VMware和ubuntu配置Hadoop环境
目录
一、获取VMware安装包
1、官网获取
1)首先先进入官网,官网首页是下面这样:
2)接着点击产品选项
3)进入后点击查看所有产品,然后在右上角选择排序方式为Z到A,然后向下滑动找到Workstation Pro,然后点击进去
4)然后点击下载试用版进行进入下载页面进行下载
5)点击 DOWNLOAD NOW 进行下载
2、从资料获取
二、安装VMware
1)点击下一步
2)勾选我接受许可协议中的条款,并点击下一步
3)勾选就按默认的勾选就ok,安装位置选一个自己需要安装的位置,然后点击下一步
4)这里的勾选根据自己的需要进行勾选(我这边是取消全部的勾选),并点击下一步
5)按默认的勾选就行,并点击下一步
6)点击安装,等待安装完成
7)安装完成后,运行VMware
8)输入密钥:MC60H-DWHD5-H80U9-6V85M-8280D,并点击继续
9)点击完成
10)点击完成后的界面如下
三、下载Ubuntu镜像文件
1、官网下载
2、从资料获取
四、开始配置Hadoop环境
1)首先打开安装好的VMware,并点击创建新的虚拟机
2) 出现下面界面,点击下一步(默认勾选的就ok)
3)勾选稍后安装操作系统,并点击下一步
4)然后选择并配置好下图的配置,并点击下一步
5)编辑自己想要的虚拟机名称,并选择位置,然后点击下一步
6)磁盘空间自行分配(本人分配40G),勾选将虚拟磁盘存储为单个文件,然后点击下一步
7)点击自定义硬件
8)内存分配2048MB(内存根据需要自行分配,最少1024MB),然后选择 新 CD/DVD,勾选使用 ISO 映像文件(之前下在好的文件),然后关闭
编辑 9)点击完成,之后出现下面界面,点击开启此虚拟机
10)按下Enter键
11)选择自己需要的语言后,并点击安装 Ubuntu 编辑
12)选择默认勾选就可以,然后点击继续
13)默认勾选就行,然后点击继续
14)默认勾选就ok,点击现在安装
15)点击继续
16)点击继续
17)输入自己需要的姓名和密码,并勾选自动登录,然后点击继续,会出现以下界面,等待这个过程完成
18)按住 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 hadoop :
19) 输入下面的命令,为创建的用户 hadoop 设置密码 hadoop(这里密码可自己设置):
20)使用下面的命令设置密码,可以简单设置为 hadoop
21)为了方便部署,使用下面命令为 hadoop 用添加管理员权限
22)注销当前用户(注销位置在右上角那),使用刚才创建的用户登录
23)登录进去后,打开命令窗口,首先使用下面命令对软件进行更新
24)使用下面命令安装 openssh -server
25)ssh每次登录还是需要密码。我们使用下面这些命令配置成无密码登录
26)安装JAVA 环境
27)安装 Hadoop
28)Hadoop 伪分布式配置
本博客主要是为了学校课程”大数据与云计算“需要安装Hadoop而写,希望这篇博客对各位阅读这篇博客的人有所帮助。废话不多说,下面直接开始配置教程。
一、获取VMware安装包
VMware获取方法有很多种,这里我准备了官网获取和从我准备的资料中获取。
1、官网获取
1)首先先进入官网,官网首页是下面这样:
2)接着点击产品选项
3)进入后点击查看所有产品,然后在右上角选择排序方式为Z到A,然后向下滑动找到Workstation Pro,然后点击进去

4)然后点击下载试用版进行进入下载页面进行下载
5)点击 DOWNLOAD NOW 进行下载
2、从资料获取
阿里云盘:https://www.aliyundrive.com/s/nVT1oCtk6rC
提取码:4pu8
二、安装VMware
点击下载好的VMware安装包进行安装。

1)点击下一步
2)勾选我接受许可协议中的条款,并点击下一步

3)勾选就按默认的勾选就ok,安装位置选一个自己需要安装的位置,然后点击下一步
4)这里的勾选根据自己的需要进行勾选(我这边是取消全部的勾选),并点击下一步
5)按默认的勾选就行,并点击下一步
6)点击安装,等待安装完成

