ElasticSearch 7.4学习记录(DSL语法)
上文和大家一起初次了解了很多ES相关的基础知识,本文的内容将会是实际企业中所需要的吗,也是我们需要熟练应用的内容。
面对ES,我们最多使用的就是查询,当我负责这个业务时,现不需要我去考虑如何创建索引,添加文档等,只需要根据复杂业务实现查询即可,本文的重点也会在如何使用ES进行查询,并给出很多实际案例进行补充解释和演示
本次案例演示说明所需要的数据-----------student数据信息:
| 属性 | 数值 |
|---|---|
| id | 001 |
| name | zjh |
| address | 中国陕西省延安市 |
| brief | 喜欢足球的男生 |
| age | 28 |
| 属性 | 数值 |
|---|---|
| id | 002 |
| name | wxx |
| address | 中国陕西省渭南市 |
| brief | 喜欢zjh的女生 |
| age | 18 |
- 1 DSL查询语法
-
- 1.1 什么是DSL
- 1.2 查询所有
- 1.3 全文检索
- 1.4 精确查询
- 1.5 复合查询
- 1.6 搜索结果处理
-
- 1.6.1 结果排序+分页查询
- 1.6.2 结果高亮
- 2 DSL语法对应Java代码的实现
-
- 2.1 match_all
- 2.1' 核心代码梳理
- 2.2 match与multi_match
- 2.3 term和range
- 2.4 boolean
- 2.5 排序和分页
- 3 聚合索引
-
- 3.1 初体验聚合效果(buckets聚合案例)
- 3.2 优化聚合效果
- 3.3 Metrics聚合案例
- 3.4 DSL语法对应Java代码的实现
- 3.5 多条件的聚合
- 3.6 理解聚合
1 DSL查询语法
1.1 什么是DSL
就是在这个环境下查询语句,有自己的语法格式要求,需要我们熟练掌握。
或者你可以想一下,在mysql环境下的sql语法,这就是在ES环境下的DSL语法,都是为了实现查询功能。
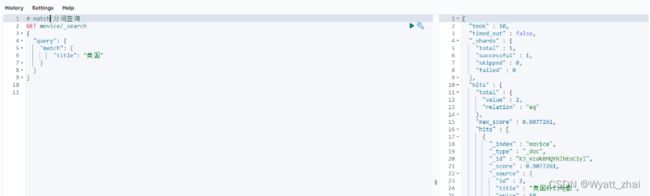
一个简化的查询模版
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"条件值"
}
}
}
查询类型可以实现不同的查询效果,下面的案例很好的解释给了大家。
1.2 查询所有
match_all:查询全部的数据
GET /student/_search
{
"query":{
"match_all":{}
}
}
1.3 全文检索
match查询:利用分词器进行查询,比如:传入“男生”,会将其分词取倒排索引库查询,找到含有“男”与“生”数据,即找到zjh和wxx的全部数据
这是一个模板
GET /student/_search
{
"query":{
"match":{
"field":"text"
}
}
}
实际案例:拆分“男生”去brief字段中查找有无”男“与”生“,最终找到zjh和wxx
GET /student/_search
{
"query":{
"match":{
"biref":"男生"
}
}
}
升级案例:现在不想指定一个字段去查找,想查询所有的字段中的数据是否有匹配的
GET /student/_search
{
"query":{
"match":{
"all":"跑步工资"
}
}
}
这个all就表示会在所有字段id,name,address,brief的值中去匹配”跑步工资“
multi_match查询:允许同时查询多个字段
这是一个模板
GET /student/_search
{
"query":{
"multi_match":{
"query":"text",
"fields":["field1","field2"]
}
}
}
实际案例:找到address含有“延安”且brief含有”喜欢“的数据,最终找到zjh和wxx
GET /student/_search
{
"query":{
"multi_match":{
"query":"延安喜欢",
"fields":["address","brief"]
}
}
}
需要注意的是multi_match设置的字段越多,效率越慢,推荐优先使用match
1.4 精确查询
当查询条件是不可分的:keyword,数值,日期,boolean等,不会对其分词,即为精确查询
- term:根据词条精确值查询
- range:根据值范围查询
案例:
当查询内容传入:上海,就希望匹配到含有“上海”的数据,而不是含有“上”与“海”的这种数据。此乃term
当查询内容传入:100-300元,就希望匹配到在这个范围内的数据。此乃range

