在名为「栈」的内存内。「return 指令」的功能是把保存在栈中的地址设定到「程序计数器」中。
通过地址和索引实现数组
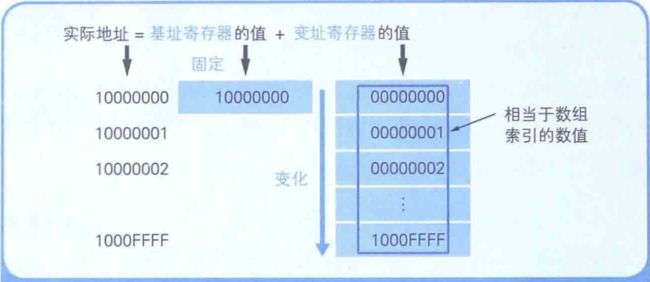
❝通过「基址寄存器」和「变址寄存器」可以对「主内存」上特定的内存区域进行划分,从而实现类似于数组的操作
❞

- 用 「十六进制数」将计算机内存上
00000000~FFFFFFFF的地址划分出来- 凡是该范围的内存区域,只要有一个32位的寄存器,即可查看全部的内存地址
- 如果想要像数组那样分割特定的内存区域以达到连续查看的目的,使用两个寄存器会更方便
❝❞
CPU会把「基址寄存器」+「变址寄存器」的值解释为实际查看的内存地址。
「变址寄存器」的值相当于高级程序语言程序中数组的「索引功能」
后记
「分享是一种态度」。
参考资料:《程序是怎样跑起来的》
「全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。」

本文由 mdnice 多平台发布