Doris线下沙龙完美收官!本次沙龙邀请了来自百度、美团、京东的技术大牛带来实战分享。了解更多详情请关注Doris官方公众号,嘉宾分享回顾会陆续放出。公众号后台回复“1222”立即get现场录像及嘉宾PPT。
现场视频和嘉宾PPT会在近日放出,欢迎大家关注Apache Doris(incubating) 官方公众号。
本次由来自美团点评的 康凯森 同学带来了 Apache Doris (incubating) 基于 Bitmap的精确去重和用户行为分析 。康凯森是美团点评Doris服务的负责人,同时也是Doris的PPMC&Committer。
基于 Bitmap 的精确去重
A Store about Bitmap Count Distinct
2016年1月份,我当时是美团点评的实习生,主要做HBase这块。当时我的 mentor 孙叶锐,也是Kylin的PMC,在Kylin中实现了 Bitmap 聚合指标,开始只支持Int类型,然后在16年5月份的时候,为了支持任意类型的精确去重,我的 mentor 孙叶锐在Kylin中实现了全局字典。
之后大月和我对全局字典做了一次重构,并在全局字典构建方面做了很多优化,在17年的时候,我对Kylin 精确去重查询做了多次优化,整个精确去重查询性能应该有几十倍的提升,对于无需上卷的精确去重查询,性能提升有上百倍。之后实现了全局字典的MR构建,Segment粒度全局字典等优化。
然后在18年1月份的时候,我整理了 《Apache Kylin 精确去重和全局字典权威指南》(https://blog.bcmeng.com/post/kylin-distinct-count-global-dict.html)一文,对Kylin中的精确去重和全局字典的用法,优化,和原理等进行了比较全面的整理。
18年初时,我们进行了ROLAP系统的调研,并选择了Doris进行落地。当初调研完Doris的时候,我的初步判断是 只要 Doris 能够支持Bitmap精确去重,在大部分场景下基本上可以代替掉 Kylin。只不过一开始我们主要用Doris来解决Kylin和Druid没办法解决的灵活多维分析需求,所以一直没有在Doris中引入Bitmap精确去重。
一直到今年2019年,我们决定进行OLAP引擎(Doris,Kylin,Druid)的统一,我们进行了一系列的调研和POC,最后还是决定用Doris代替掉Kylin和Druid。所以今天下半年开始,我在Doris中实现了Bitmap精确去重。
Why HLL is Not Enough
当我们实现一个需求的时候,我们首先要思考的不是如何去实现这个需求, 而是去思考这是不是一个真正的需求,这个需求背后最深层的需求到底是什么。
我们都知道,当数据的规模越来越大,实时性越来越强的时候,在大数据领域普遍都会采用近似算法。而对去重这一普遍需求的近似实现就是HLL。在Google的BigQuery系统中,对于Count Distinct的实现默认就是近似的。
所以海量数据下的秒级精确去重到底是不是必须的?经过这几年和公司很多用户的多次沟通交流,这个结论显然是是必须的的。因为当和金钱,业绩相关时,用户是没法接受近似的情况的。比如说,你的推荐算法辛辛苦苦优化了5%,结果直接被近似掉了,你显然是不能接受的。
How Doris Count Distinct without Bitmap
