搭建基于LangChain + ChatGLM2-6B 的个人知识库
文章目录
- 一、简介
-
- 1、LangChain
- 2、ChatGLM2-6B
- 二、准备工作
- 三、项目部署
-
- 1、本地环境
- 2、Embeddin部署
- 3、LLM部署
- 4、LangChain部署
- 5、运行
- 四、项目测试
一、简介
这个例子使用现成的ChatGLM2-6B和LangChain搭建个人专属知识库,无需训练,通过上传pdf、 txt、 md、 docx等类型的文档可以扩充知识库的内容。
1、LangChain
LangChain 是一个利用大语言模型的能力开发各种下游应用的开源应用程序框架,它的核心理念是为各种LLM(大语言模型)应用实现通用的接口,与外部数据源进行连接,简化LLM应用的开发难度,同时允许用户与LLM进行交互。
2、ChatGLM2-6B
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署。ChatGLM2-6B使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化,增加了许多特性,如:基座模型升级,性能更强大、支持 8K-32k 的上下文、推理性能提升了 42%。在中文 C-Eval 榜单中,ChatGLM2 以 71.1 分位居榜首,碾压 GPT-4。
二、准备工作
在部署项目之前,我们先简单了解下,本地知识库框架的大概构成,有助于我们在部署的时候可以做相应的改动。目前市面上大部分的知识库都是采用Embedding + LLM + LangChain这套架构,大致如下:
从上图可以看出,将相关文件经过文本分割、文本向量化后存储至向量数据库,再将用户的提问进行向量化之后和数据库中的文本向量进行匹配,利用向量的相似度算法(如:余弦距离)得到最相似的K个文本向量,将这K个向量所对应的上下文和用户提问一起放到Prompt中提交给LLM进行答案的生成。
三、项目部署
上面提到本地知识库框架有Embedding、LLM、LangChain这三个部分组成,那接下来我们分别进行这三个部分的部署。
1、本地环境
- 系统:Ubuntu 22.04
- 显卡:V100
2、Embeddin部署
这里我们选择text2vec-large-chinese这个文本向量化工具,用git将代码同步至本地
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
如果没有安装lfs,可以从下面手动下载模型权重文件
https://huggingface.co/GanymedeNil/text2vec-large-chinese/tree/main
3、LLM部署
git同步ChatGLM2-6B至本地
git clone https://github.com/THUDM/ChatGLM2-6B
在首次运行ChatGLM2-6B时候会自动下载模型,因为模型较大,也可以自己手动从下面的地址下载
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b&mode=list

把下载的模型放到自定义目录后,只需要将web_demo.py文件中下面两行"THUDM/chatglm2-6b"替换成自定义的模型目录就行。
![]()
当然,这个只是针对单独运行ChatGLM2-6B而言,对于本地知识库,则需要修改LangChain中的配置文件,下面会讲到。
4、LangChain部署
LangChain和ChatGLM的调用需要做一些代码上的工作,所以我们选用网友修改好的一款,开箱即用。同样git代码到本地:
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
安装相关依赖
pip install -r requirements.txt
安装完毕后,修改configs/model_config.py,主要修改三个地方:
- Embeding模型路径,将“text2vec”的路径修改为本地路径,如:/data/text2vec-large-chinese。
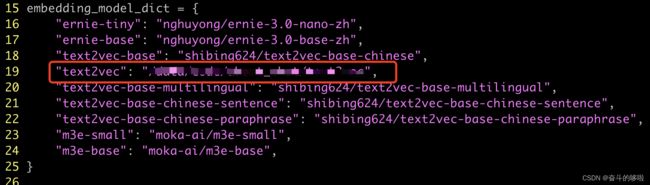
- 将ChatGLM2-6B的模型文件改成本地模型路径,因为在此采用的是默认的模型文件下载路径。