7)安装完成后,运行VMware
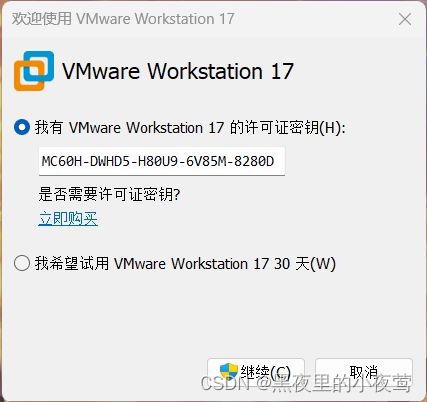
8)输入密钥:MC60H-DWHD5-H80U9-6V85M-8280D,并点击继续
9)点击完成

10)点击完成后的界面如下
 三、下载Ubuntu镜像文件
三、下载Ubuntu镜像文件
1、官网下载
官网:Download Ubuntu Desktop | Download | Ubuntu
官网界面如下:
1)点击右下角的 Download 22.03.3 进行下载(LTS是长期支持版本,选择这个版本),并等待下载完成
2、从资料获取
阿里云盘:https://www.aliyundrive.com/s/nVT1oCtk6rC
提取码:4pu8
四、开始配置Hadoop环境
1)首先打开安装好的VMware,并点击创建新的虚拟机
2) 出现下面界面,点击下一步(默认勾选的就ok)

3)勾选稍后安装操作系统,并点击下一步

4)然后选择并配置好下图的配置,并点击下一步

5)编辑自己想要的虚拟机名称,并选择位置,然后点击下一步

6)磁盘空间自行分配(本人分配40G),勾选将虚拟磁盘存储为单个文件,然后点击下一步
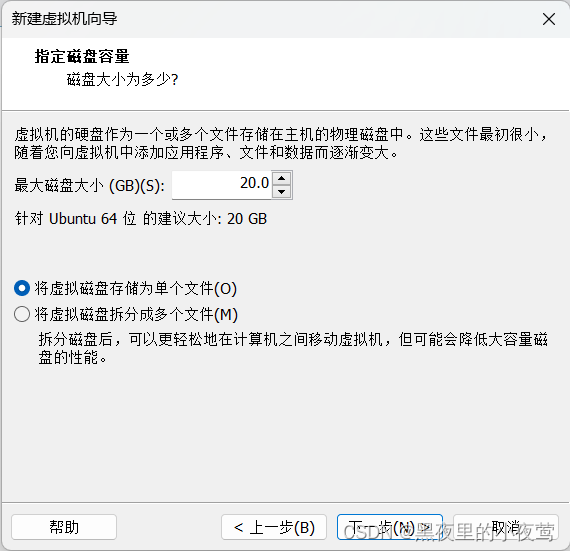
7)点击自定义硬件

