对比学习在NLP中应用全面解读
对比学习(Contrastive Learning)在自然语言处理(NLP)中具有广泛的应用。对比学习是一种无监督学习方法,旨在将相似样本聚集在一起,并将不相似样本分开。 在NLP中,对比学习的目标是学习出具有语义相似性的向量表示。
以下是对比学习在NLP中的一些常见应用:
文本相似度计算:对比学习可以学习将语义上相似的文本对映射到相近的向量空间中。通过计算文本对之间的相似度,可以用于文本匹配、重述检测、问答系统、信息检索等任务。
文本分类:对比学习可以通过学习文本的向量表示,将具有相似语义的文本分类到同一类别。这可以用于情感分析、主题分类、垃圾邮件分类等任务。
词义表示学习:对比学习可以学习将具有相似词义的词语映射到相近的向量空间中。通过计算词之间的相似度,可以用于词义相似性计算、词语推荐、词义消歧等任务。
句子表示学习:对比学习可以学习出句子的向量表示,表达句子的语义信息。这对于文本生成、句子相似度计算、句子分类等任务非常有用。
语言模型预训练:对比学习在语言模型的预训练中也得到了广泛应用。通过对比学习,模型可以学习出更好的上下文表示,从而提供更好的语言理解和生成能力。
本文主要讲述三种效果比较好的对比学习方法,SimCLR(2019)、SimCSE(2021)以及ArcCon(2022),从原理讲解到代码实现.
目录
一、SimCLR
1.1 SimCLR 对比损失函数
1.2 代码实现一
1.3 代码实现二
二、SimCSE
2.1 SimCSE 对比损失函数
2.2 代码实现
三、ArcCon
3.1 损失函数
3.2 代码实现
一、SimCLR
SimCLR方法最初是在2019年的一篇论文中提出的,该论文名为《A Simple Framework for Contrastive Learning of Visual Representations》。这篇论文由Ting Chen、Simon Kornblith、Mohammad Norouzi和Geoffrey Hinton等人共同撰写。该论文详细介绍了SimCLR方法的原理和实验结果,并在图像领域展示了无监督学习达到有监督学习性能的能力。
该论文在2019年的计算机科学领域的顶级会议CVPR(Computer Vision and Pattern Recognition)上发表。由于SimCLR方法的简单性和强大性,该论文引起了广泛的关注,并且成为对比学习领域的重要里程碑。SimCLR方法通过数据增强、对比损失和温度参数等关键机制,使得模型能够学习到具有丰富语义信息的特征表示。通过将相似样本聚集在一起,并将不相似样本分开,SimCLR方法在计算机视觉和自然语言处理等领域取得了很好的性能。
1.1 SimCLR 对比损失函数
我们从N个样本中随机抽取一个小批量数据,并将对比预测任务定义在由小批量数据衍生的成对增广样本上,产生2N个数据点。具体使用的时候,最直接最简单粗暴的训练方式是:以采用一种数据扩增为例,一个batch为N的训练样本,通过数据扩增,变成了2N个样本,其中有1个正样本对,2N-2个负样本对。
![]() 表示归一化后的u和v(即余弦相似度)之间的点积
表示归一化后的u和v(即余弦相似度)之间的点积
然后定义一对正例( i , j)的损失函数为:
![]()
最终的损失是batch中所有正样本对损失的算术平均值:
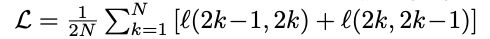
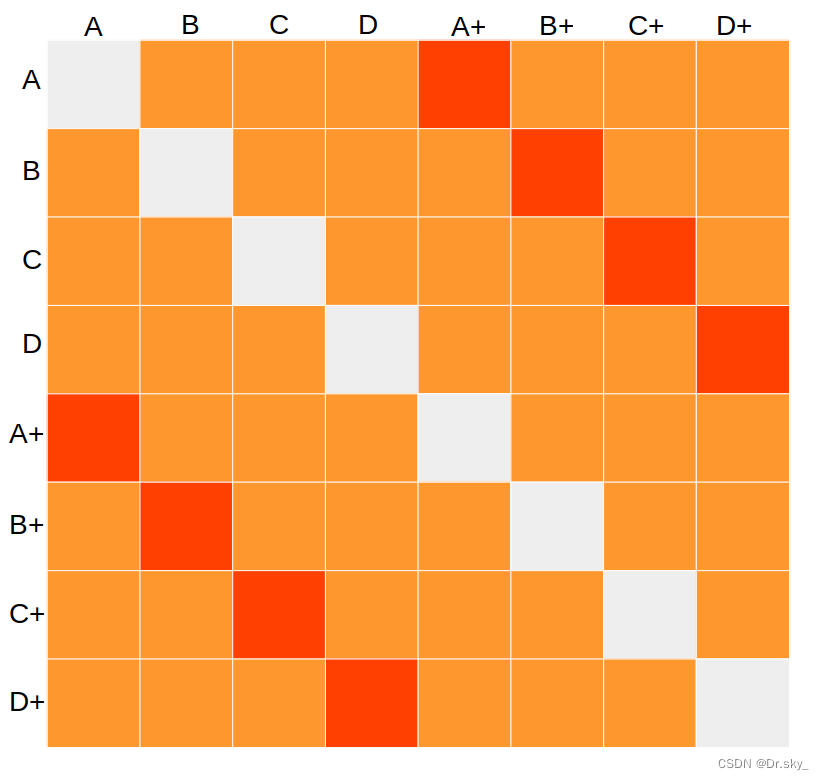
例:如下图构建的相似度矩阵,batch_size=4,[A,B,C,D]代表四个样本向量.[A+,B+,C+,D+]代表四个生成的对抗样本,[A,A+]代表一对正样本对,对角线形成的样本对去除.对比学习的思路是通过损失函数,让正样本对拉近距离,负样本对拉大距离,
1.2 代码实现一
class ContrastiveLoss(nn.Module):
def __init__(self, batch_size, device='cuda', temperature=0.5):
super().__init__()
self.batch_size = batch_size
self.register_buffer("temperature", torch.tensor(temperature).to(device)) # 设置温度的超参数
