Java线程池不简单也不深入使用介绍
文章目录
-
- 前言
- Executor框架
- Executors介绍
- 重写`WebServer3`
- `Executor`周期
- 线程池的使用
-
- 同步数据的生产者和消费者
- 爬虫遇到异常时,其他线程还在跑着
- 线程池定义的位置
- 总结
前言
考虑一个问题,如果我们现在需要开发一个Web服务器,接收来自客户端的请求,我们该怎么实现呢?
public class WebServer1{
public static void main(String[] args){
ServerSocket socket=new ServerSocket(80);//启动一个serverSocket,监听80端口
while(true){
Socket connection=socket.accept(); //等待外部客户端,此处阻塞。
handleRequest(connection);//处理接收到的数据。。。。。。
}
}
}
这段代码从理论上来说,是满足我们需求的,但是需要考虑另外一个问题,两个或者两个以上的客户端请求过来时,需要排队等待上一个请求执行完毕。
既然串行处理搞不定,那么,多整几个线程呢:
public class WebServer2{
public static void main(String [] args){
ServerSocket socket=new ServerSocket(80);
while(true){
final Socket connection=socket.accept();
new Thread(()->handleRequest(connection)).start();//开启一个新的线程去处理
}
}
}
这段代码,从理论上来讲,也能满足我们的需求,而且比上一个更高级,来一个客户端请求,服务端就开一个线程单独去处理,主线程依然可以等待下一个客户端请求。但这种无限制创建线程,会影响整个程序的稳定性,甚至宕机。
下面我们讨论一下无限制创建线程的不足:
- 线程生命周期的开销非常高。默认情况下(基于Sun JDK),一条Java线程是映射到操作系统的一个轻量级进程之中。导致了线程的创建和销毁代价很大。
- 资源消耗。活跃的线程会消耗系统资源,主要体现在内存和CPU上。如果可运行的线程数量多于可用CPU处理器的数量,那么将会有线程闲置,这些闲置的线程会占用许多内存。而且大量线程在竞争CPU资源时还将产生其他的性能开销,比如CPU切换线程的代价。
- 稳定性。因为操作系统对每个进程可以创建的线程数量有限制。这个限制随着平台的不同而不同,并且受多个因素的制约,如JVM启动参数,Thread构造函数中栈大小等。如果破坏了这些限制,很可能一个OutOfMemoryError出现。
总结起来一句话,因为系统资源的是有限的,所以不能创造无限数量的线程。
既然问题提出来了,那么就是提出解决问题的办法,幸运的是JDK为我们提供了一个叫做线程池的东西。接下来我们一起来研究什么是线程池,如何使用线程池。
Executor框架
在研究线程池之前,首先了解一下Executor框架。只有一个execute方法的Executor接口是所有线程池的老子,Executor基于生产者-消费者模式,提交任务的操作相当于生产者,执行任务的线程则相当于消费者。
上面这句话有点不是特别好理解,来看这段代码:
//这段代码不能运行,只是借助于理解Executor框架的生产者-消费者模型
public class WebServer3{
private static final Executor exec=new WebServer3ThreadPool();//WebServer3ThreadPool在jdk中不存在,自己随便定义的
public static void main(String [] args){
ServerSocket socket=new ServerSocket(80);
while(true){
Socket connection=socket.accept();
Runnable task=new Runnable(){
public void run(){
handleRequest(conection);
}
};
exec.execute(task);//将任务提交到线程池,生产者。
}
}
}
在上面代码中,我们看到了生产者,那么消费者呢?而且,线程池的池子在哪呢?现在我们需要正式引入消费者,以及池子的真面目。
Executors介绍
关于介绍Executors,有必要将Executor的继承结构翻出来。

最终的线程池具体实现,以下三个(不考虑Executors中的实现类):
ThreadPoolExecutor:使用one of possibly several pooled threads 执行每个已经提交的任务(英文这段真不好翻译)ForkJoinPool:用于运行ForkJoinTask的线程池ScheduledThreadPoolExecutor:用于定时任务,或者线程调度的线程池,是ThreadPoolExecutor的子类
现在我们知道,根据不同的业务场景可以使用上述三种不同的线程池,但是有一个问题,当你new一个ThreadPoolExecutor时,其参数巨多,基础薄弱的同学可能还搞不明白每个参数的函数。比如:

还有

ForkJoinPool和ScheduledThreadPoolExecutor参数个数就比较合理,虽然合理,但ThreadPoolExecutor是基础,是最常用的,面对那么多参数,该怎么办呢?