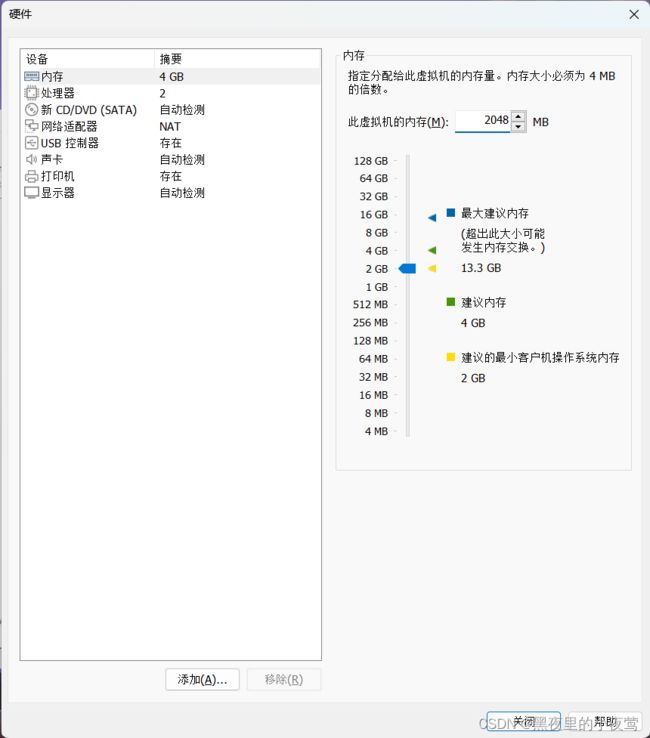
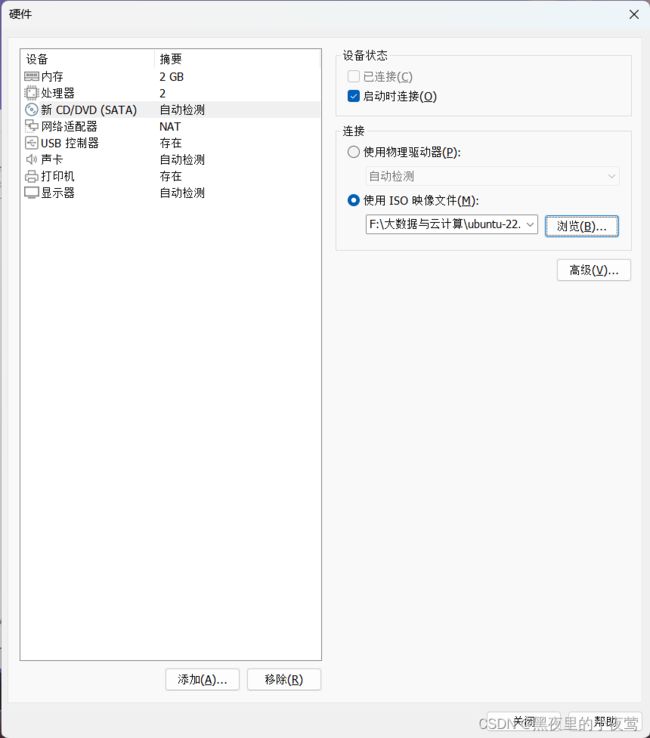
8)内存分配2048MB(内存根据需要自行分配,最少1024MB),然后选择 新 CD/DVD,勾选使用 ISO 映像文件(之前下在好的文件),然后关闭
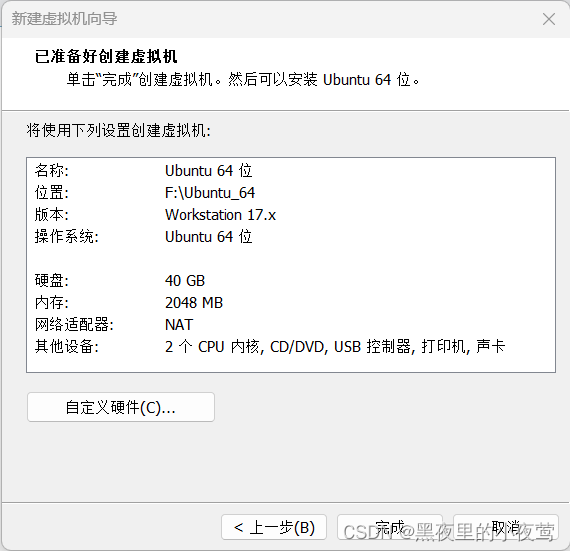
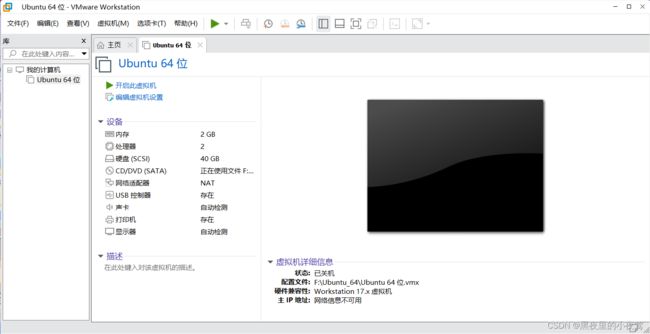
 9)点击完成,之后出现下面界面,点击开启此虚拟机
9)点击完成,之后出现下面界面,点击开启此虚拟机
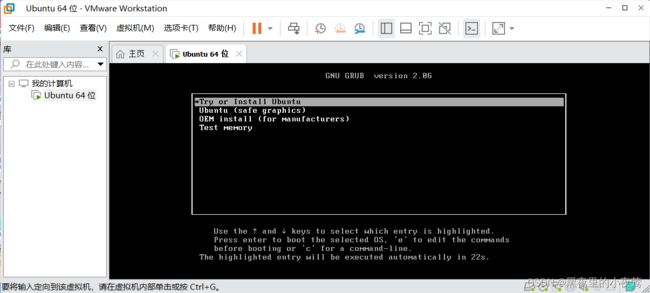
10)按下Enter键
11)选择自己需要的语言后,并点击安装 Ubuntu 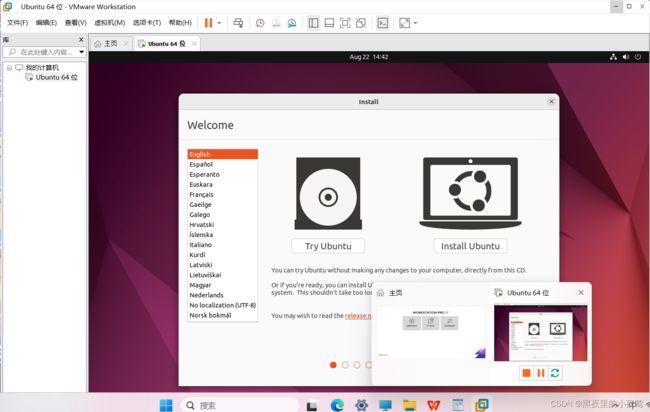
12)选择默认勾选就可以,然后点击继续
13)默认勾选就行,然后点击继续
14)默认勾选就ok,点击现在安装
15)点击继续