- 修改调用的LLM模型名称,改为chatglm2-6b

5、运行
上述配置修改完成之后,在langchain-ChatGLM目录下,直接执行
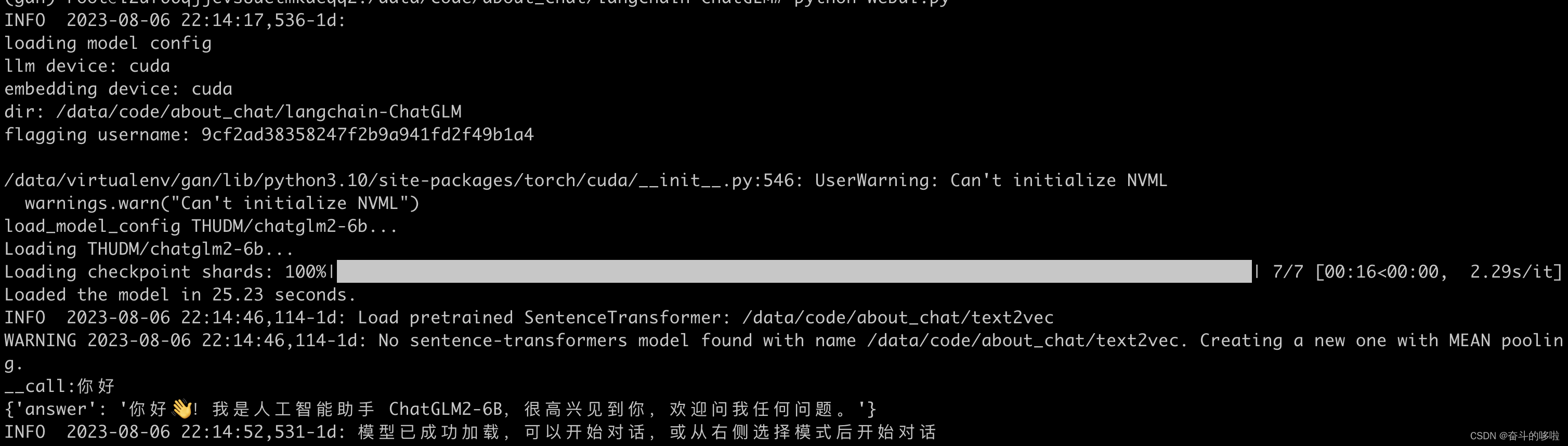
python webui.py
如果命令窗口出现如下信息,则代表运行成功。
输入本地访问地址http://127.0.0.1:7860,则出现下述界面

如果是部署在远程服务器上,则需要将webui.py中的share参数改为True
生成外部访问地址:

四、项目测试
选择页面右侧的“知识库问答”,目前还没任何知识库,所以我们先添加知识库。

建立的知识库,取名为“测试1”
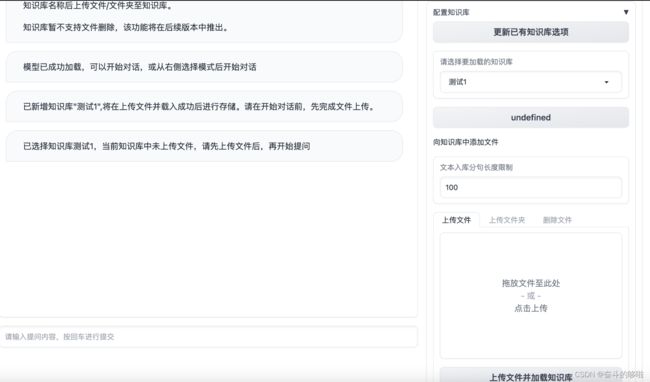
上传了一个test.txt文件
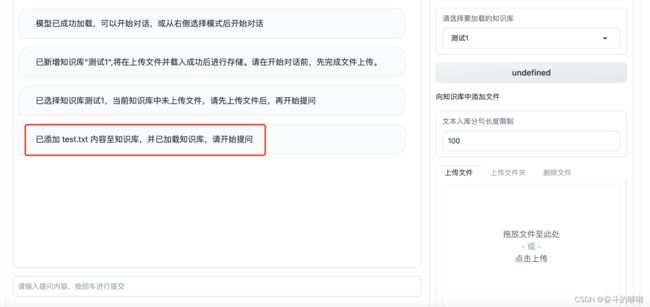
里面是一些新闻内容

知识库加载完毕后,进行提问,回答内容标注了来自于上传的文档的哪个地方。

知识库搭建完毕,大家可以自行多做测试,有问题欢迎留言。