(小白全过程记录)Ubuntu下伪分布式Hadoop环境搭建
目录
0.准备
1.Hadoop伪分布式环境搭建
2.安装ssh,配置ssh无密码登录
3.通过拖拽的方式将文件从windows传到linux桌面
5.安装hadoop
6.修改hadoop环境变量
7.修改配置文件 core-site.xml
8.修改配置文件hdfs-site.xml文件
9.执行NameNode的格式化
10.开启NameNode和DataNode守护进程
11.访问web页面
12.关闭Hadoop
0.准备
已经按照《(小白全过程记录)Ubuntu-14.04.5虚拟机安装》篇成功在虚拟机上安装Ubuntu。
1.Hadoop伪分布式环境搭建
(1)运行虚拟机
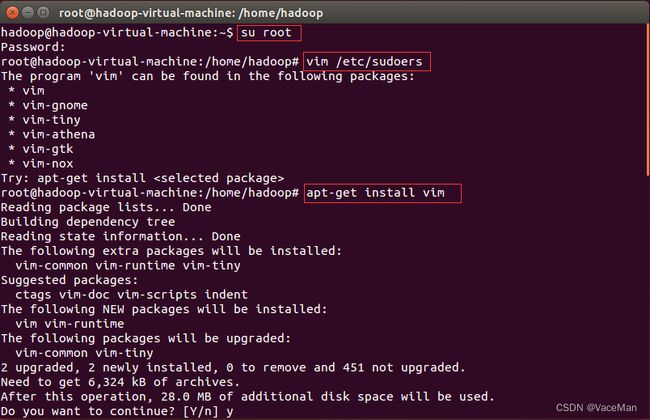
(2)以root登录,为普通用户hadoop进行授权。
#切换root用户
su root
#编辑sudoers文件,最后一行添加"hadoop ALL=(ALL:ALL) ALL"
vim /etc/sudoers
#添加下面的语句
hadoop ALL=(ALL:ALL) ALL#我安装的这个ubuntu没有vim,需要使用apt-get安装,vim apt-get install vim

2.安装ssh,配置ssh无密码登录
(1)安装、启动ssh服务器
#root账户下
apt-get install openssh-server
#普通用户(hadoop),步骤1中已为hadoop账户授权,hadoop账户可以通过sudo执行apt-get命令
sudo apt-get install openssh-server
#启动ssh服务器
service ssh start
刚刚安装好ssh时,LINUX系统还没有把SSH放进service 列表里,2个解决方法:
(1)重启虚拟机
(2)根目录下,执行./etc/init.d/ssh start
#重启服务器
#再次启动ssh服务器
service ssh start
#嗨,还是报错,使用方法2
./etc/init.d/ssh start
#检验:检查有没有sshd