我们知道,Doris除了支持HLL近似去重,也是支持Runtime 现场精确去重的。实现方法和Spark,MR类似。
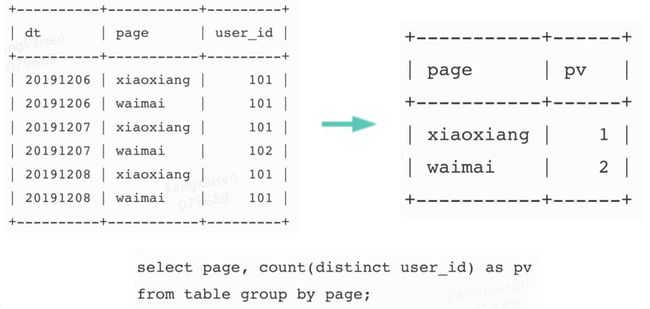 对于上图计算PV的SQL,Doris在计算时,会按照下图进行计算,先根据page列和user_id列 group by,最后再count。
对于上图计算PV的SQL,Doris在计算时,会按照下图进行计算,先根据page列和user_id列 group by,最后再count。
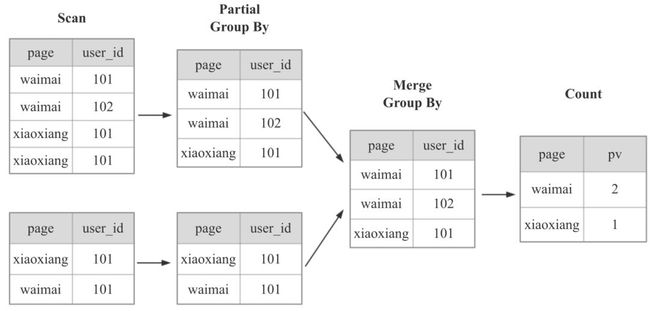
图中是6行数据在2个BE节点上计算的示意图)
显然,上面的计算方式,当数据量越来越大,到几十亿,几百亿时,使用的IO资源,CPU资源,内存资源,网络资源就会越来越多,查询也会越来越慢。
那么,下面一个自然而然的问题就是,我们应该如何让Doris的精确去重查询性能更快呢?
How To Make Count Distinct More Faster
1. 堆机器 2. Cache 3. 优化 CPU 执行引擎 (向量化,SIMD,查询编译等) 4. 支持 GPU 执行引擎 5. 预计算
第一种最容易想到的解法就是堆机器,因为Doris是MPP的架构,大多数算子的性能都是可以随着集群规模线性提升的。这种解法适合不差钱的土豪公司。
第二种也很容易想到的解决就是Cache,Cache在应用层和数据库层都可以做,但是Cache的问题是无法加速首次查询,而且在维度组合很灵活的情况下,Cache的命中率会很低。
第三种就是我们去优化查询执行器的性能,比如内存存储,向量化执行,SIMD指令加速,查询编译,以及数据结构和算法本身的优化等等,ClickHouse便是这种思路的代表。
第四种就是用GPU加速,我们知道,GPU适合计算密集应用,而且目前CPU的性能提升速度已经比较缓慢,但是GPU的性能提升速度却十分迅速。从一些公开测试和我之前做过的Demo测试来看,GPU执行器的性能会在CPU执行器性能的几十,上百倍。
第五种就是今天要分享的主题,预计算,就是空间换时间,也是Kylin, Druid和Doris聚合模型的核心思路,就是将计算提前到数据导入的过程中,减少存储成本和查询时的现场计算成本。
How Doris Count Distinct With Bitmap
我们要在Doris中预计算,自然要用到Doris的聚合模型,下面我们简单看下Doris中的聚合模型:
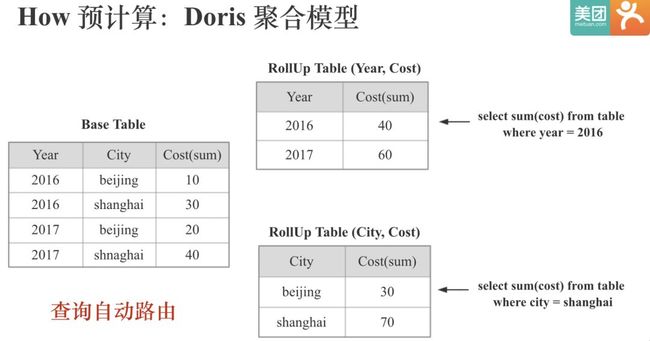
Doris的聚合模型分为Key列和Value列,Key列就是维度列,Value列是指标列,Key列全局有序,每个Value列会有对应的聚合函数,相同Key列的Value会根据对应的聚合函数进行聚合。上图中,Year,City是Key列,Cost是Value列,Cost对应的聚合函数式Sum。Doris支持根据不同维度组合建立不同的Rollup表,并能在查询时自动路由。
所以要在Doris中实现Count Distinct的预计算,就是实现一种Count Distinct的聚合指标。那么我们可以像Sum,Min,Max聚合指标一样直接实现一种Count Distinct 聚合指标吗?