JDK文档上都说了,建议使用Executors的工厂方法来创建。那么Executors都提供了哪些工厂方法呢?
newFixedThreadPool:创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量。newCachedThreadPool():创建一个可缓存的线程池,如果线程池的当前数量超过了处理需求时,那么将回收空闲的线程,当处理需求增加时,可以添加新的线程,线程池的大小不受任何限制。newSingleThreadExecutor():创建一个单线程的线程池,它创建单个消费者线程来执行任务,如果单个消费者线程异常结束,会创建另外一个线程来替代。newScheduledThreadPool(int corePoolSize):创建一个固定长度,而且一延迟或定时的方法来执行任务 。
还有一些其他的除参数不一致的方法,如newWorkStealingPool等,这里就不一一介绍。
上面介绍了几个创建线程池的方法,其重载函数带有ThreadFactory参数,那么ThreadFactory是做什么的呢?其实这个只有一个newThread方法的可怜接口,主要目的是为了创建线程对象,使用线程工厂可以避免对的new Thread(Runnable)调用的硬连接,使应用程序能够使用特殊的线程子类,优先级等。
其默认实现DefaultThreadFactory中:
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
在ThreadPoolExecutor中使用:
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
说白了,就是一个把Runnable转化成Thread的地方。
至此为止,Executors的介绍暂时告一段落,只需要明白Executors是一个创建线程池的工厂就足够了。
重写WebServer3
我们知道创建线程池的几个方法,那么现在将上面的WebServer3重写一遍:
public class WebServer3{
private static final Executor exec=Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());//创建一个固定大小为CPU处理核数的线程池
public static void main(String [] args){
ServerSocket socket=new ServerSocket(80);
while(true){
Socket connection=socket.accept();
Runnable task=new Runnable(){
public void run(){
handleRequest(conection);
}
};
exec.execute(task);//将任务提交到线程池
}
}
}
到现在为止,可能还有同学有疑问,消费者呢?池子长得啥样?这里简单的说一下,消费者被封装在通过Executors.newFixedThreadPool构造的对象中,池子也存在在里面,至于是什么形式,简单来说,是一个阻塞队列。更深层次的剖析,请参看笔者其他文章。
Executor周期
现在我们已经知道了通过Executors工厂方法来创建一个线程池,但是并没有说如何关闭它。JVM只有在所有线程全部终止后才会退出,因此,如果无法正确的关闭Executor,那么JVM将无法结束。
问题来了,当所有任务都结束后,线程池难道不是自己关闭吗?既然不是自己关闭,那我们手动关闭需要怎么做呢?
看这一段代码:
public class ExecutorDemo {
public static void main(String[] args) {
int nThreads = Runtime.getRuntime().availableProcessors();
ExecutorService executorService= Executors.newFixedThreadPool(nThreads);
for(int i=0;i System.out.println(Thread.currentThread().getName()));
}
System.out.println("执行完毕了??????");
}
}
这是执行结果:
pool-1-thread-3
pool-1-thread-5
pool-1-thread-4
执行完毕了??????
pool-1-thread-2
pool-1-thread-1
pool-1-thread-8
pool-1-thread-7
pool-1-thread-6
如预期一样,打印出了我们想打印的一切东西,但是唯独JVM没有退出。那颗红红的小方块还在无声的炫耀着自己还活着。为什么程序没有退出呢?
因为线程池在等待,等待新的任务添加进来,等待未完成的任务执行完毕,这里简单介绍其原因。我们使用线程池的原因是什么?一句话描述,避免资源的浪费。因为不能无限制的创造线程,所以有了线程池,能将原来创建的线程存储起来,并等待任务的到来,当有任务过来时,然后一群线程扑过来,把任务瓜分掉,然后继续等待。
我们可以从dump文件中发现,线程池确实在等待
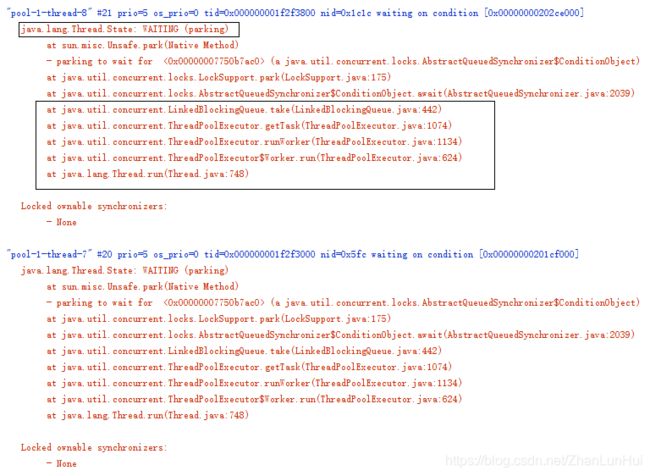
为了解决线程池的生命周期的问题,ExecutorService扩展了Executor,添加了一些控制线程池生命周期的方法:
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
...
