基于ECharts+flask的爬虫可视化
项目效果。
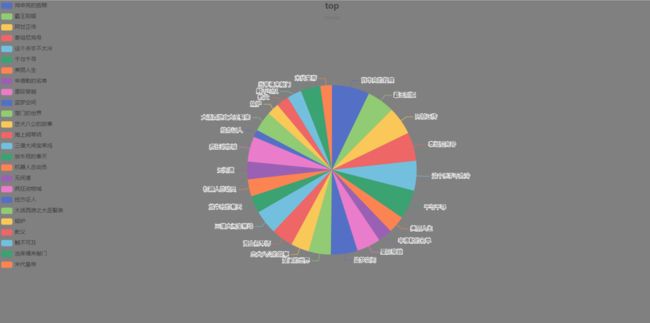
本案例基于python的flask框架,通过爬虫程序将数据存储在csv文件中,在项目运行时会通过render_template映射出对应的页面,并且触发一个函数,该函数会读取csv文件的数据将之交给echarts渲染 ,echarts将之渲染到页面中。
demo.html
from flask import Flask,render_template
import pandas as pd
app = Flask(__name__)
@app.route("/")
def show():
data = pd.read_csv('data.csv',encoding='gbk').to_dict(orient="records")
return render_template("demo.html",data=data)
if __name__ == '__main__':
app.run()movie.py
import requests
import re
#获取页面信息
url = "https://movie.douban.com/top250"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.27"
}
r = requests.get(url,headers=headers)
r = r.text
#解析页面
obj = re.compile(r'.*?(?P.*?) .*?'
r'(?P.*?)人评价',re.S)
#匹配
result = obj.finditer(r)
f = open("data.csv",mode="a")
i = 0
f.write("name,value\n")
#输入
for it in result:
f.write(str(i)+","+it.group("name")+","+it.group("num")+'\n')
i += 1
f.close()
demo.html
data.csv
data.csv由movie.py运行得到。
name,value
0,肖申克的救赎,2908819
1,霸王别姬,2147509
2,阿甘正传,2168793
3,泰坦尼克号,2199337
4,这个杀手不太冷,2302579
5,千与千寻,2252354
6,美丽人生,1330888
7,辛德勒的名单,1109486
8,星际穿越,1845221
9,盗梦空间,2068413
10,楚门的世界,1717501
11,忠犬八公的故事,1403302
12,海上钢琴师,1683202
13,三傻大闹宝莱坞,1864702
14,放牛班的春天,1316000
15,机器人总动员,1320349
16,无间道,1368920
17,疯狂动物城,1944723
18,控方证人,563523
19,大话西游之大圣娶亲,1538921
20,熔炉,934045
21,教父,971356
22,触不可及,1117970
23,当幸福来敲门,1524931
24,末代皇帝,888701
当然,我更希望爬虫程序是自动加载的,可以将之封装为一个函数,在页面加载时调用它。