SQL 语句继续学习之记录二
三, 聚合与排序
对表进行聚合查询,即使用聚合函数对表中的列进行合计值或者平均值等合计操作。
通常,聚合函数会对null以外的对象进行合计。但是只有count 函数例外,使用count(*) 可以查出包含null在内的全部数据行数。
使用distinct 关键字删除重复值。
1,聚合函数之常见的5个聚合函数
count:计算表中的记录数(行数)
SUM:计算表中数值列的数据合计值
AVG:计算表中数值列的数据平均值
MAX:求出表中任一列中数据的最大值
MIN:求出表中任意列中数据的最小值
如上,用于合计的函数称为聚合函数或者集合函数。所谓聚合,就是将多行汇总为一行。实际上,所有的聚合函数都是这样,输入多行输出一行
1)
a, 如下,我们要获取如下原始数据表中全部数据的行数。
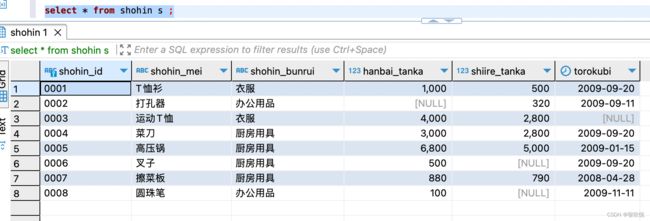
如上,一共有8行数据,所以我们获取到的结果应该是8.
如下 count(*) 中的 * 表示全部列
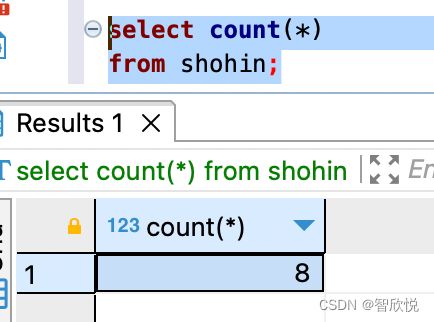
b, 计算null以外数据的行数
如上,查询的是全部数据(所有列的)行数,但是如果想要查询某个列(比如该列可能存在null 数据) 的行数,该怎么做呢?
比如想得到shiire_tanka 列(进货单价)中非空行数的列,,可以通过将对象列设定为参数来实现
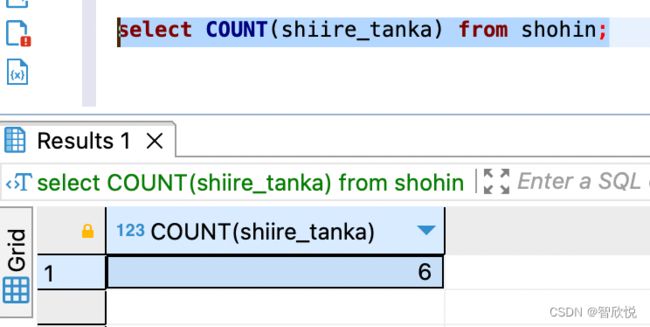
Note:
Count 函数的结果根据参数不同而不同。count(*)会得到该表格包含null数据的所有行数,而count(某个列名)得到的是该列中,除了null之外的数据的行数。
Count 函数也是唯一一个可以以星号 * 为参数的函数,
2) 计算合计值
例如,我们需要计算销售单价的合计值,即销售单价列,所有数值加起来的总和。
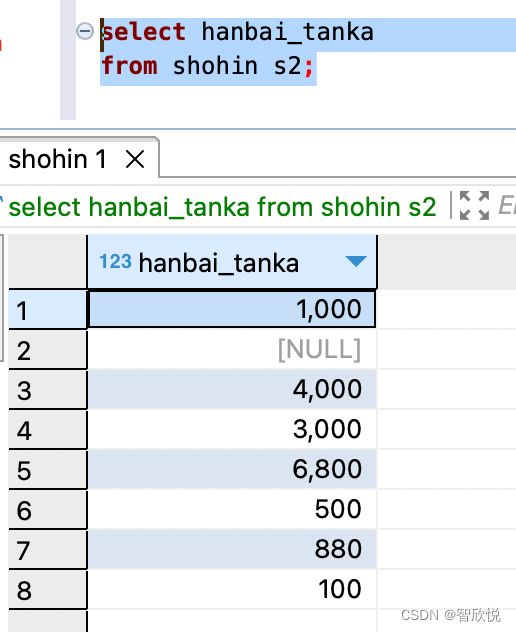
1000 + 4000 + 3000 + 6800 + 500 + 880 + 100 = 16280

Note: 之前我们提到,含有null 的算术运算符中,如果数据含有null,则最终运算结果为null,但如上,最终结果并不为null,而是我们日常生活中所理解的正常的数值。其原因为,聚合函数,除了count 函数外,其他几个聚合函数在最终计算时都会将null 数据提前排除在外。因此不会看到null的结果,这也证明我们之前的描述的正确性。 所谓count函数例外,是说count在参数为星号 * 时,会将null结果计算在内。
3)计算平均值
如我们要获取销售单价的平均值