ps -e | grep ssh
(2)配置
ssh localhost发现建立链接失败,输入yes看一看,发现还需要输入密码,但是我们没有设置过密码,说明有问题
不慌,下面我们设置一下就不需要密码,能够正常建立链接了
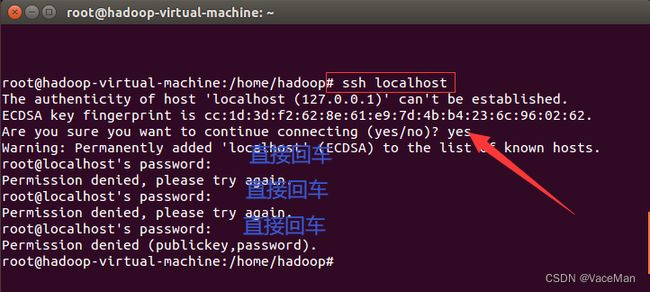
#ssh密钥
ssh-keygen -t rsa #直接回车就行
#密钥添加到服务器,这样ssh localhost就不用输入了
cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys
#设置权限
chmod 600 ~/.ssh/authorized_keys

(3)测试
#这回成功建立链接
ssh localhost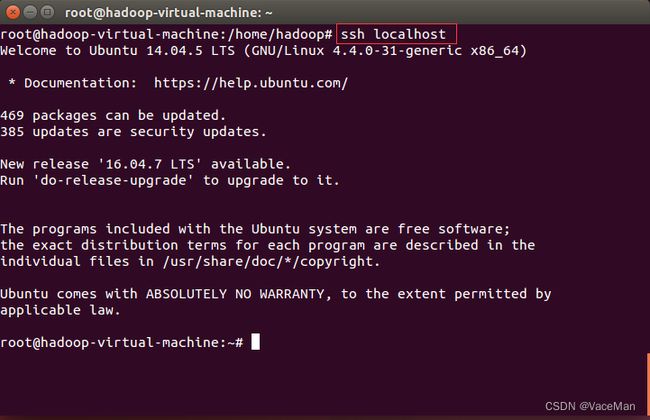
3.通过拖拽的方式将文件从windows传到linux桌面

1.拖拽文件就可以实现是因为安装了vmware tools
2.如果您的虚拟机没有安装vmware tools,您可以通过ifconfig命令查看虚拟机的ip地址,然后通过xftp软件(官网申请免费使用)实现文件传输
4.配置Java
(1)解压jdk7u79linuxx64.tar.gz文件到/usr/local下
#文件传到了hadoop(普通用户)的桌面上,所以使用hadoop账户
#普通账户(hadoop)
sudo tar -zxvf ~/Desktop/jdk7u79linuxx64.tar.gz -C /usr/local
sudo apt-get install openjdk-7-jdk
(2)修改文件,设置环境变量。
sudo vim /etc/profile文件末尾加入:
export JAVA_HOME=/usr/local/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH:
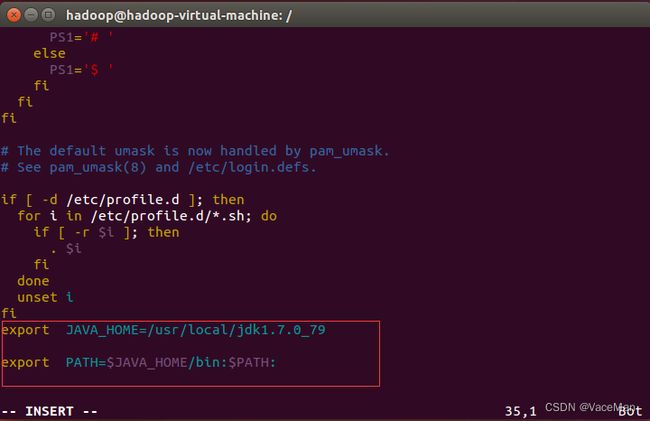
#不要忘记source激活
source /etc/profile(3)验证
#查看路径信息