}
当调用shutdown方法后,相当于给线程池对象指示:不再接受新任务,但是未完成的任务,存储在队列里面的任务需要执行完毕。
而调用shutdownNow方法之后,相当于给线程池对象说:马上停止干活,正在运行的任务,尝试取消,存储在队列里的任务,全部放弃掉。
isTerminated代表如果当所有任务都已经完成,并且线程池已经关闭(调用shutdown或shutdownNow之后),则返回true,通常此方法在关闭之后调用。
public class ExecutorDemo {
public static void main(String[] args) {
int nThreads = Runtime.getRuntime().availableProcessors();
ExecutorService executorService= Executors.newFixedThreadPool(nThreads);
for(int i=0;i<Runtime.getRuntime().availableProcessors();i++){
executorService.execute(()-> System.out.println(Thread.currentThread().getName()));
}
executorService.shutdown();
while(!executorService.isTerminated()){
System.out.println("任务还没有执行完毕");
}
System.out.println("执行完毕了??????");
}
}
此处只是简单的介绍了Executor的周期,及其控制方法。本篇文章不会深入的剖析线程池及其原理,上文所述只是对ThreadPoolExecutor线程池的使用介绍,其他如ForkJoinPool等不会出现在本文中,但是其大体规则都是相同的。
线程池的使用
以下章节是笔者在工作过程中对于线程池使用的案例。
同步数据的生产者和消费者
描述:某公司A为我们提供了数据接口,我们需要把A公司的数据全部下载到我们自己的数据库中。
以下代码是A公司提供的数据模型:
public class ThreadExampleModel {
static Random random = new Random();
private String name;
private String address;
private Integer age;
private Integer pageIndex;
public ThreadExampleModel(int pageIndex) {
name = UUID.randomUUID().toString();
address = UUID.randomUUID().toString();
age = random.nextInt(100000) + 10;
this.pageIndex = pageIndex;
}
// get set 省略
}
以下是使用两个线程池下载数据模型的例子:
public class ProducerCustomerDemo {
static final int nThreads = Runtime.getRuntime().availableProcessors();
public static void main(String[] args) {
new ProducerCustomerDemo().downloadData();
}
void downloadData() {
//创建消费者线程池
ExecutorService customerService = Executors.newFixedThreadPool(nThreads);
//创建生产者线程池
ExecutorService producerService = Executors.newFixedThreadPool(nThreads);
//消费者和生产者线程池共享的集合
BlockingQueue<ThreadExampleModel> collections = new ArrayBlockingQueue<>(2000);
//向消费者线程池中添加任务
IntStream.rangeClosed(0, nThreads).forEach(e -> customerService.execute(new CustomerService(collections)));
//向生产者线程池中添加任务
IntStream.rangeClosed(0, nThreads << 15).forEach(e -> producerService.execute(new ProducerService(e, 20, collections)));//产生nThreads*2^15个任务
//关闭线程池,不再添加新的任务
producerService.shutdown();
customerService.shutdown();
//等待任务完成
while (true) {
if (producerService.isTerminated() && customerService.isTerminated()) {
System.err.println("完事");
System.err.println("完事");
break;
}
}
}
//生产者
private class ProducerService implements Runnable {
private BlockingQueue<ThreadExampleModel> collections;
//页索引
private int pageIndex;
//页大小,从外部传过来的页大小统一为20
private int pageSize;
public ProducerService(int pageIndex, int pageSize, BlockingQueue<ThreadExampleModel> collections) {
this.collections = collections;
this.pageIndex = pageIndex;
this.pageSize = pageSize;
}
@Override
public void run() {
//相当于从A公司提供的接口中下载数据,然后put到阻塞队列中
IntStream.rangeClosed(1, pageSize).forEach(e -> {
try {
collections.put(new ThreadExampleModel(pageIndex));
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
}
}
//消费者
private class CustomerService implements Runnable {
private BlockingQueue<ThreadExampleModel> collections;
public CustomerService(BlockingQueue<ThreadExampleModel> collections) {
this.collections = collections;
}
volatile boolean run = true;
@Override
public void run() {
try {
while (run) { //批量获取,适用于消费者速率小于生产者速率的场景
Thread.sleep(2000);