这是一个term模板
GET /student/_search
{
"query":{
"term":{
"field":{
“value”:“value”
}
}
}
}
实际案例:找到address含有“男生”的数据,找到空数据,因为必须精准为男生,才能找到zjh
GET /student/_search
{
"query":{
"term":{
"field":{
“brief”:“男生延安”
}
}
}
}
这是一个range模板
GET /student/_search
{
"query":{
"range":{
"field":{
“gte”:“value”,
“lte”:“value”
}
}
}
}
实际案例:找到年龄在10-20之间的人,最终找到wxx
GET /student/_search
{
"query":{
"range":{
"age":{
“gte”:10,
“lte”:20
}
}
}
}
注意:gte是大于等于;gt是大于
1.5 复合查询
Boolean Query
布尔查询是一个或者多个查询字句的组合。组合方式有
- must : 必须匹配每个子查询(与)
- should:选择性匹配子查询(或)
- must_not:必须不匹配(非)不参与算分
- filter:必须匹配 不参与算分
GET /student/_search
{
"query":{
“bool”:{
“must”:[
{"term":{“address”:“中国”} }
{"term":{“name”:“zjh”} }
],
"should":[
{"term":{“brief”:“喜欢”} },
{"term":{“brief”:“足球”} }
],
“must_not”:[
{"range":{“age”:{"gte:20"} } },
],
“filter”:[
{"term":{“brief”:“生”}}
]
}
}
}
这串代码表示:
must:(address必须含有中国) 且 (name必须含有zjh)
should:(brief含有喜欢) 或者 (brief含有足球)二选一
mustnot:(年龄大于等于20)相反-----(年龄小于20)
这个案例仅仅告诉你如何理解must等,下面介绍一个贴切的案例
查询名字包含“麦当劳”,地点在北京,人均消费不高于100元,周一到周天营业的快餐店
1.6 搜索结果处理
1.6.1 结果排序+分页查询
这是一个range模板
GET /student/_search
{
"query":{
“查询类型”:{}
},
"sort":[{"fileld":”value“}]
}
实际案例:全部查询,将结果按照年龄倒序,若相等按照id升序排
GET /student/_search
{
"query":{
"match_all":{}
},
"sort":[{”age“:”desc“},{”id“:”asc“}],
“from”:0,
“size”:10
}
}
}
es查询结果默认只显示10条数据。from:0--------size:10,表示从0开始,显示10条数据
实际上,如我们会将一批数据分成10批,存在10台服务器的ES上。如果我们需要查询价格由低到高排序前100条,底层执行的逻辑是:每一台ES由低到高排序,查出前100,然后聚合10台机器的数据(10*100),从聚合结果1000中再找到前100的数据。
不过呢,当我们执行数据读取时候,一定是会扫描所有的ES节点,不需要担心查询的时候会不会只查询当前服务器上es的数据,是不会的。
1.6.2 结果高亮
浏览器搜索java,可以看到查询结果中含有java部分高亮显示,这是如何实现的?