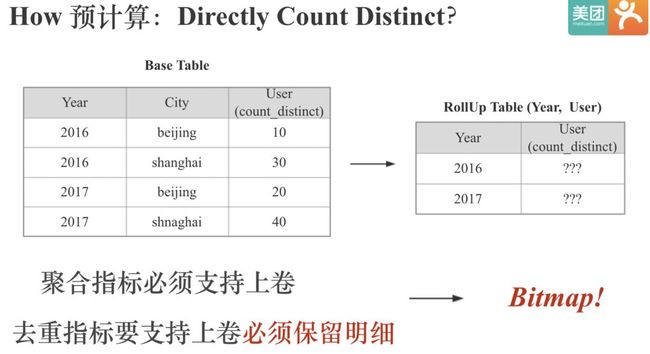
我们知道,Doris中聚合指标必须支持上卷。 例如原始Base表里有Year和City两个维度列,我们可以计算出每年每个City的去重User值。 但如果我们只保留每个City的User的去重值,就没办法上卷聚合出只有Year为维度的时候User的去重值,因为去重值不能直接相加,我们已经把明细丢失了,我们不知道在2016或2017年,北京和上海不重合的User有多少。
所以去重指标要支持上卷聚合,就必须保留明细,不能只保留一个最终的去重值。而我们知道计算机保留信息的最小单位是一个bit,所以我们很自然的想到用Bitmap来保留去重指标的明细数据。
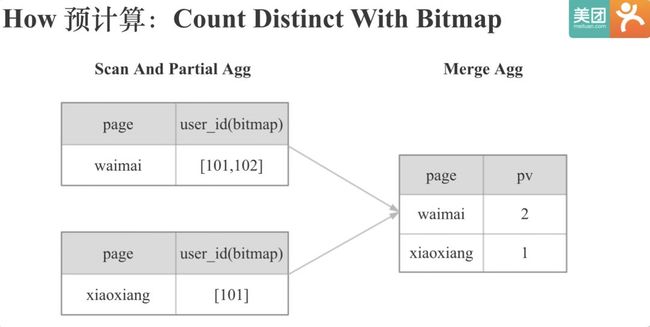
当使用Bitmap之后,之前的PV计算过程会大幅简化,现场查询时的IO,CPU,内存,网络资源会显著减少,并且不再会随着数据规模线性增加。
但是直接使用原始的Bitmap会有两个问题,一个是内存和存储占用,一个是Bitmap输入只支持Int类型。解决内存和存储占用的思路就是压缩,业界普遍采用的Bitmap库是Roaring Bitmap;解决任意类型输入的思路就是将任意类型映射到Int类型,为此我们引入了全局字典。
Roaring Bitmap 的核心思路很简单,就是根据数据的不同特征采用不同的存储或压缩方式。 为了实现这一点,Roaring Bitmap 首先进行了分桶,将整个int 域拆成了 2的16次方 65536个桶,每个桶最多包含65536个元素。
所以一个int的高16位决定了,它位于哪个桶,桶里只存储低16位。以图中的例子来说,62的前1000个倍数,高16位都是0,所以都在第一个桶里。
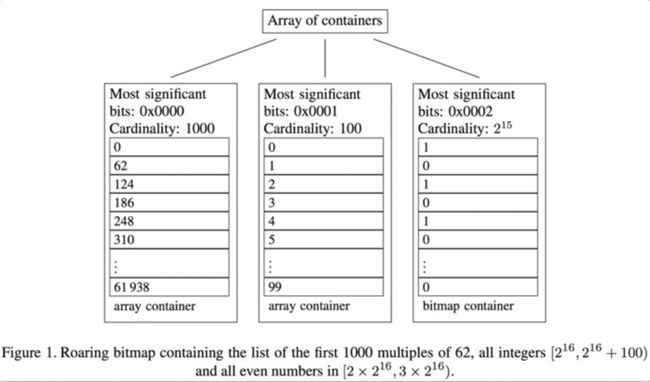
然后在桶粒度针对不同的数据特点,采用不同的存储或压缩方式:
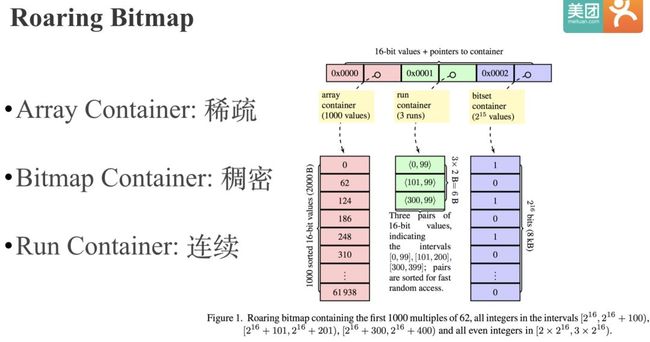
默认会采用16位的Short数组来存储低16位数据,当元素个数超过4096时,会采用Bitmap来存储数据。为什么是4096呢?我们知道,如果用Bitmap来存,65526个bit, 除以8是8192个字节,而4096个Short就是4096 * 2 = 8192个字节。所以当元素个数少于4096时,Array存储效率高,当大于4096时,Bitmap存储效率高。
第3类 Run Container 是优化连续的数据, Run 指的是 Run Length Encoding(RLE),比如我们有10到1000折连续的991个数字,那么其实不需要连续存储10到1000,这991个整形,我们只需要存储1和990这两个整形就够了。
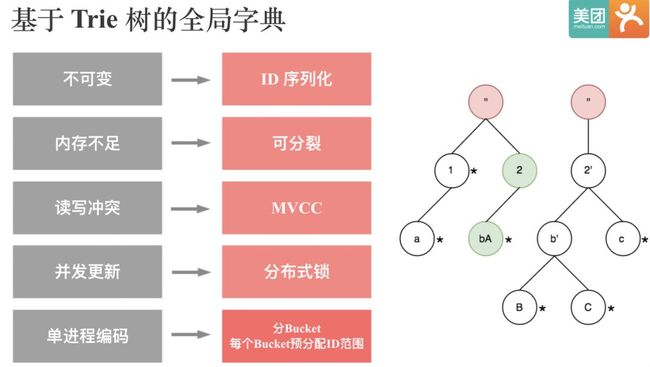
在做字典映射时,使用比较广泛的数据结构是Trie 树。Trie树又叫前缀树或字典树。叫前缀树,是因为某节点的后代存在共同的前缀,比如图中的2cb和2cc的前缀是2c。叫字典树,是因为Trie 树是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。Trie 树利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。所以Trie 树很适合用来实现字典编码,因为它的存储和检索效率都很高。
