Python数据处理——pandas
文章目录
- 0. 基本概念
-
- Series
-
- (一)创建Series
- (二)Series的简单操作
- DataFrame
-
- (一)创建DataFrame
- 1. 数据选取
-
- 1.1 [[]]
- 1.2 copy()
- 1.3 列操作
- 1.4 行操作
- 1.5 行-列
- 1.6 数据筛选
- 2. 加载数据
-
- 2.1 Txt
- 2.2 Csv
- Excel
- 3. 排序与合并
-
- 3.1 Series排序
- 3.2 DataFrame排序
- 3.3 Rank
- 3.4 merge(按列匹配合并)
- 3.5 concat(数据的拼接)
- 4. 数据汇总
-
- 4.1 特殊值(info, describe)
- 4.2 分组统计
- 5. 时间序列
-
- 5.1 初始化时间序列
- 5.2 时间索引
- 5.3 重采样
- 参考资料
0. 基本概念
Pandas的数据类型是一张表,可以把Pandas理解为内存型的数据库。
import pandas as pd
Series:列
DataFrame:表
Series
(一)创建Series
1. 使用列表list创建Series
(1)默认列表索引从0 - n-1
# 使用列表List初始化序列,索引值默认为0-n
ser = pd.Series(['张三', '李四', '王五'])
ser
0 张三
1 李四
2 王五
dtype: object
(2)可以通过 index 参数指定索引值
ser = pd.Series(['张三', '李四', '王五'], index = list(range(1,4))) # index 指定索引值
ser
1 张三
2 李四
3 王五
dtype: object
2. 使用字典dict创建Series
(1)默认索引值为字典的’key’值
data = {'Beijing': 9240, 'Shanghai': 8960, 'Guangzhou': 7400}
ser3 = pd.Series(data)
ser3
Beijing 9240
Shanghai 8960
Guangzhou 7400
dtype: int64
(二)Series的简单操作
1. 修改元素值
(1)修改单独元素值
需要指定索引,可以修改指定索引的元素值。
(2)修改整列元素值
直接对Series操作,会修改整列元素值
ser2 = pd.Series([18, 19, 20], index = range(1,4))
ser2 + 1
1 19
2 20
3 21
dtype: int64
2. 类型转换
| 转换 | 代码 |
|---|---|
| series -> dict | .to_dict() |
| series -> list | .to_list() |
| series -> frame | .to_frame() |
| series -> json | .to_json() |
ser3.to_frame()

DataFrame
(一)创建DataFrame
1. 由numpy创建
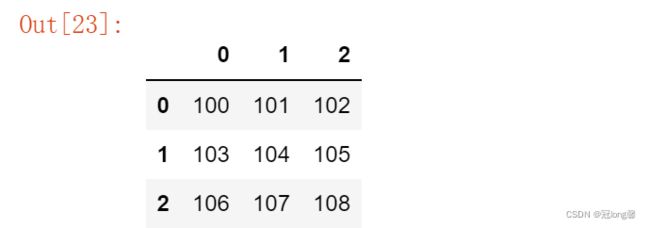
numpy初始化创建的DataFrame的索引(index)和列名(columns)都是由 0 - n-1 的数字组成。
import numpy as np
data = np.arange(100, 109).reshape(3, -1)
df = pd.DataFrame(data)
df
2. 由dict创建
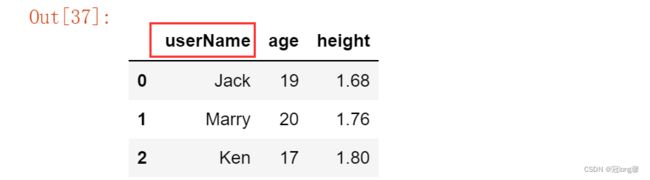
dict初始化创建的DataFrame的列名与dict的key值保持相同
data = {
'name':['Jack', 'Marry', 'Ken'],
'age': [19, 20, 17],
'height': [1.68, 1.76, 1.80]
}
df = pd.DataFrame(data)
df

3. 索引与列名
可以通过.columns获得列名,.index获得索引。可以在初始化时指定索引和列名或者后期更改
df1 = pd.DataFrame(data, columns=['name','age','height','email'], index = range(1,4))
df1