是ES帮忙做的,我们只需要告诉ES需要高亮显示的字段和内容即可
GET /student/_search
{
"query":{
“match”:{
“all”:“中国”
},
“highlight”:{
“fields”:{ //高亮字段
“address”:{
"requeire.field_match":“false”,//是否需要与查询字段匹配
“pre_tags”:"", //用来标记高亮字段的前置标签,
“post_tags”:“” //用来标记高亮字段的后置标签
}
}
}
}
2 DSL语法对应Java代码的实现
2.1 match_all
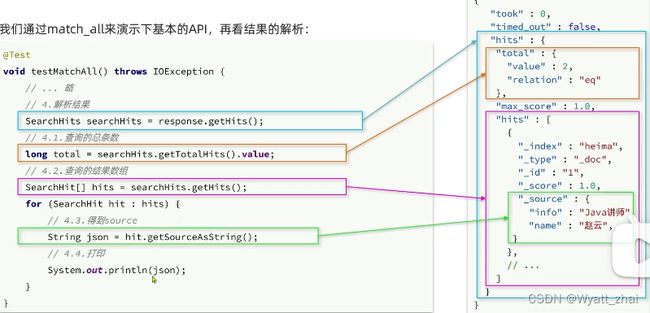
RestHighLevelClient client 注意前面我已经获取了client
关于代码实现,可以理解为四个部分,不同业务需要变动代码的部分只有2,4处
@Test
void testMatchAll() throws IOException {
//1.准备request
SearchRequest request = new SearchRequest("student");
//2.准备DSL
request.source().query(QueryBuilders.matchAllQuery());
//3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析响应中的hits
SearchHits searchHits = response.getHits();
long value = searchHits.getTotalHits().value; //获取value值(参考ES)
System.out.println(value);
SearchHit[] hits = searchHits.getHits(); //获取文档数据
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
System.out.println(json);
}
}
为什么解析response呢,因为其全部内容如下图,我们需要选出需要的即可
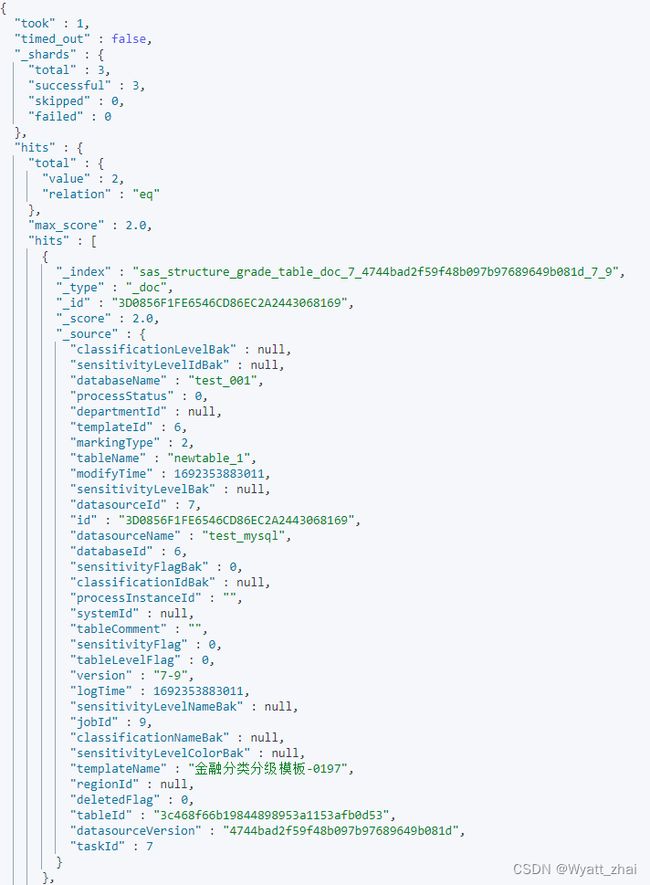
2.1’ 核心代码梳理
这里梳理一下上述java代码的对应关系,帮助理解
source()方法中存在操作类型,有查询query,有结果排序sort,有分页form,size等
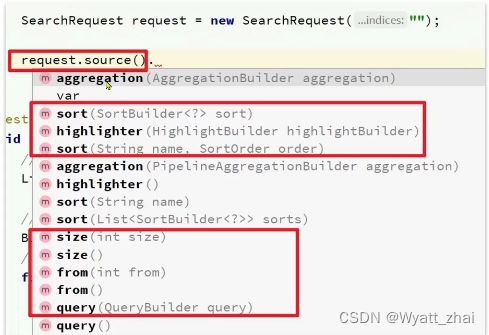
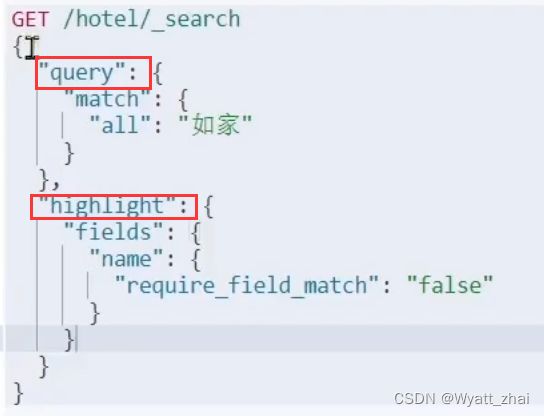
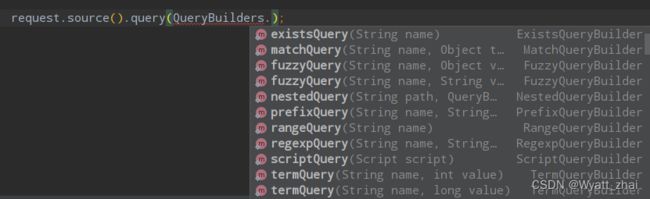
QueryBuilders()里面有查询类型,包括前面科普的精确查询term,全部查询match_all,复合查询bool等
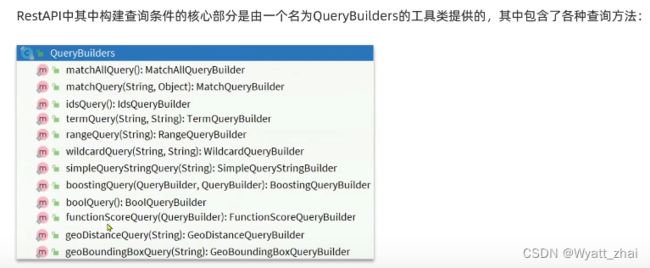
2.2 match与multi_match
2.3 term和range