Trie 树的问题是字典对应的编码值是基于节点位置决定的,所以Trie 树是不可变的。这样没办法用来实现全局字典,因为要做全局字典必然要支持追加。
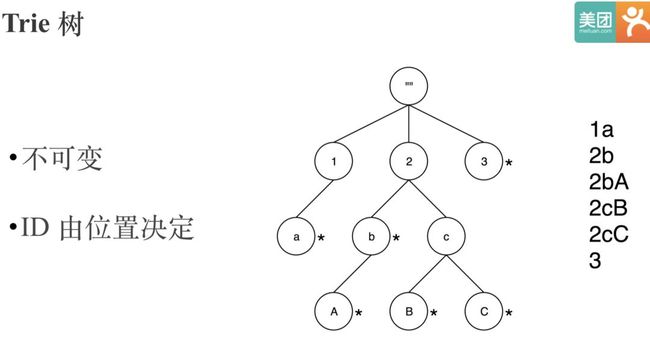
要实现全局字典,Trie 树必然要支持可追加,在可追加的情况下,我们需要解决如何让同一个String永远映射到同一个ID。一个简单的思路是我们把String对应的ID直接序列化下来,因为全局字典只需要支持String到ID的单向查找,不需要支持ID到String的反向查找。
当全局字典越来越大的时候,就会面临内存不足的问题。一个自然的想法就是Split, 如图所示。当全局字典拆成多个子树之后,必然会涉及到每个子树的按需加载和删除,这个功能是使用Guava的LoadingCache实现的。
为了解决读写冲突的问题,我们实现了MVCC,使得读写可以同时进行。全局字典目前是存储在HDFS上的,一个全局字典目录下会有多个Version,读的时候永远读取最新Version的数据,写的时候会先写到临时目录,完成后再拷贝到最新的Version目录。同时为了保证全局字典的串行更新,我们引入了分布式锁。
目前基于 Trie 树的全局字典存在的一个问题是,全局字典的编码过程是串行的,没有分布式化,所以当全局字典的基数到几十亿规模时,编码过程就会很慢。一个可行的思路是,类似 Roaring Bitmap,我们可以将整个Int域进行分桶,每个桶对应固定范围的ID编码值,每个String通过Hash决定它会落到哪个桶内,这样全局字典的编码过程就可以并发。
正是由于目前基于 Trie 树的全局字典 无法分布式构建,滴滴的同学引入了基于Hive表的全局字典。
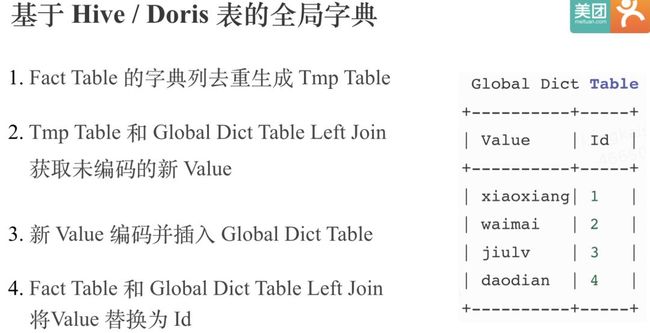
这种方案中全局字典本身是一张 Hive 表,Hive 表有两个列,一个是原始值,一个是编码的Int值,然后通过上面的4步就可以通过Spark或者MR实现全局字典的更新,和对事实表中Value列的替换。
基于Hive表的全局字典相比基于 Trie 树的全局字典的优点除了可以分布式化,还可以实现全局字典的复用。但是缺点也是显而易见,相比基于 Trie 树的全局字典,会使用多几倍的资源,因为原始事实表会被读取多次,而且还有两次Join。
How to Use Doris Bitmap
1. Create Table (为了有更好的加速效果,最好建下ROLLUP)
CREATE TABLE `pv_bitmap` (`dt` int,`page` varchar(10),`user_id` bitmap bitmap_union)AGGREGATE KEY(`dt`, page)DISTRIBUTED BY HASH(`dt`) BUCKETS 2;ALTER TABLE pv_bitmap ADD ROLLUP pv (page, user_id);
2. Load Data
3. Querycat data | curl --location-trusted -u user:passwd -T --H "columns: dt,page,user_id, user_id=$BITMAP_LOAD_FUNCTION(user_id)"http://host:8410/api/test/pv_bitmap/_stream_loadTO_BITMAP(expr) : 将 0 ~ 4294967295 的 unsigned int 转为 bitmapBITMAP_HASH(expr): 将任意类型的列通过 Hash 的方式转为 bitmapBITMAP_EMPTY(): 生成空 bitmap,用于 insert 或导入的时填充默认值