16)点击继续
17)输入自己需要的姓名和密码,并勾选自动登录,然后点击继续,会出现以下界面,等待这个过程完成
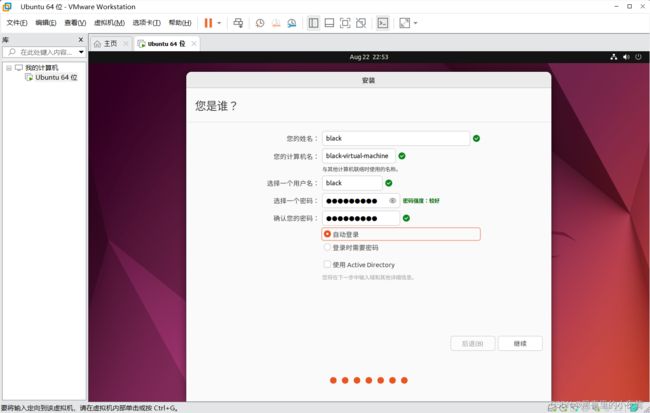

18)按住 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 hadoop :
sudo useradd –m hadoop –s /bin/bash

注:这里的密码是我们创建的用户密码(我这里创建的是 blue 用户)
19) 输入下面的命令,为创建的用户 hadoop 设置密码 hadoop(这里密码可自己设置):
sudo passwd hadoop
20)使用下面的命令设置密码,可以简单设置为 hadoop
sudo passwd hadoop
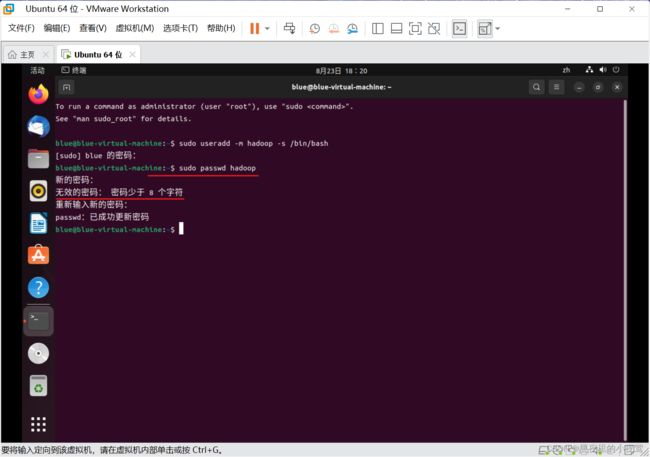
注:
1. 这里输入的密码是不可见的,直接输入就可以
2.如果出现 无效密码: 密码至少 8 个字符,只需要把之前设置的密码重新输入即可
21)为了方便部署,使用下面命令为 hadoop 用添加管理员权限
sudo adduser hadoop sudo
22)注销当前用户(注销位置在右上角那),使用刚才创建的用户登录
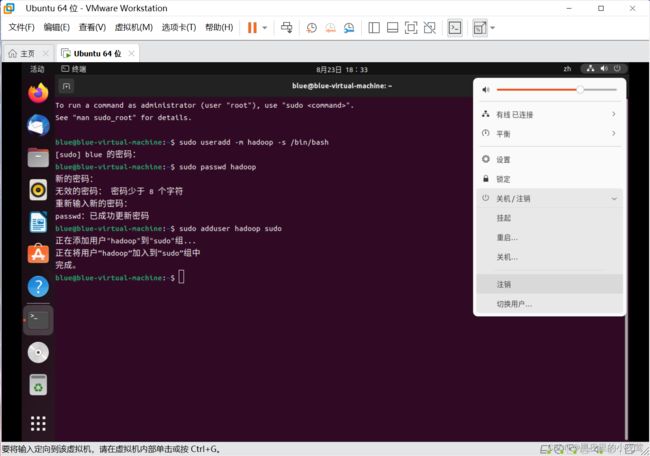
选择刚才我们创建的用户(这里为 hadoop)