# 获取列名
df.columns
# 索引信息
df.index
# 修改列名
df.columns = ['userName', 'age', 'height']
# 修改行索引
df.index = ['ABC'] # 通过字符串赋值
df.index = range(df.shape[0])
df
Index([‘name’, ‘age’, ‘height’], dtype=‘object’)
RangeIndex(start=0, stop=3, step=1)
1. 数据选取
- Index:返回DataFrame行的索引列表,常用于索引切片
- Columns:返回DataFrame列的索引,常用于索引和切片
- loc:返回DataFrame指定自定义索引的行
- iloc:返回DataFrame指定真是位置索引的行
注意:loc[], columns[]都是索引向量。 - shape:返回DataFrame行数、列数的列表
- drop(index , axis = ):删除指定索引,指定行(0)列(1)的元素
- [], [[]]:分别以Series和DataFrame形式从DataFrame中读取数据
- iat[x, y]:返回指定行列元素
1.1 [[]]
需要取出DataFrame某一列时,得到的是Series变量。有些时候需要取出的列为DataFrame格式。
# 取出一列(Series格式)
df['name']
df.name
# DataFrame格式
df[['name', 'age']]
0 张三
1 李四
2 王五
3 赵六
Name: name, dtype: object

1.2 copy()
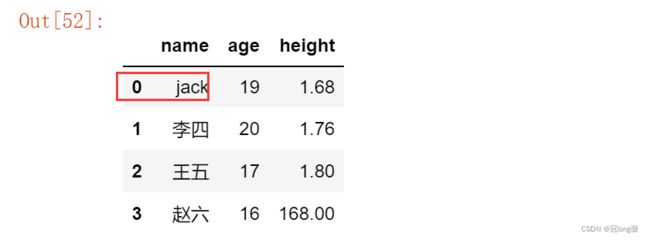
由于DataFrame的特性,对提取出的某一列的修改会影响到主表的值。当需要独立修改列提取出来的列数据时,可以采用copy()函数。
names = df.name.copy()
names[0] = '张三'
names
df
0 张三
1 李四
2 王五
3 赵六
Name: name, dtype: object
1.3 列操作
包括对列的增、删、改、查
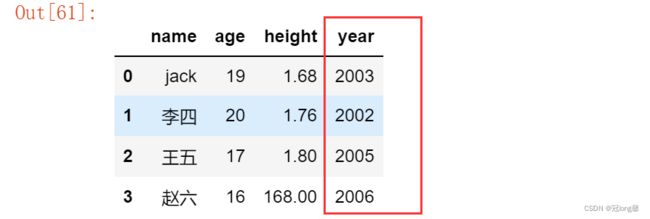
1. 增加列
直接通过索引值新增一列
import datetime # 获得出生年月
df['year'] = datetime.datetime.now().year - df.age
df
2. 删除指定列
df.drop(索引,axis = 1):axis默认为0,表示行。
df1 = df.drop('year', axis = 1) # 默认为0,删除列时需要指定为1
df1
注意:drop()函数不会改变调用对象本身,获得值需要使用新的变量保存

3. 修改某列元素
通过[]或[[]]得到某列后,修改指定元素。这次修改会影响到DataFrame。
4. 查看某列元素
使用“[]”或“[[ ]]”以Series或DataFrame的格式输出某一列或几列
1.4 行操作
包括对行的增、删、改、查
1. 在指定位置增加行
.loc[]能够返回指定索引值行的元素。DataFrame[]可以直接操作列元素,操作行元素时需要添加loc[]函数
# 在最后一行插入
df.loc[df.shape[0]] = {'age':21,'name':'LongXin','height':1.76,'year':2001}
df

2. 删除指定行
- 通过.drop()函数,删除指定索引的行
df = df.drop(df.shape[0]-1, axis =0)
df = df.drop(2, axis =0)
df
删除后,行索引中缺少了2,因此需要重新更新行索引

- 通过index函数,重新恢复行索引
df.index = range(df.shape[0])
df
3. 查找某行元素
- loc[]: 根据自定义的索引值查找,行索引中必须有指定索引值,否则会发生报错。
- iloc[]: 根据物理位置的索引值查找,行索引中不一定有指定索引值
1.5 行-列
当我们希望找到指定行、指定列时,可以采用loc[]结合行索引和列索引、iat[]直接索引
例如,我们想获得倒数2行,'age’和’name’列的数据
df.loc[df.index[-2:], ['name', 'age']]
df

df1
df1.iat[1,1] = 66
df1

1.6 数据筛选
- 筛选指定范围数据
- 筛选指定元素数据
- [ ], loc
- query(’’)
- isin
(1)筛选指定范围数据
可以使用[], loc, query()三种方法筛选出指定范围的数据。
方法一:[ [判断语句] ]嵌套
将复合条件的所有行的所有列输出
df['height'] >= 1.65
df[df['height'] >= 1.65]
0 True
1 True
2 True
3 True
4 True
Name: height, dtype: bool