4. Insert Into ( 可以加速无需上卷的精确去重查询场景 )select bitmap_count(bitmap_union(user_id)) from pv_bitmap;select bitmap_union_count(user_id) from pv_bitmap;select bitmap_union_int(id) from pv_bitmap;BITMAP_UNION(expr) : 计算两个 Bitmap 的并集,返回值是序列化后的 Bitmap 值BITMAP_COUNT(expr) : 计算 Bitmap 的基数值BITMAP_UNION_COUNT(expr): 和 BITMAP_COUNT(BITMAP_UNION(expr)) 等价BITMAP_UNION_INT(expr) : 和 COUNT(DISTINCT expr) 等价(仅支持TINYINT,SMALLINT 和 INT)
insert into bitmaptable1 (id, id2) VALUES (1001, tobitmap(1000)), (1001, to_bitmap(2000));insert into bitmaptable1 select id, bitmapunion(id2) from bitmap_table2 group by id;insert into bitmaptable1 select id, bitmaphash(id_string) from table;
基于 Bitmap 的用户行为分析
User Behavior Analysis Based
用户行为分析从字面意思上讲,就是分析用户的行为。分析用户的哪些行为呢?可以简单用5W2H来总结。即 Who(谁)、What(做了什么行为)、When(什么时间)、Where(在哪里)、Why(目的是什么)、How(通过什么方式),How much (用了多长时间、花了多少钱)。
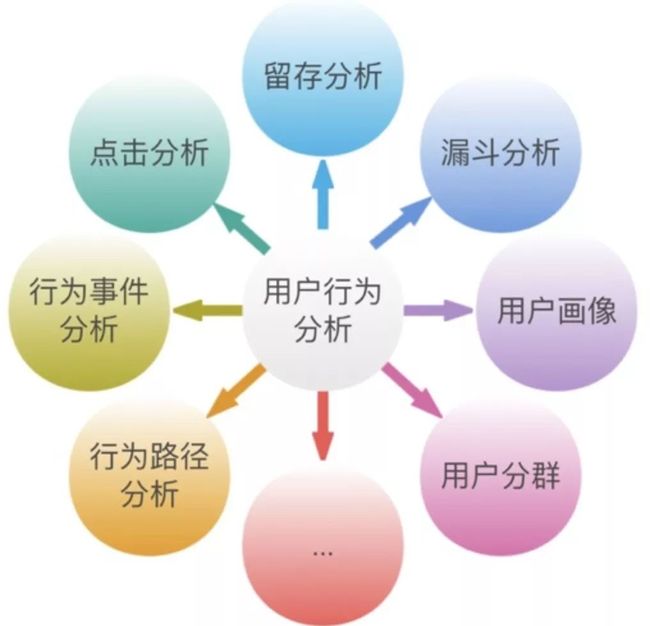
为什么要做用户行为分析呢?
其终极目的就是为了不断优化产品,提升用户体验,让用户花更多的时间,花更多的钱在自己的产品上。
图中列出了常见的用户行为模型,比如留存分析,是指用户在某段时间内开始使用应用,经过一段时间后,仍然继续使用该应用的用户,被认作是该应用的留存用户。比如某应用某天新增用户1万人,然后低二天只有5千人打开过应用,那么日留存就是50%。
还有漏斗分析,最常见的就是一个转换漏斗,就是从展现页开始,有多少人会点击,进而有多少人会访问,最后又多少人会咨询和下单,这里面每一步的人数都会减少,用图画出来的话,刚好就是一个漏斗的形状。
还有点击分析,就是可以根据用户在整个页面的点击浏览,情况,知道哪些图片,广告是设置合理的,哪些是有问题的,进而进行改进。比如双11京东,天猫的首页,每个图片怎么放置,决定不是随便放的,背后肯定是有数据支撑的。
剩下的就不一一介绍了。大家需要注意一点,目前我们数据库是可以回答用户行为What和Why的问题,而和机器学习结合后,我们是可以直接进行预测用户行为的。