输入为用户 hadoop 设置的密码,登录进去

23)登录进去后,打开命令窗口,首先使用下面命令对软件进行更新
sudo apt-get install
24)使用下面命令安装 openssh -server
sudo apt-get install openssh-server
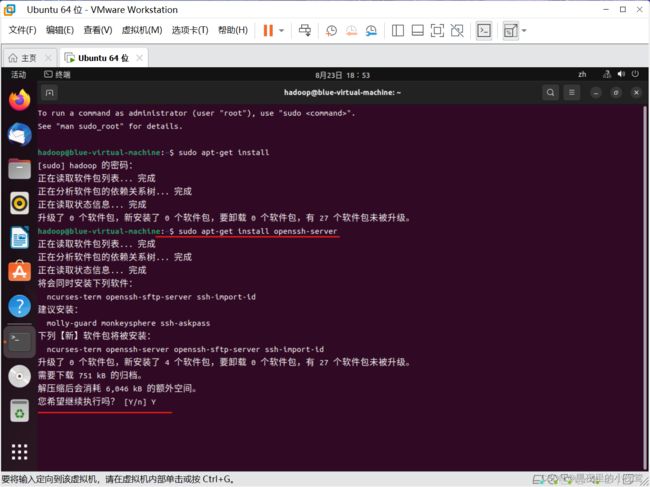
注:如果出现 您希望继续执行吗?[Y/n] ,输入 Y 并按 Enter
25)ssh每次登录还是需要密码。我们使用下面这些命令配置成无密码登录
首先,使用下面命令实现 ssh 首次登录
ssh localhost