List<ThreadExampleModel> models = new ArrayList<>();
//一次性把阻塞队列中的所有元素全部取取出,如果集合中没有元素了,则认为生产者已经完成生产,消费者需要停止
if (collections.drainTo(models) <= 0)
run = false;
else {
System.err.println("从队列中获取" + models.size() + "条数据");
executeSave(models);
}
}
} catch (InterruptedException e) {
}
}
}
void executeSave(List<ThreadExampleModel> models) {
models.forEach(e ->System.out.println("执行保存。。。。"+e));
}
}
两个线程池之间共享一个阻塞队列,消费者停止消费的判断条件就是每隔两秒获取的阻塞队列中是否为空。
这里笔者需要说明的是:使用一个线程池自产自销和使用两个线程池实现生产-消费模型,各有利弊。两个线程池在函数里定义,实现生产-消费模型,在某些情况下,可能会出现致命的问题。消费线程池里的线程全部挂掉,整个阻塞队列陷入永久等待,但是有一个很简单的解决办法,在消费者线程中抓RuntimeException,但是这并不是唯一的解决办法,其中所涉及到线程池更高级的知识,会在其他文章中讲述。
再重申一遍,若使用生产-消费模型,务必抓RuntimeException。
爬虫遇到异常时,其他线程还在跑着
曾经笔者爬取过某公司网站的数据,具体方式是爬取接口。什么意思呢?前端调用后端提供的接口,传入指定参数,获取json数据,然后解析并渲染到页面上。而接口的参数为一个指定的集合里的元素,比如日期和城市名称。
现在需要全国500个城市30日内的数据,需要构造500*30条请求,这些请求存放到一个阻塞队列中,同样开一个线程池,设有n个线程开始执行。在运行期间,因为网站的接口更改了,在一个线程发现后,需要发出信息,停止线程池。
public class ThreadPoolCommunication {
static final int nThreads = Runtime.getRuntime().availableProcessors();
final ExecutorService executorService = Executors.newFixedThreadPool(nThreads);
public static void main(String[] args) {
new ThreadPoolCommunication().spiderInternetData();
}
void spiderInternetData() {
BlockingQueue<String> collections = dataGen();
IntStream.range(0, nThreads).forEach(e -> executorService.execute(() -> {
while (collections.size() > 0) {
if (collections.size() == 400) { //当队列中的元素数量等于400时,模拟出现异常,停掉线程池
System.err.println("抛出异常。。。。。");
executorService.shutdownNow();
} else {
try {
System.out.println(Thread.currentThread().getName() + "" + collections.take());
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
}));
}
//模拟产生url数据 500*30条数据
protected BlockingQueue<String> dataGen() {
List<String> urls = IntStream.range(0, 30).boxed().map(e -> {
String format = LocalDate.now().plusDays(e).format(DateTimeFormatter.ofPattern("yyyy-MM-dd"));
return IntStream.rangeClosed(1, 500)
.mapToObj(url -> "http://xxx.xxx.xx:9100/getData?city=" + UUID.randomUUID().toString() + "&date=" + format)
.collect(Collectors.toList());
}).flatMap(e -> e.stream()).collect(Collectors.toList());
BlockingQueue<String> collections = new ArrayBlockingQueue<>(urls.size());
urls.forEach(url -> {
try {
collections.put(url);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
return collections;
}
}
上面代码,绝对不会达到预期效果。executorService.shutdownNow()只是尝试停止所有正在执行的任务,停止等待任务的处理,而当前线程活跃因为collections.size()的值还是400,与while循环相比较,400>0是成立的,当前线程退不出去,会造成死循环。再者,shutdownNow的方法上也说了:这个方法不等待活跃地正在执行的方法终止。当前这个线程还在死循环着,肯定退不出去。现在,我们修改一下代码。
void spiderInternetData() {
BlockingQueue collections = dataGen();
IntStream.range(0, nThreads).forEach(e -> executorService.execute(() -> {
while (collections.size() > 0) {
if (collections.size() == 400) { //当队列中的元素数量等于400时,模拟出现异常,停掉线程池
System.err.println("抛出异常。。。。。");
executorService.shutdownNow();
return;
} else {
try {
System.out.println(Thread.currentThread().getName() + "" + collections.take());
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
}));
}
对于重新修改的代码,的确在集合中只剩400条的时候,打印出了 抛出异常。。。,但是却打印出和线程数量一致的语句。再看另一个问题,每次运行的结果抛出异常。。。这句话的出现的位置还不一样,比如:

还有:
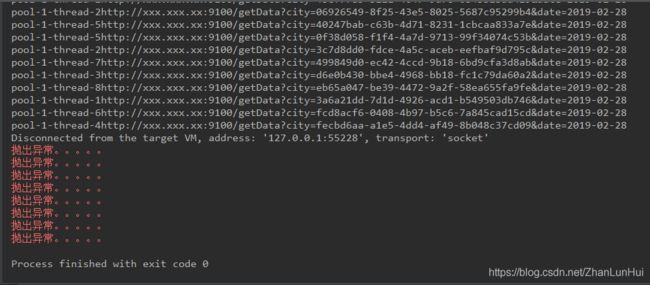
这种现象我们可以解释,当发出调用shutdownNow时,当前还有其他正在运行的线程,因为shutdownNow只是尝试去关闭正在运行的线程,并不是强制暴力地把当前正在运行的线程关闭,所以出现这种情况。
那么打印出和线程数相同的抛出异常。。。是什么原因呢?