echo $JAVA_HOME
#查看java版本号
java -version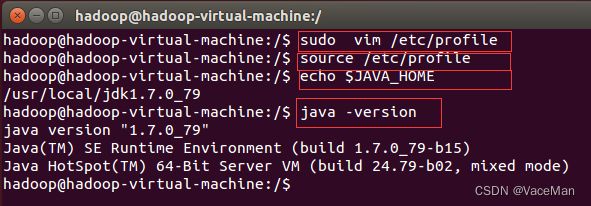
5.安装hadoop
(1)解压文件
sudo tar -zxvf ~/Desktop/hadoop-2.7.7.tar.gz -C /usr/local
cd /usr/local
sudo mv hadoop-2.7.7 hadoop
sudo chown -R hadoop:hadoop hadoop(2)检测是否安装成功
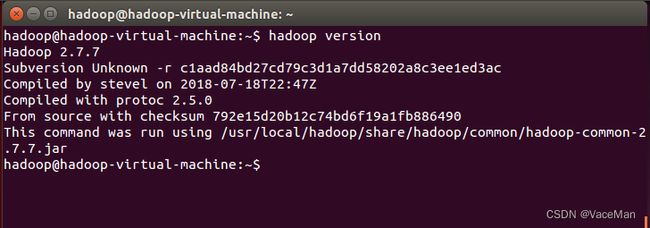
cd /usr/local/hadoop
./bin/hadoop version #成功则会显示 Hadoop 版本信息
6.修改hadoop环境变量
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
#加入下面内容,保存退出:
export JAVA_HOME=/usr/local/jdk1.7.0_79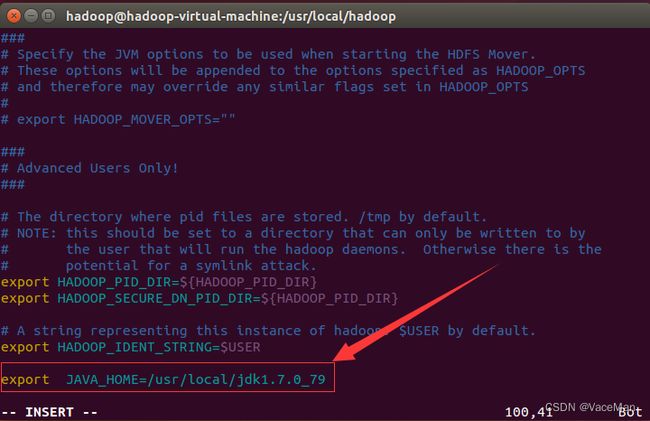
#在老师的实验报告指导书基础上,进行增加,把hadoop加到环境变量中
sudo vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#激活
source /etc/profile
#重启虚拟机
reboot
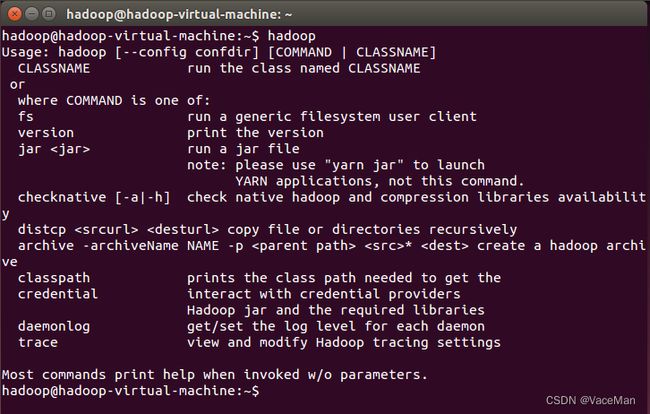
#终端测试,看是否添加成功
hadoop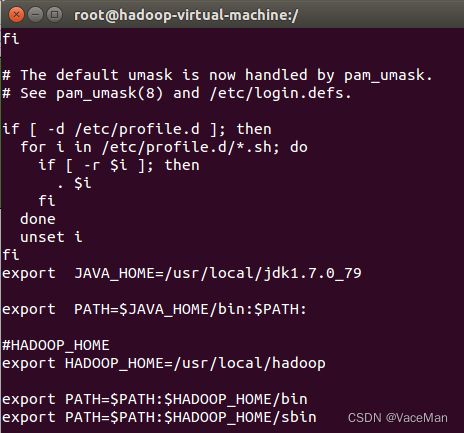
7.修改配置文件 core-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
#configuration里增加内容
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000

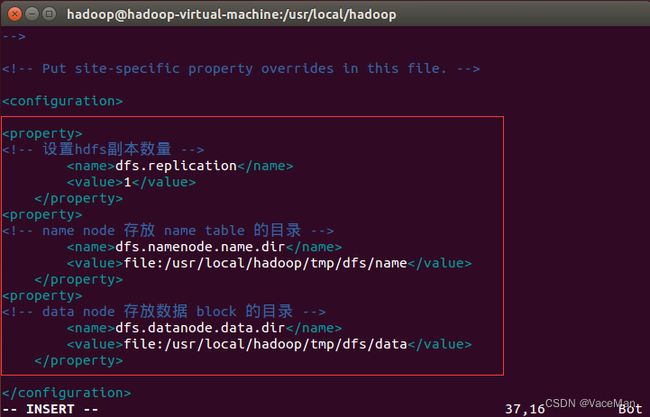