self.register_buffer("negatives_mask", (~torch.eye(batch_size * 2, batch_size * 2, dtype=bool).to(device)).float()) # 一个主对角线为0,其余位置全为1的mask矩阵
def forward(self, emb_i, emb_j): # emb_i, emb_j 是来自同一图像的两种不同的预处理方法得到的嵌入特征
z_i = F.normalize(emb_i, dim=1) # 对emb_i进行归一化,得到z_i形状为(bs, dim)
z_j = F.normalize(emb_j, dim=1) # 对emb_j进行归一化,得到z_j形状为(bs, dim)
representations = torch.cat([z_i, z_j], dim=0) # 将z_i和z_j按行拼接,得到形状为(2*bs, dim)的representations
similarity_matrix = F.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0), dim=2) # 计算representations之间的余弦相似度得到相似度矩阵similarity_matrix,形状为(2*bs, 2*bs)
sim_ij = torch.diag(similarity_matrix, self.batch_size) # 取相似度矩阵similarity_matrix中位置为(batch_size, 2*batch_size)的对角线元素,得到相似度sim_ij,形状为(bs)
sim_ji = torch.diag(similarity_matrix, -self.batch_size) # 取相似度矩阵similarity_matrix中位置为(-batch_size, -2*batch_size)的对角线元素,得到相似度sim_ji,形状为(bs)
positives = torch.cat([sim_ij, sim_ji], dim=0) # 将sim_ij和sim_ji按行拼接,得到形状为(2*bs)的positives
nominator = torch.exp(positives / self.temperature) # 计算positives除以温度temperature的指数,得到形状为(2*bs)的nominator
denominator = self.negatives_mask * torch.exp(similarity_matrix / self.temperature) # 计算相似度矩阵similarity_matrix除以温度temperature的指数,并乘以negatives_mask进行对应位置的剔除,得到形状为(2*bs, 2*bs)的denominator
loss_partial = -torch.log(nominator / torch.sum(denominator, dim=1)) # 计算partial loss,即-nominator除以denominator在dim=1上的和,得到形状为(2*bs)的loss_partial
loss = torch.sum(loss_partial) / (2 * self.batch_size) # 对loss_partial求和,再除以(2 * batch_size)得到平均损失loss
return loss1.3 代码实现二
import torch
from torch import nn
import torch.nn.functional as F
class ContrastiveLossELI5(nn.Module):
def __init__(self, batch_size, temperature=0.5, verbose=True):
super().__init__()
self.batch_size = batch_size
self.register_buffer("temperature", torch.tensor(temperature))
self.verbose = verbose
def forward(self, emb_i, emb_j):
"""
emb_i and emb_j are batches of embeddings, where corresponding indices are pairs