2.4 boolean

2.5 排序和分页

3 聚合索引
理解什么是聚合索引:类似于group by的概念,下图前两个常用。先看看聚合怎么用,文末会有个案例更清楚的解释聚合的概念

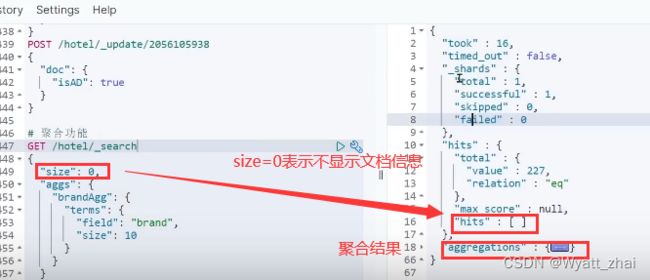
3.1 初体验聚合效果(buckets聚合案例)
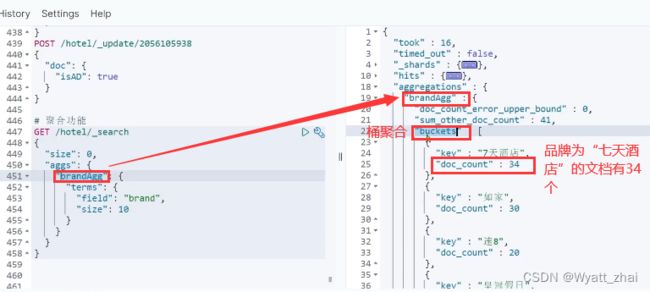
比如我现在需要统计酒店的品牌数量有几种,则可以根据品牌数量进行聚合,就会得到名为“七天酒店” 34家 ;“如家” 30家 ;“速8” 20家的返回结果