注:
1.选择 yes
2.密码输入我们创建 hadoop 设置的密码
使用下面命令退出刚才登录的 ssh,回到我们原先的终端窗口
exit使用下面命令,进入 ssh 目录里
cd ~/.ssh/利用 ssh-keygen 生成密钥
ssh-keygen –t rsa #会有提示,按回车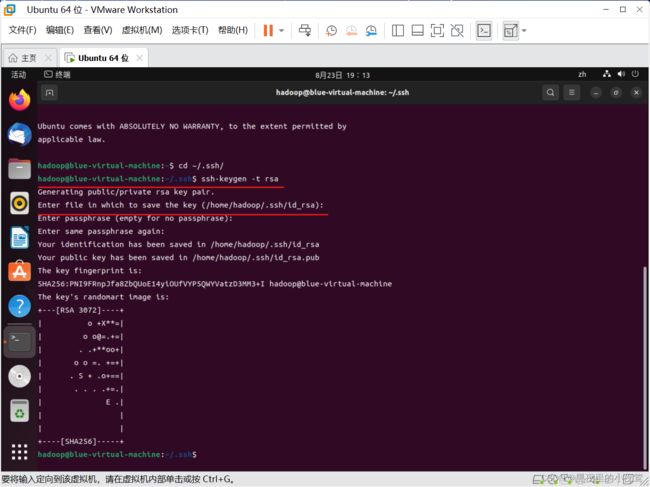
利用下面命令将密码加入到授权中,此时再使用 ssh localhost 命令就不用登录密码
cat ./id_rsa.pub >> ./authorized_keys #加入授权26)安装JAVA 环境
使用下面命令安装 jdk
sudo apt-get install openjdk-8-jdk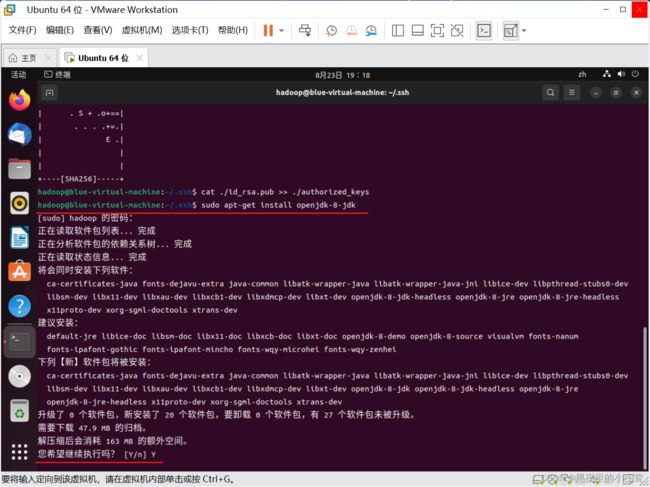
使用下面命令查看Java版本,看看是否安装成功
java -version
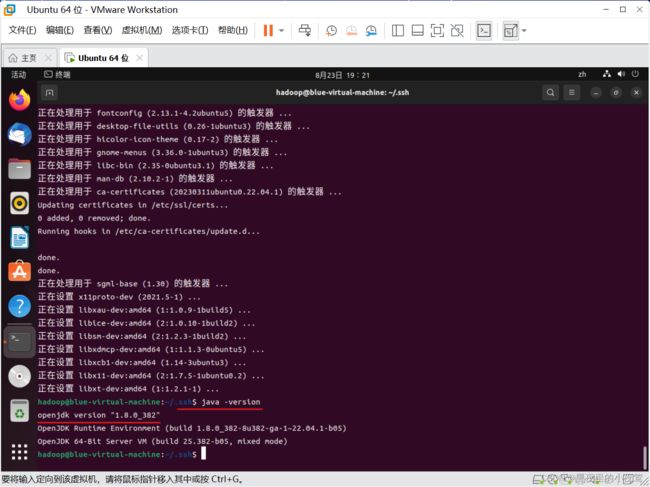
使用下面命令进入文件并配置 JAVA_HOME
gedit ~/.bashrcexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# = 左右不能有空格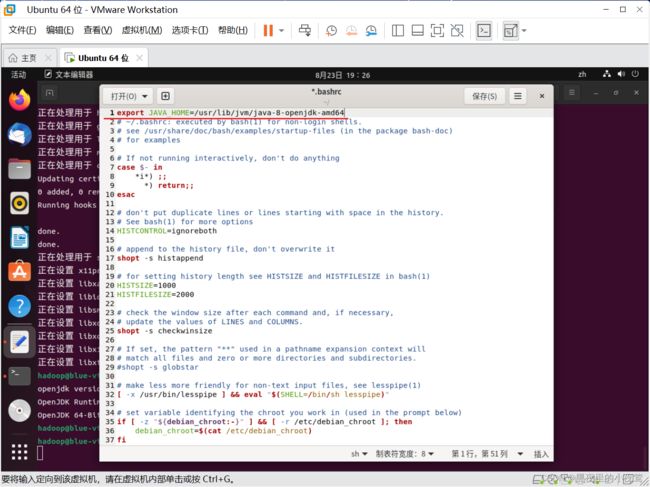
注:修改后记得点击保存,然后点击关闭
使用下面命令使上面编辑的环境变量生效
source ~/.bashrc使用下面的命令,看我们设置的环境变量是否生效
echo $JAVA_HOME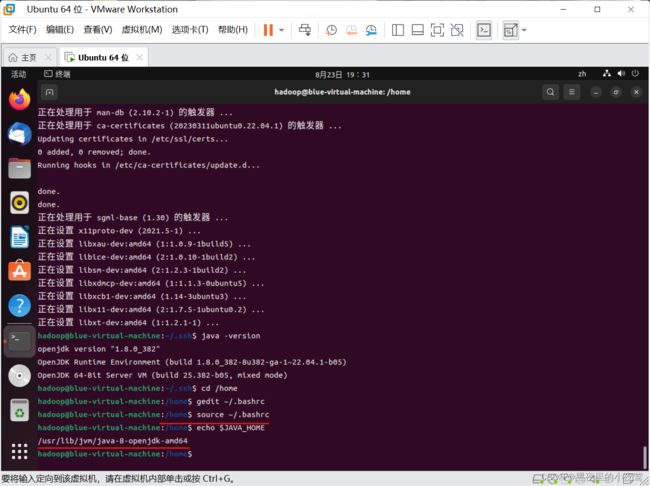
27)安装 Hadoop
Hadoop的安装包可以去官网安装,但是由于官网的下载速度不行,这里提供一个镜像网站进行下载Hadoop。
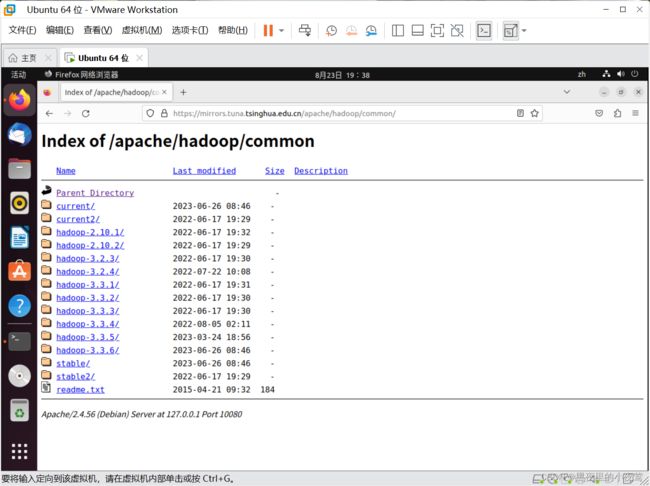
镜像网址:Index of /apache/hadoop (tsinghua.edu.cn)
进入此网站后,选择 common/