z_i, z_j as per SimCLR paper
"""
z_i = F.normalize(emb_i, dim=1)
z_j = F.normalize(emb_j, dim=1)
representations = torch.cat([z_i, z_j], dim=0)
similarity_matrix = F.cosine_similarity(representations.unsqueeze(1), representations.unsqueeze(0), dim=2)
if self.verbose: print("Similarity matrix\n", similarity_matrix, "\n")
def l_ij(i, j):
z_i_, z_j_ = representations[i], representations[j]
sim_i_j = similarity_matrix[i, j]
if self.verbose: print(f"sim({i}, {j})={sim_i_j}")
numerator = torch.exp(sim_i_j / self.temperature)
one_for_not_i = torch.ones((2 * self.batch_size, )).to(emb_i.device).scatter_(0, torch.tensor([i]), 0.0)
if self.verbose: print(f"1{{k!={i}}}",one_for_not_i)
denominator = torch.sum(
one_for_not_i * torch.exp(similarity_matrix[i, :] / self.temperature)
)
if self.verbose: print("Denominator", denominator)
loss_ij = -torch.log(numerator / denominator)
if self.verbose: print(f"loss({i},{j})={loss_ij}\n")
return loss_ij.squeeze(0)
N = self.batch_size
loss = 0.0
for k in range(0, N):
loss += l_ij(k, k + N) + l_ij(k + N, k)
return 1.0 / (2*N) * loss二、SimCSE
SimCSE(Simple Contrastive Learning of Sentence Embeddings)是一种用于学习句子嵌入表示的对比学习方法,由Facebook AI团队提出。以下是该论文的详细信息:
- 论文标题:Simple Contrastive Learning of Sentence Embeddings
- 作者:Gao, Tianyu, Yao, Xingcheng, Chen, Danqi
- 发表时间:2021年
- 论文链接:https://doi.org/10.48550/arXiv.2104.08821
该论文介绍了一种简单而有效的对比学习方法,该方法通过比较具有相似语义的句子对的嵌入表示来训练模型。SimCSE的核心思想是通过最大化相关句子对的相似度,并最小化不相关句子对的相似度,从而学习到有语义含义的句子嵌入表示。
为了实现这一目标,论文中提出了两个关键的技术策略:
- Siamese网络架构:利用Siamese网络,将两个句子分别作为输入,并共享相同的权重来生成它们的嵌入表示。
- 对比损失函数:使用对比损失函数(Contrastive Loss),对具有相似语义的句子对进行增强,并将其与随机负样本进行对比。这有助于鼓励正样本之间的相似性,并使负样本与正样本区分开来。
该论文通过一系列实验证明了SimCSE方法在多个自然语言处理任务上的优越性能,包括文本匹配、文本分类和句子检索等任务。SimCSE方法的简洁性和效果使其成为学习句子嵌入表示的重要技术之一。
2.1 SimCSE 对比损失函数
![]()
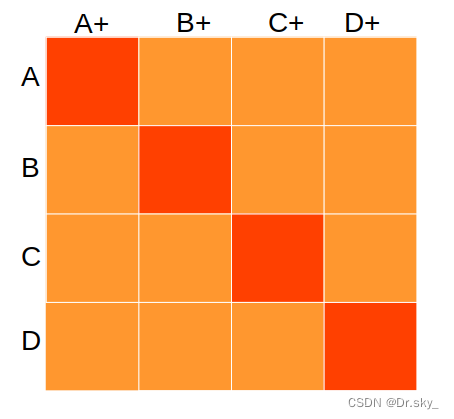
SimCSE对比学习相似度矩阵如下,对角线元素为正样本对,batch_size=4的情况下, 1个正样本对{A,A+},对应N-1个负样本对.