3.2 优化聚合效果
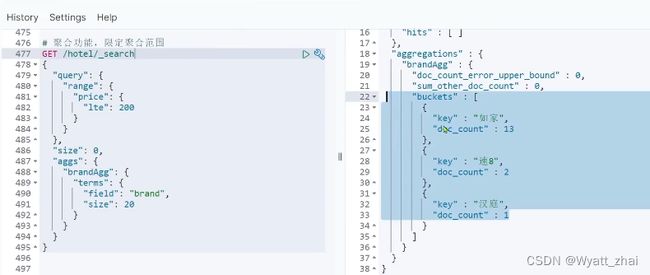
对价格在200元以内的酒店进行聚合,这个案例表示query和aggs是平级。
3.3 Metrics聚合案例

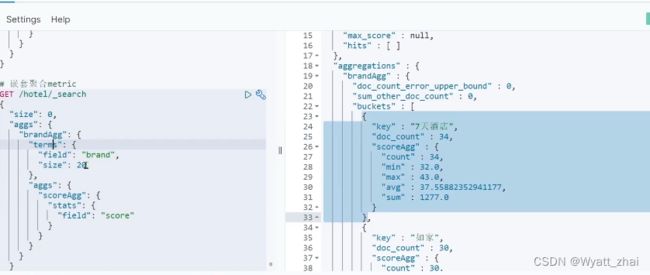
也就是在Buckets聚合上再加了一层,很好记住,(sorce字段是酒店评分)注意观察下图,发现多了count、min、max、avg,sum。什么意思呢,就是说我们对酒店评分进行聚合,得到了最大值,最小值,平均值等等。
3.4 DSL语法对应Java代码的实现
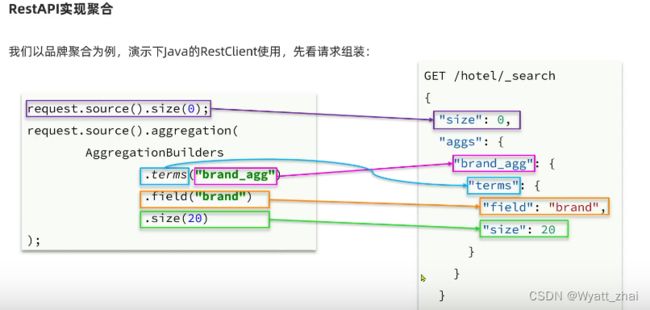

3.5 多条件的聚合
就是同时聚合多个字段:城市、星级、品牌
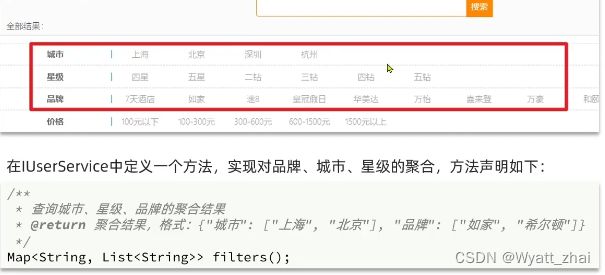
如何理解这个业务
前面提到的精确查询,根据上海就可以查出city字段中含有”上海“的所有文档,但是我们仅仅停留在粗暴的找出信息的阶段,若我需要对上海这一类文档求平均价格,计数等,term的功能就显得捉襟见肘了。所以这里需要聚合处理。理解了业务需求在看看如何实现
1.准备request
2.准备DSL
2.1 多个聚合字段
3.发出请求
4.解析结果
4.1 分别处理聚合名称的数据
2.1内容

4.1内容,有几个集合字段就实现几次

实际上,你只需要清楚一个字段的聚合实现流程,那么当你写多个字段的聚合时,仅仅需要重复2和4的代码,那这些代码你可以封装成函数更优雅。
3.6 理解聚合
现在我们需要搜索城市是上海的数据
直接使用精确查询:找到city字段含有”上海“的文档;(注意理解ES中文档的概念)
聚合city字段:对city字段进行聚合,得到“上海”“北京”“深圳”的聚合结果,注意,只是聚合结果,不是具体的文档数据。此外我可以对聚合结果进行求和,求平均值等操作。