目前用户行为分析的解法大概有这么几种:
第一种就数据库的Join解法,一般效率是比较低的。我们在Doris中是可以用这种思路实现的。
第二种是基于明细数据的,UDAF实现。Doris也是支持的。
第三种是基于Bitmap的UDAF实现的,也就是今天要分享的。
第四种是用专用的系统来做用户行为分析,专用系统的好处是可以针对特定场景,做更多的优化。
而且在专用系统里,很多公司也采用了基于Bitmap的方案,原因是我们可以用1个bit位表示一个用户,那么Bitmap的交,并,差,对称差集等运算都可以和大多数用户行为模型对应起来,并且Bitmap的交,并,差,对称差集运算可以借助SIMD指令加速,是很高效的。比如, 去重用户就是Bitmap 取1的个数,活跃用户就是两个Bitmap 取并集,重度用户,留存用户,转换可以是两个Bitmap 取交集,新增用户可以是 Bitmap 取差集等等。
Doris Intersect_count
由于我们现在已经在Doris的聚合模型中支持了Bitmap,所以我们便可以基于Bitmap 实现各类UDF, UDAF,来实现大多数用户行为分析。
目前,我们首先在Doris中实现了求交集的UDAF intersect_count,这个UDAF的定义是参考Kylin的,主要是为了支持Kylin的应用可以迁移到Doris中来。intersect_count的第一个参数是Bitmap列,第二个参数是用来过滤的维度列,第三个参数开始是变长参数,含义是过滤维度列的不同取值。intersect_count整个函数的功能就是计算满足filter_column 过滤条件的多个 Bitmap 的交集的基数值。前面提到过,Bitmap 交集可以用来计算留存,漏斗,用户画像,下面我们来具体看一下。
Intersect_count 计算留存
例如,假设我们有user_id和dt列,前两行相当于计算了这两天的去重用户数,第三行计算的是20191111和20191112这两天用户的交集,相除便即可计算出两天的留存率。select intersect_count(user_id, dt, '20191111') as first_day,intersect_count(user_id, dt, '20191112') as second_day,intersect_count(user_id, dt, '20191111', '20191112') as retention,from tablewhere dt in ('20191111', '20191112')
Intersect_count 计算漏斗
假如我们有user_id和page的信息,我们希望知道在访问美团页面之后,又有多少用户访问了外卖页面,也可以用intersect_count来进行计算。 Intersect_count 筛选特定用户select intersect_count(user_id, page, 'meituan') as meituan_uv,intersect_count(user_id, page, 'waimai') as waimai_uv,intersect_count(user_id, page, 'meituan', 'waimai') as retentionfrom visit_logwhere page in ('meituan', 'waimai');