方法二:loc(判断语句,指定列)
在[ [ ] ]的基础上,可以输出复合条件的所有行的指定列元素。
df.loc[(df['height'] >= 1.65)&(df['age']<=20),['name', 'age', 'height']]

方法三:query(‘字符串’)
通过判断字符串,输出符合条件的数据。效果与[ [判断] ]相同。
df.query('height >=1.65 and age <=20 or name == "jack" ')
age = 20
df.query('age < @age') # @变量


方法四:isin()
判断元素是否在指定列中,然后返回指定元素
# isin() 判断元素是否存在
df['age'].isin([18,19])
df[df['age'].isin([18,19])]
0 True
1 False
2 False
3 False
4 False
Name: age, dtype: bool

2. 加载数据
- Text
- CSV
- Excel
- Html
- MySQL
2.1 Txt
通过pd.read_table函数可以读取txt文件,其中有如下重要参数
- sep:默认为tab,指定分割符
- header:默认第一行为列名,选择None可以取消
- names:人为设定列名,默认为0-n
pd.read_table('D:\\Jupyter_notebook\\pandas_data\\03.txt', sep = ':', header =None )
pd.read_table('D:\\Jupyter_notebook\\pandas_data\\03.txt', sep = ':', header =None, names = ['name', 'pwd', 'uid', 'gid', 'local', 'home', 'shell'] )
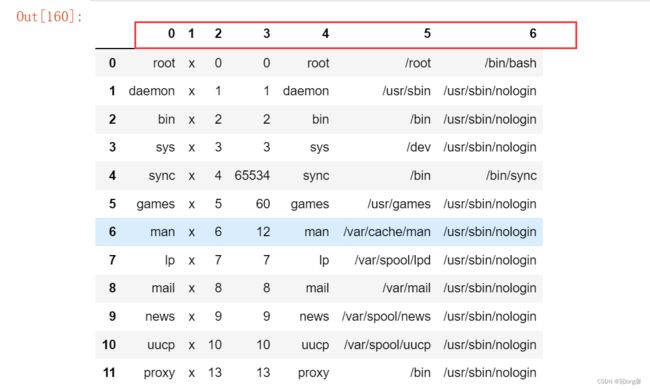
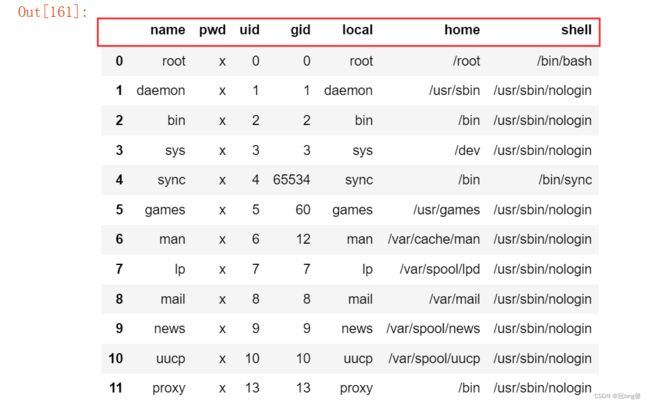
2.2 Csv
通过pd.read_csv文件读取,csv文件是以,为分割符的文件。重要参数如下
- header:默认第一行为列名,选择None可以取消
# csv 数据由,进行分割
pd.read_csv('D:\\Jupyter_notebook\\pandas_data\\04.csv')

Excel
需要引入xlrd包,通过pd.read_excel()读取excel文件。重要参数如下:
- header:默认第一行为列名,选择None可以取消
# Excel
import xlrd
pd.read_excel('D:\\Jupyter_notebook\\pandas_data\\05.xlsx')

3. 排序与合并
- Sort
- rank
- merge
- Concat
3.1 Series排序
- sort_index(ascending = True):按序号排序,默认为True即按升序
- sort_values(ascending = True):按值排序,默认为True即按升序
3.2 DataFrame排序
- sort_index(axis = 0, ascending = True):按行或列序号排序(0 or 1),默认为1 and True即按行序号的升序
- sort_values(by = [], ascending = True):按指定列的值排序,默认为True即按升序
df = pd.DataFrame(arr, index = [0,2,1], columns = list('cab'))
# 单独对DataFrame的某一列排序
df.sort_values(by = ['c','a'], ascending = False)