2.2 代码实现
class ContrastiveLoss1(nn.Module):
def __init__(self, batch_size, temperature):
super().__init__()
self.batch_size = batch_size
self.register_buffer("temperature", torch.tensor(temperature).to(device)) # 超参数 温度
def forward(self, emb_i, emb_j): # emb_i, emb_j 是来自文本,i为初始文本的embedding,j为添加扰动后的embedding
z_i = nn.functional.normalize(emb_i) # 按行计算
z_j = nn.functional.normalize(emb_j)
dis_matrix = torch.mm(emb_i,emb_j.T) / self.temperature
cos_matix = dis_matrix / (emb_i.norm(2) * emb_j.norm(2))
pos = torch.diag(cos_matix)
dedominator = torch.sum(torch.exp(cos_matix),dim=1)
loss = (torch.log(dedominator) - pos).mean()
return loss三、ArcCon
《A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space》(2022)这篇论文主要提出了一种对比学习的框架,用于从角度空间的两两对比和三元组对比的角度,学习句子表示。以下是该论文的主要思想和方法:
引言和背景:论文指出传统的对比学习方法在学习句子表示时存在一些限制,如欧氏空间的完全相似度或差异度。为了解决这些限制,论文提出了一种基于角度空间的对比学习方法,该方法可以更好地捕捉句子之间的细微差异。
角度空间对比学习框架:论文提出了一个框架,用于从角度空间的两两对比和三元组对比的角度来学习句子表示。该框架包括两个关键组件:角度对比(Angle Contrast)和三元组对比(Triple Contrast)。
角度对比(Angle Contrast):通过最大化正样本之间的余弦相似度,并最小化负样本之间的余弦相似度,来学习句子之间的角度关系。通过引入一个角度对比损失函数,将角度关系转化为特征空间中余弦相似度的对比问题。
三元组对比(Triple Contrast):通过构造三元组样本,利用最大化同类样本之间的夹角余弦相似度,并最小化异类样本之间的夹角余弦相似度,来进一步优化句子表示。通过引入一个三元组对比损失函数,将三元组样本的角度关系转化为特征空间中的余弦相似度对比问题。
实验设计和结果:论文通过在多个句子相似度任务和句子分类任务上的实验验证了该方法的有效性。实验结果显示,角度空间对比学习方法具有更好的性能和泛化能力,能够捕捉到句子语义的微妙差异,并在多个任务上取得了优越的表现。
分析和讨论:论文进一步分析了角度空间对比学习方法的特点和优势,并讨论了其与其他相关方法的比较和关联。还探讨了该方法在不同数据集和实际应用中的适用性和可扩展性。
结论和未来工作:论文总结了角度空间对比学习的优点和贡献,并提出了未来可能的研究方向,如引入更精细的角度对比和三元组对比策略,以及在更广泛的语义任务上的应用拓展等。
该论文的主要思想和方法围绕角度空间对比学习展开,通过最大化正样本和最小化负样本之间的余弦相似度来学习句子表示。通过对角度和三元组关系的对比优化,该方法能够更好地捕捉到句子之间的微妙差异,并在多个自然语言处理任务中取得较好的性能。
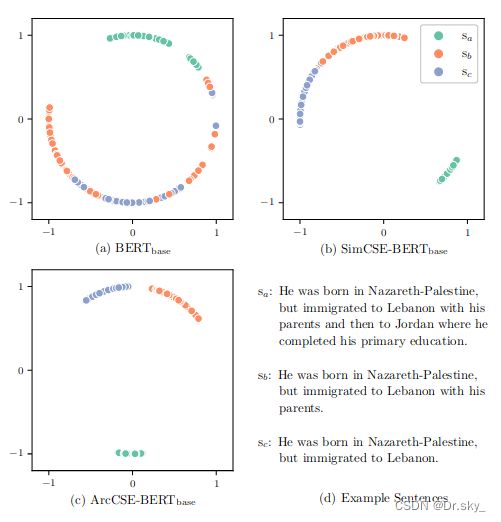
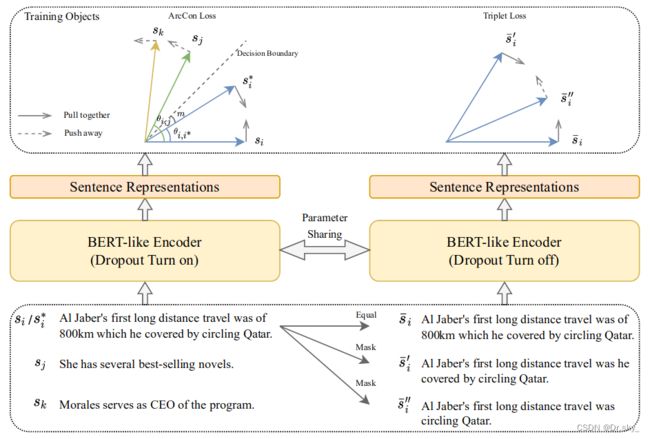
3.1 损失函数