最后我们也可以通过intersect_count来进行一些特定用户的筛选。例如原始表里有user_id,tag_value,tag_type这些信息,我们想计算年收入10-20万的90后男性有多少,就可以用这个简单的SQL来实现。selectintersect_count(user_id, tag_value, '男', '90后', '10-20万')from user_profilewhere (tag_type='性别' and tag_value='男')or (tag_type='年龄' and tag_value='90后')or (tag_type='收入' and tag_value='10-20万')
Doris Bitmap ToDo
1. 全局字典进行开源,支持任意类型的精确去重
2. 支持Int64,支持Int64后一方面支持更高基数的bitmap精确去重,另一方面如果原始数据中有bigint类型的数据便不需要全局字典进行编码。
3. 支持Array类型。很多用户行为分析的场景下的UDAF或UDF,用Array表达更加方便和规范。
4. 更方便更智能的批量创建Rollup。当用户基数到达十多亿时,Bitmap本身会比较大,而且对几十万个Bitmap求交的开销也会很大,因此还是需要建立Rollup来进行加速查询。更进一步,我们期望可以做到根据用户的查询特点去自动建立Rollup。
5. 希望支持更多、更复杂的用户行为分析。
Summary
如果应用基数在百万、千万量级,并拥有几十台机器,那么直接选择count distinct即可;
如果应用基数在亿级以上并可以近似去重,那么选择HLL或Bitmap均可;
如果应用基数在亿级以上并需要精确去重,那么选择Bitmap即可;
如果你希望进行用户行为分析,可以考虑IntersectCount或者自定义UDAF。
Reference
RoaringBitmap 论文及源码: https://github.com/RoaringBitmap/RoaringBitmap
Apache Kylin 精确去重和全局字典权威指南: https://blog.bcmeng.com/post/kylin-distinct-count-global-dict.html
Kylin 精确去重在用户行为分析中的妙用: https://kyligence.io/zh/blog/apache-kylin-count-distinct-application-in-user-behavior-analysis/
Use Hive to build global dictionary: kylin.apache.org/docs30/howto/howto_use_hive_mr_dict.html
欢迎扫码关注:

Apache Doris(incubating)官方公众号
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Github:
https://github.com/apache/incubator-doris
Apache Doris Wiki:
https://github.com/apache/incubator-doris/wiki
Apache Doris 开发者邮件组:
本文分享自微信公众号 - ApacheDoris(gh_80d448709a68)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。