然后选择自己需要的版本进行下载,但注意选择扩展名为 .tar.gz 这个格式的,这是编译好的。我这里下载的版本是 hadoop-2.10.2.tar.gz
 下载完成后,使用下面命令进行解压操作(将原先的命令窗口关闭再打开,然后输入下面命令)
下载完成后,使用下面命令进行解压操作(将原先的命令窗口关闭再打开,然后输入下面命令)
sudo tar -zxf ~/下载/hadoop-2.10.2.tar.gz -C /usr/local # 解压到/usr/local中
# 版本是自己下载的对于版本,我这里是 hadoop-2.10.2注:
1.切换 中\英文 的方式为 super + space
windows:win + 空格
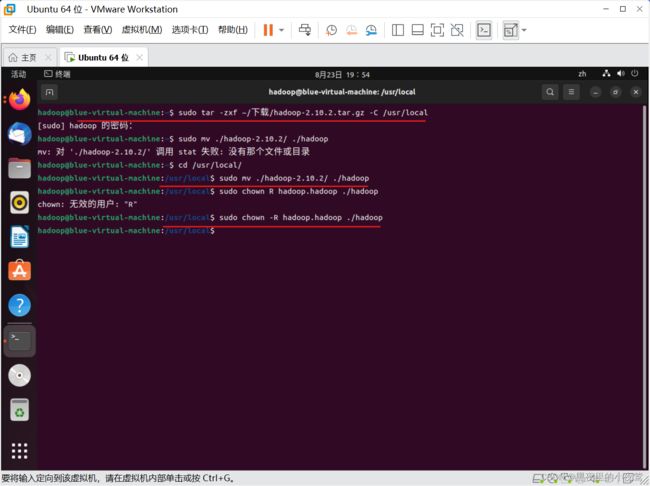
先使用下面命令进入文件夹(必须在使用命令将文件夹改名前,使用此命令)
cd /usr/local/
使用下面的命令,将文件夹名改为 hadoop
sudo mv ./hadoop-2.10.2/ ./hadoop # 将文件夹名改为hadoop使用下面命令修改文件权限
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
先使用下面命令进入到hadoop 文件夹
cd /usr/local/hadoop然后用如下命令查看我们解压的Hadoop是否可用
./bin/hadoop version