3.3 Rank
获得每个元素在对应列从小到大的排序。常见参数如下:
- method = ‘average’
‘average’:当大小相同时,取平均值为序
‘max’:当大小相同时,取最大序号
‘min’:当大小相同时,取最小序号
‘first’:当大小相同时,按照在内存中的存储顺序为序
df.rank() # 获得每个元素在对应列按照从小到大的排名
df.rank(method = 'first') # 默认为average, first表示相同时按内存先后进行排序
df.rank(method = 'min') # min max表示相同时取min or max
df.rank(method = 'max') # min max表示相同时取min or max
3.4 merge(按列匹配合并)
- pd.merge(df1, df2, on = ‘X’, how = ‘inner’)
将df1, df2按照X属性合并。可能的方法有inner_join(只有匹配的项), left_join(df2对df1进行描述), right_join(df1对df2进行描述), outer_join(包含所有项,无匹配项的为NaN)。
inner只输出匹配的项,left, right输出指定项,outer输出所有项。
df1 = pd.DataFrame({
'number': ['s1', 's2', 's1', 's3', 's1', 's1', 's2', 's4'],
'score': np.random.randint(50, 100, size = 8),
})
df1
df2 = pd.DataFrame({
'number': ['s1', 's2', 's3', 's5'],
'name': ['张三', '李四', '王五', '赵六']
})
df2


pd.merge(df1, df2, on = 'number') # inner_join 连接方式

pd.merge(df1, df2, on = 'number', how = 'left') # 左连接

pd.merge(df1, df2, on = 'number', how = 'right') # 右连接
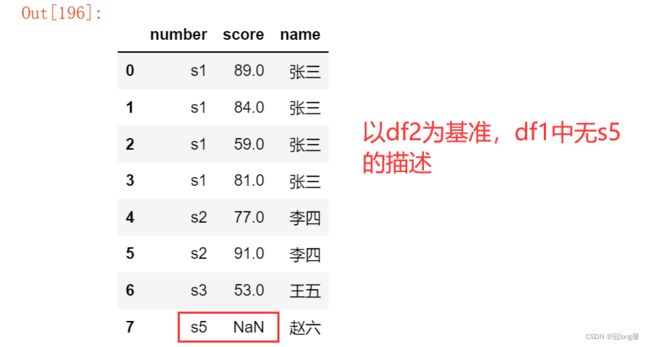
pd.merge(df1, df2, on = 'number', how = 'outer') # 右连接

3.5 concat(数据的拼接)
当我们有多个表格需要拼接到一块儿时,可以采用concat进行表格拼接
- concat([df1, df2], axis = 0)
将df1, df2纵向(axis = 0默认)或横向(axis = 1)拼接
data = np.arange(1, 5).reshape(2,-1)
df1 = pd.DataFrame(data)
df2 = pd.DataFrame(np.zeros((2,2)))
# 数据的拼接
pd.concat([df1, df2])
# 数据的拼接
pd.concat([df1, df2], axis = 1)


4. 数据汇总
- describe
- info
- count
- mean
- sum
数据处理步骤
- 数据初探:通过head(5), tail(5)查看首尾元素,了解数据结构。
- 特殊值查看:通过info(), describe()查看包括NaN、元素个数、标准差、中位数等特殊数值
4.1 特殊值(info, describe)
data = [
[1, None],
[None, None],
[8, 9],
[3, 4]
]
df = pd.DataFrame(data, columns = ['a', 'b'])
# 数据处理第一步:数据结构+特殊值 head() -> info() --> describe()
df.info() # 行列、数据类型、None值个数及列分布、内存占用
df.describe() # 数据个数、分布描述


4.2 分组统计
DataFrame可用通过groupby(‘X’)函数,以X或[X,…]为列别将DataFrame进行划分。通过对不同的分类层数使用如sum(), max()等函数,统计各个类别的数量。还可以通过for循环,输出分类结果。
import xlrd
df = pd.read_excel('D:\\Jupyter_notebook\\pandas_data\\data.xlsx')
df

# 分类统计
grouped = df.groupby('类别')
for name, data in grouped:
print(name)
print(data)
# 各类别所属元素
for name, data in grouped:
print(name)
print(data['名称'].unique())
服装
日期 名称 类别 单价 数量 金额
0 2018-07-01 商品A 服装 20 2 40
1 2018-07-02 商品B 服装 200 3 600
3 2018-07-04 商品A 服装 22 5 110
4 2018-07-05 商品B 服装 220 6 1320
6 2018-07-07 商品A 服装 30 3 90
7 2018-07-08 商品A 服装 800 1 800
9 2018-07-10 商品B 服装 230 3 690
10 2018-07-11 商品A 服装 28 1 28
食品
日期 名称 类别 单价 数量 金额
2 2018-07-03 商品C 食品 1200 4 4800
5 2018-07-06 商品C 食品 1000 7 7000
8 2018-07-09 商品C 食品 1300 4 5200
服装
[‘商品A’ ‘商品B’]
食品
[‘商品C’]
grouped = df.groupby(['类别', '名称'])
grouped[['单价']].max()