得到正负句对后,我们将其放入一个训练目标中进行模型微调。目前应用最广泛的训练目标是NT - Xent loss ( Chen et al . , 2020 ; Gao et al , 2021),该目标已经在之前的句子和图像表示学习方法中得到了应用:
![]()
式中:![]() 为余弦相似度
为余弦相似度![]() ,τ为温度超参数,n为 batch_size 内句子数。尽管训练目标试图将具有相似语义的表示拉近,并将不相似的表示推开,但这些表示可能仍然没有足够的辨别力,对噪声也不是很鲁棒。记角
,τ为温度超参数,n为 batch_size 内句子数。尽管训练目标试图将具有相似语义的表示拉近,并将不相似的表示推开,但这些表示可能仍然没有足够的辨别力,对噪声也不是很鲁棒。记角![]() 如下:
如下:
![]()
NT - Xent损失与Arc Con损失的比较。对于句子表示hi,我们试图使![]() 更小,
更小,![]() 更大,因此优化方向遵循箭头。额外增加一个间隔m,ArcCon更具判别性,为抗噪声。
更大,因此优化方向遵循箭头。额外增加一个间隔m,ArcCon更具判别性,为抗噪声。
![]()
3.2 代码实现
class ArcConLoss(nn.Module):
def __init__(self, batch_size, temperature, margin):
super().__init__()
self.batch_size = batch_size
self.temperature = temperature
self.margin = margin
def forward(self, emb_i, emb_j):
# z_i = nn.functional.normalize(emb_i)
# z_j = nn.functional.normalize(emb_j)
z_i = emb_i
z_j = emb_j
# 计算向量数量和形状
num_vectors = z_i.shape[0]
vector_shape = z_i.shape[1:]
# 初始化相似度矩阵
similarity_matrix = torch.zeros((num_vectors, num_vectors))
# 计算相似度矩阵
for i in range(num_vectors):
for j in range(num_vectors):
similarity = cosine_similarity(z_i[i].view(1, -1), z_j[j].view(1, -1))
similarity_matrix[i, j] = similarity
# print(similarity_matrix)
# 提取对角线元素
diagonal_elements = torch.diag(similarity_matrix)
# 创建掩码矩阵,对角线元素为 False,其他元素为 True
mask = ~torch.eye(similarity_matrix.size(0), dtype=torch.bool)
# 使用掩码矩阵获取除对角线以外的元素
other_elements = torch.masked_select(similarity_matrix, mask)
theta_i_i_star = torch.acos(diagonal_elements)
theta_j_i = torch.acos(other_elements)
numerator = sum(torch.exp(torch.cos(theta_i_i_star + self.margin) / self.temperature))
denominator = numerator + torch.sum(torch.exp(torch.cos(theta_j_i)) / self.temperature)
# loss = (torch.log(denominator) - torch.log(numerator)) / self.batch_size
loss = (torch.log(denominator) - torch.log(numerator))
return loss