28)Hadoop 伪分布式配置
Hadoop 伪分布式配置需要修改core-site.xml和hdfs-site.xml配置文件。先使用下面命令进入到hadoop 文件夹
cd /usr/local/hadoop使用下面命令对core-site.xml文件进行配置
gedit ./etc/hadoop/core-site.xml利用下面代码进行配置core-site.xml文件(注意点击保存)
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000

使用下面命令对hdfs-site.xml文件进行配置
gedit ./etc/hadoop/hdfs-site.xml利用下面代码进行配置hdfs-site.xml文件(注意点击保存)
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data

配置完成后,执行 NameNode 的格式化
./bin/hdfs namenode -format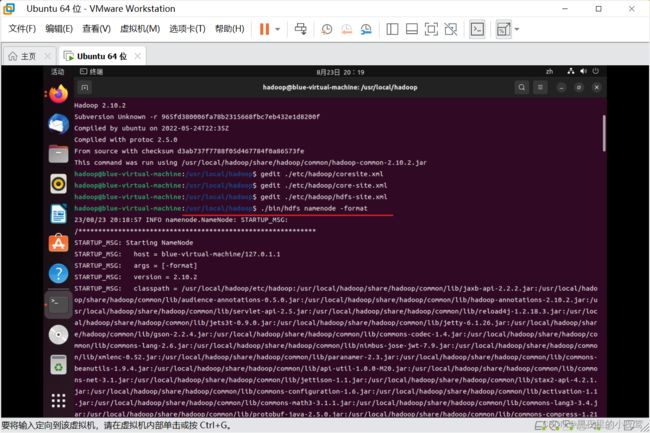
接着使用下面命令开启 NameNode 和 DataNode 守护进程
./sbin/start-dfs.shjps # 判断是否成功启动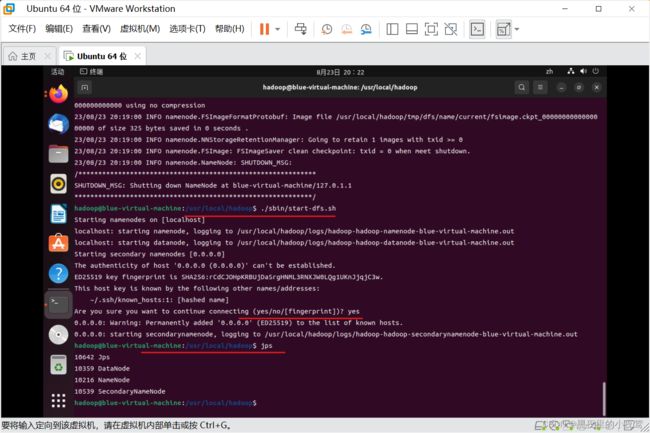
然后在浏览器输入下面网址,访问 Web 界面
http://localhost:50070
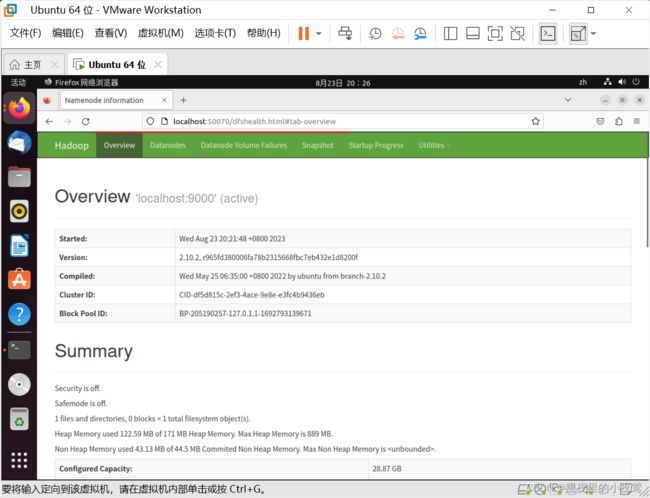
注:
Hadoop 3.x 起,启动端口变成了9870,而不是50070.(我下载的 Hadoop 2.x,故用端口 50070)
至此,配置完成,各位观看老爷感觉不错的话,能留下一个小小的点赞不过分吗,同时也希望各位生活愉快、事事顺心。
