Ubuntu下Hadoop的单机安装
云计算实验中要求我们在Linux系统安装Hadoop,故来做一个简单的记录。
· 注:我的操作系统环境是Ubuntu-20.04.3,安装的JDK版本为jdk1.8.0_301,安装的Hadoop版本为hadoop2.7.1。(不确定其他版本是否会出现版本兼容问题)
Hadoop安装步骤如下:
一、更新apt和安装vim编辑器
二、配置本机无密码登录SSH
三、安装JAVA环境
四、下载安装Hadoop
五、伪分布式搭建
一、更新apt和安装vim编辑器
1、更新apt
sudo apt-get update2、安装vim编辑器
sudo apt-get install vimapt更新和vim安装可能会有点慢,不用着急。
二、配置本机无密码登录SSH
1、先检查ssh是否已经安装启动【最好检查一下】
sudo ps -ef | grep ssh2、Ubuntu默认已安装ssh客户端,此外还要安装ssh服务端
sudo apt-get install openssh-server这里在安装服务端时没有进行截图。但是当时在做这一步时报错了。将最后的报错中的语句添加到这句命令末尾解决了该问题(如果遇到一样的状况可以试试)。
3、安装后登录SSH(首次登陆会有提示,按提示输入yes和用户密码就可以登录了)
ssh localhost4、退出登录
exit设置无密码登录,使用ssh-keygen 生成密钥,并将密钥加入到授权中
cd ~/.ssh/
ssh-keygen -t rsa # 什么都不用输,根据提示一直按ENTER就行
cat ./id_rsa.pub >> ./authorized_keys以上步骤完成后就可以无密码登录SSH了。
三、安装JAVA环境
1、安装JDK
我下载的是jdk1.8.0_301版本,在本机电脑中下载压缩包,将压缩包复制到/home/user【就是桌面上的文件夹】文件夹中,右键解压到当前位置。(就不用终端输命令来进行了)
——这里再说一下从本机复制粘贴的问题。
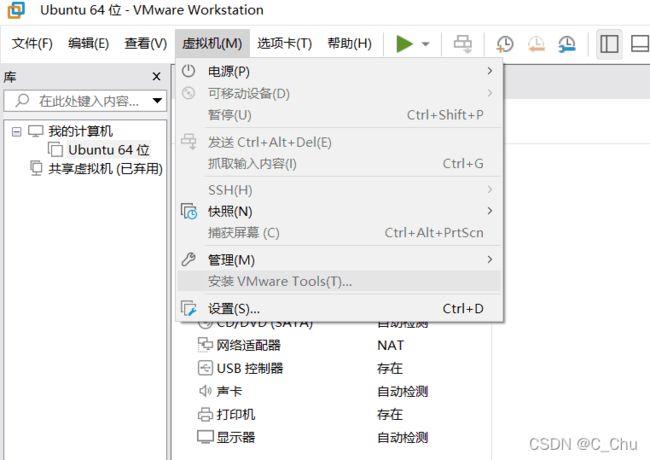
想要复制粘贴就需要在VMware中安装VMware tools。进入虚拟机后点击“安装VMware tools”,会弹出一个光盘,点进去找到一个压缩包,将他复制到主目录后解压。
进入解压文件夹后,会有一个vmware-install.pl文件,在终端里打开:
sudo ./vmware-install.pl后面一直按ENTER,(如果遇到默认【no】的话,输入y再回车)安装完后会出现“enjoy”,那就安装完了。重启后看看能不能拖动或者复制粘贴实现本机与虚拟机的文件传递。【基本是没问题了】
但是也不排除安装完后仍然存在无法复制粘贴的可能性。可以尝试卸载重装vmtools,如果仍然没有解决,那可以尝试一下下面这个方法:
——打开终端输入:
apt-get install open-vm-tools-desktop fuse # 如果报错就在前面加 sudo按照提示确认替换,这样安装open-vm-tools替代vmtools就好啦。
(看到有说重装虚拟机可以解决但对我来说太麻烦了,实在不行的可以试试。)
2、配置JDK环境
sudo gedit ~/.bashrc # 用gedit编辑器编级环境变量
sudo vi ~/.bashrc # 如果没安装gedit,可以使用vi编辑器编辑在编辑器末尾添加一下内容(按i可以进行修改):
export JAVA_HOME=/home/user/jdk1.8.0_301 # 这是你放JDK的位置以及版本,自行修改
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH修改完后按ESC,输入“:wq!” ,即可保存bashrc.pl文件,使刚加入的环境变量生效:
source ~/.bashrc3、检验安装
java -version结果如下图所示即可

四、下载安装Hadoop
在/home/user下新建目录Hadoop,在/home/user/hadoop目录下右键解压hadoop-2.7.1.tar,ls看到当前目录下出现hadoop-2.7.1/目录则解压成功。
检验安装:
./bin/hadoop version结果如下图所示即可:

五、伪分布式搭建
1、环境变量修改
在/home/user/hadoop/hadoop-2.7.1/下建立两个目录:tmp和data,tmp用于存放中间数据,data用于存放上传的测试数据。
在/home/user/hadoop/hadoop-2.7.1/etc/hadoop中找到hadoop-etv.sh文件,对其中的JAVA_HOME行进行修改:
export JAVA_HOME=/home/user/jdk1.8.0_301 # 根据自己情况修改2、Hadoop运行参数配置
在/home/user/hadoop/hadoop-2.7.1/etc/hadoop目录下找到以下文件,并进行修改。
①core-site.xml
配置默认文件系统的地址和端口号,还有临时目录的位置。
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/user/hadoop/hadoop-2.7.1/tmp // 根据自己情况修改
②hdfs-site.xml
配置默认文件系统的默认副本数,这里因为使单节点所以副本数设置为1。
dfs.replication
1
③mapred-site.xml
需要修改mapred-site.xml.template文件,即执行命令:
mv mapred-site.xml.template mapred-site.xml配置mapreduce程序运行的框架,这里配置为yarn
mapreduce.framework.name
1
④yarn-site.xml
其中,yarn.resourcemanager.hostname配置的是主机标识符;yarn.nodemanager.aux-services配置的是NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。【以下修改,后期应该可以链接到8088】
yarn.resourcemanager.hostname
user-KVM # 这里根据自己情况改
yarn.nodemanager.aux-service
mapreduce-shuffle
yarn.resourcemanager.address
localhost:8032
yarn.resourcemanager.scheduler.address
localhost:8030
yarn.resourcemanager.resource-tracker.address
localhost:8031
yarn.resourcemanager.admin.address
localhost:8033
yarn.resourcemanager.webapp.address
localhost:8088
3、系统启动
①文件系统格式化
首次安装需要先格式化文件系统,需执行命令:
./bin/hadoop namenode -format看到Exiting with status 0的字样则证明格式化成功。
②启动文件系统
在/home/rc/hadoop/hadoop-2.7.1下执行:
./sbin/start-dfs.sh③启动yarn资源管理系统
在/home/rc/hadoop/hadoop-2.7.1下执行:
./sbin/start-yarn.sh 同样的,执行完成后使用jps命令检查是否成功,如果有ResourceManager和NodeManager进程则成功。如果start-dfs.sh和start-yarn.sh脚本都启动成功,说明hadoop的单机版启动成功了。 
ps:没问题的话应该会有上图的六个进程。
4、启动
在/home/rc/hadoop/hadoop-2.7.1下执行:
./sbin/start-all.sh上述线程均存在,然后去访问http://localhost:8088/

以上,Ubuntu单机安装Hadoop就成功了。