if (collections.size() == 400 ) { //当队列中的元素数量等于400时,模拟出现异常,停掉线程池
System.err.println(Thread.currentThread().getName()+"抛出异常。。。。。");
executorService.shutdownNow();
return;
}
这段代码没问题,有问题的是这段代码collections.size(),它的值被n多个线程共享了。这里我们可以说collections.size() == 400是线程不安全的,从字节码的角度来说,collections.size() == 400被分成三个步骤:将collections.size()的值推向栈顶,将400推向栈顶,进行比较,在这个过程中,collections.size()的值可以被其他线程共享。有没有办法避免呢?能不能将collections.size() == 400变成原子操作呢?在不考虑使用同步机制的情况下,没有办法避免。
再回到我们原来的问题,原来的问题是在某一个线程发现接口变了以后,发出提示,而以上的代码虽然发出了提示,但是却重复提示,能不能只发出一次提示呢?考虑一下原子操作类型。比如,我们可以将代码更改一下:
void spiderInternetData() {
final AtomicBoolean atomFlag = new AtomicBoolean(true);
BlockingQueue collections = dataGen();
IntStream.range(0, nThreads).forEach(e -> executorService.execute(() -> {
while (collections.size() > 0) {
if (collections.size() == 400) { //当队列中的元素数量等于400时,模拟出现异常,停掉线程池
if (atomFlag.compareAndSet(true, false)) {
System.err.println(Thread.currentThread().getName() + "抛出异常。。。。。");
//将剩余的url持久化。。。。
executorService.shutdownNow();
}
return;
} else {
try {
System.out.println(Thread.currentThread().getName() + "" + collections.take() + "--->" + collections.size());
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
}
));
}
在collections.size() == 400之后,再加一层atomFlag.compareAndSet(true, false)判断,确保程序提示只发一次提示。
现在我们解决了上述问题,还有一个类似的很有趣的问题,向文件打印20亿个数据,每行20个。也会遇到类似的问题,多打印n行。可以尝试用上述方法解决一下。
线程池定义的位置
上面两个例子,细心的读者可能注意到,线程池定义在不同位置,示例1将线程池定义在函数内部,示例2将线程池定义在类里面。这有什么区别呢?
现在的开发环境大多是web,以此为定义,我们说一下不足:
示例1:当一个请求过来后,调用函数,创建线程池,此时该线程池中存有大量任务,耗费了大量内存。接着又过来一个请求,又创建了线程池。随着请求的增加,线程池的数量增加,且之间无任何关联。而此时整个程序中的线程数量,随着线程池的增加而呈线性增长,大量内存在一瞬间被占用,增加了GC的频率,降低系统性能,更甚者,因为内存被占用,可能会导致宕机。如果线程池忘记关闭,直接就是灾难。
示例2:整个线程池在程序运行期间不会关闭,除非出现某些需求的更改。其背后的支撑就是任务队列,如果线程池内的队列选择为无界队列,如LinkedBlockingQueue,请求过来后大量任务被堆积在任务队列中,若任务比较耗时,CPU和内存直接呈指数飙升。若选择有界队列,常用的有界队列有了两类:一类是支持FIFO的队列,一类是支持优先级的队列。当队列饱和了以后,java默认提供了4种饱和策略的实现方式:中止、抛弃、抛弃最旧的、调用者运行。这无疑增加了编程的复杂度。若是不慎在这种情况下将线程池关闭,意味着除非重启程序,否则该线程池将在整个程序运行期间不能用。
总结
线程池的基本使用介绍就到这里,最后说明一下,线程池定义的位置,应该由其业务决定,毕竟业务推动技术。中间的两个示例,还隐藏着很多未知的bug,之所以放在这里讲,只是为了能让更多的人了解因线程池引发的问题,并且将其解决。