5. 时间序列
- datetime
- time
- date_range:date_range(start, end, freq= , periods=)生成时间序列
- to_datetime:将date_range()产生的时间序列转换为时间索引
- set_index
- resample:重新采样,重新组织时间序列的采样频率
5.1 初始化时间序列
Pandas使用pd.date_range()初始化时间序列。有两种初始化方法。
- 指定起止时间
- 指定开始时间与需要个数
其中date_range()包含两个重要参数:
- freq = ‘D’:设置序列频率。默认为D一天为单位,常见有 ‘w’:周,‘M’:月,‘Q’:季度,‘H’:时,‘T’:分,‘S’:秒
- period:指定序列个数
pd.date_range('2018-5-1', '2020-2-15',freq = 'Q')
# 未知起始日期,指定periods长度
pd.date_range('2020-05-01', freq = 'Q', periods = 10)


5.2 时间索引
由date_range生成的时间序列不能直接作为时间索引。需要==to_datetime()==函数将其转换为索引。
将时间转换为索引后,对时间引用的便捷程度将大大提升。
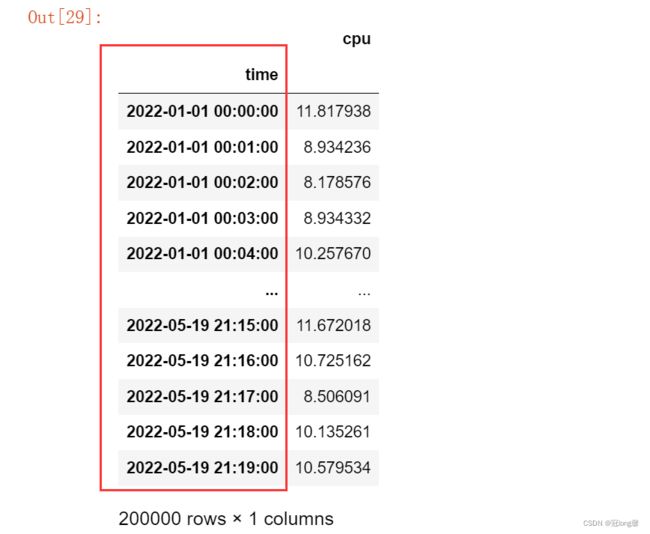
from datetime import datetime
import numpy as np
data = {
'time': pd.date_range('2022-01-01', periods = 200000, freq = 'T'),
'cpu' : np.random.randn(200000) + 10
}
df = pd.DataFrame(data)
df
# 让时间作为索引
s = pd.to_datetime(df.time)
df.index = s
df = df.drop('time', axis = 1)
df

某一时间段
df['2022-02-03 08:30:00':'2022-03-03 08:30:00']

指定时间
df['2022-02-15']

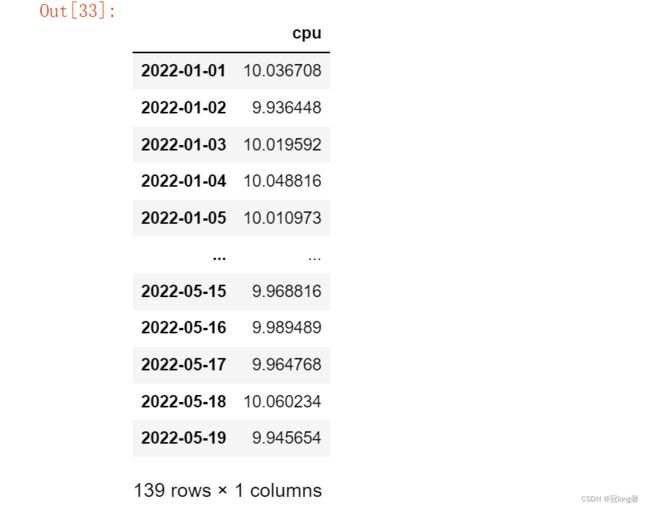
分组
df.groupby(df.index.date).mean() # date 天分组
5.3 重采样
通过resample()函数对时间序列进行重采样,其中常见参数:
- ‘nT’:表示以n分钟的频率重采样。常见的还有’H’, ‘S’, ‘Q’, ‘W’, ‘D’
# 重采样
df.resample('5T').mean()

参考资料
[1] https://edu.csdn.net/learn/26273/326984