8.修改配置文件hdfs-site.xml文件
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
#configuration里增加内容
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
9.执行NameNode的格式化
/usr/local/hadoop/bin/hdfs namenode -format
#成功的话,会看到 "successfully formatted" 和 "Exitting with status 0" 的提示,若为 "Exitting with status 1" 则是出错。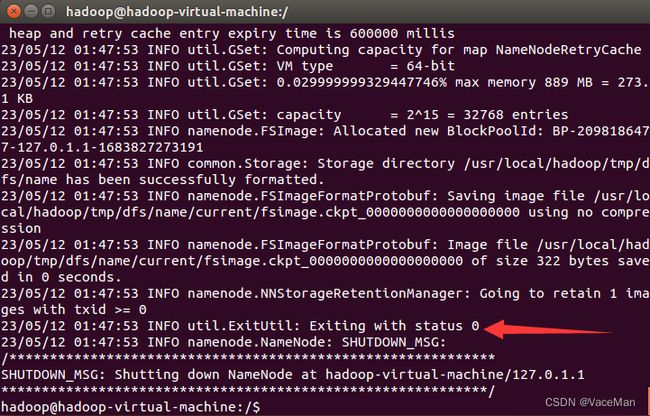
10.开启NameNode和DataNode守护进程
/usr/local/hadoop/sbin/start-all.sh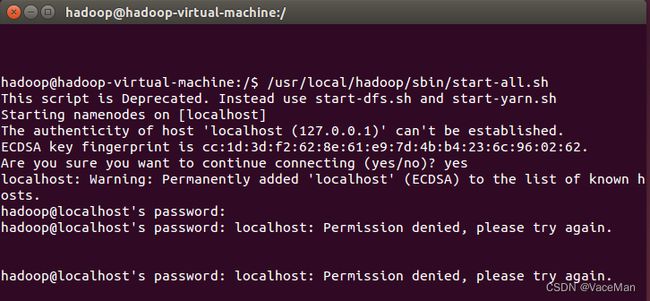
这里我们使用的是hadoop(普通账户),又出现了类似2(2)的情况,需要输入密码。
为什么呢?步骤2中我们明明配置好并测试过了,为什么还会出现这种情况呢?
原因:步骤2中使用的root账户,这里使用的是hadoop账户
两种解决办法:
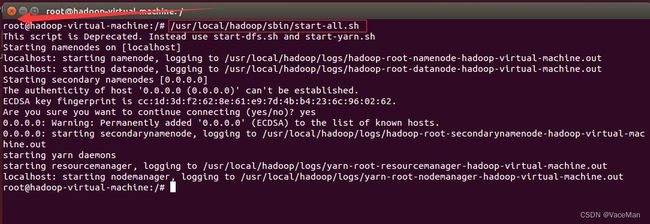
(1)切换root账户进行(下面采用此方法)
(2)hadoop账户先执行一遍2(2)步骤,再执行本步骤操作即可。(已亲自测试过)
经验:以后涉及到ubuntu软件、环境变量配置、进程等操作,一律使用root账户,会减少很多不必要的麻烦!
#jps
jps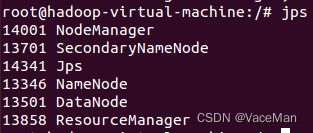
11.访问web页面
http://localhost:50070
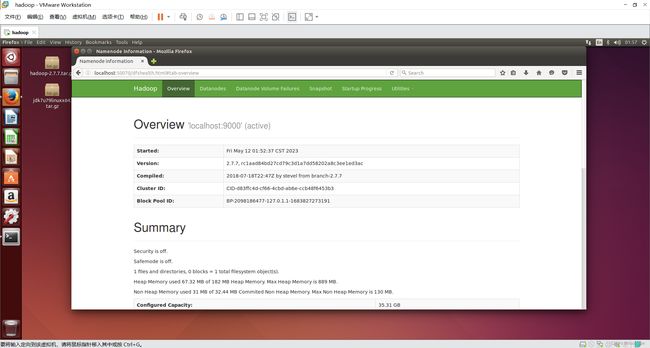
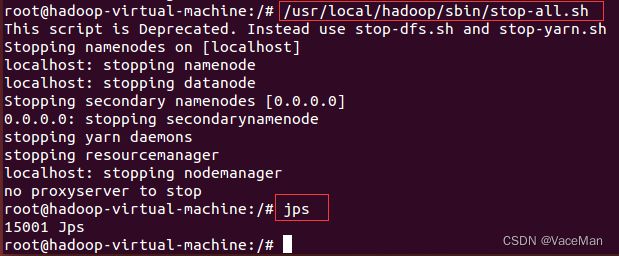
12.关闭Hadoop
/usr/local/hadoop/sbin/stop-all.sh