注意,如上,hanbai_tanka 结果值是16280,如果按照8行为除数,结果应该是2035,但现在的结果是2325.7143, 是因为该数据的计算是 16280 除以 7 得到的结果,也就是说,计算平均值时,avg 函数会将null 数据所在的行排除掉,计算非null数据的总值,同时将非null数据的行数作为除数。
针对上述提到的点,需要特别注意,如果我们需要将null 作为0 进行计算,具体的实现方式需要参考后面的学习。暂时性放弃讲解,可此处留个记录,后续会详细讲述。
4)计算最大值和最小值
想要计算出多条记录中的最大值或最小值,可以分别使用MAX 和 MIN 函数
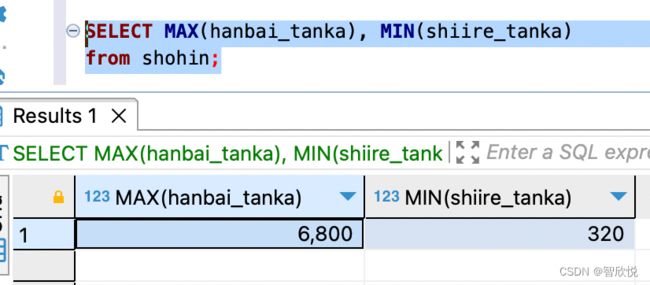
例如计算销售单价的最大值和进货单价的最小值。
如下,我们获取到了销售单价的最大值和进货单价的最小值
注意:MAX 和 MIN 函数和 SUM/AVG函数有一点区别,即SUM/AVG 函数只能对数值类型的列使用,而 MAX 和 MIN 函数原则上可以适用于任何数据类型的列。例如,我们可以对日期列进行大小值的获取
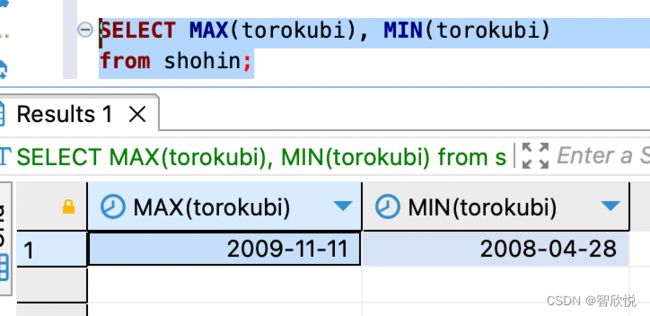
note: MAX 和 MIN 函数适用于任何数据类型的列,即只要能进行排序的数据,就肯定有最大值和最小值,也就能使用这两个函数,但是需要注意的是,’排序‘,需要注意是否是字符串等特殊类型,因为字符串排序是要按照数据字典来排序,比如之前 “1”,“22”,“3”,“225”等 字符串排序时,3要比22 大。 另外对与日期和字符串类型数据来说,能够使用MAX/MIN 这两个函数,但不能使用SUM/AVG函数,因为对日期和字符串来说,合计值和平均值均没有实际意义。
即MAX/MIN 函数几乎适用于所有数据类型的列,但SUM/AVG函数只适用于数值类型的列。
5)使用聚合函数删除重复值(关键字distinct)
在之前shohin表中看到,商品种类和日期的数据中,存在多行数据相同的情况

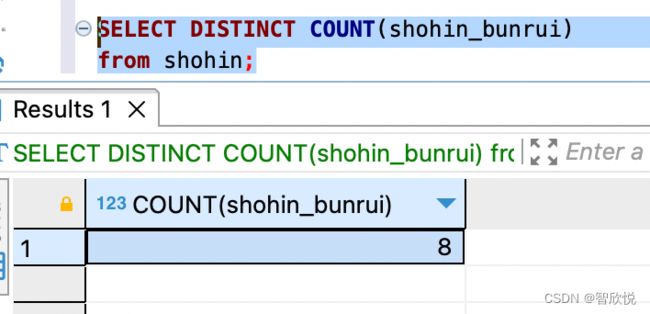
如果我们想要计算出商品种类的个数,怎么做呢? 即删除重复数据,然后再计算数据行数。

note: distinct 必须写在括号中,是因为必须要在计算行数之前删除shohin_bunrui 列中的重复数据。如果不加括号,distinct 需要放在第一列的钱买呢,则如下就会先计算出数据行数,然后再删除重复数据,结果会得到shohin_bunrui列的所有行数,即8
假设我们再增加一个查询列,比如日期这种有重复行的列,结果会如何呢?
如下
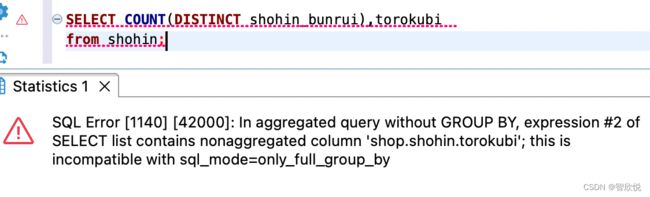

org.jkiss.dbeaver.model.sql.DBSQLException: SQL Error [1140] [42000]: In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'shop.shohin.torokubi'; this is incompatible with sql_mode=only_full_group_by
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.executeStatement(JDBCStatementImpl.java:133)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeStatement(SQLQueryJob.java:582)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.lambda$1(SQLQueryJob.java:491)
at org.jkiss.dbeaver.model.exec.DBExecUtils.tryExecuteRecover(DBExecUtils.java:190)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.executeSingleQuery(SQLQueryJob.java:498)
at org.jkiss.dbeaver.ui.editors.sql.execute.SQLQueryJob.extractData(SQLQueryJob.java:934)
at org.jkiss.dbeaver.ui.editors.sql.SQLEditor$QueryResultsContainer.readData(SQLEditor.java:3928)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetJobDataRead.lambda$0(ResultSetJobDataRead.java:123)
at org.jkiss.dbeaver.model.exec.DBExecUtils.tryExecuteRecover(DBExecUtils.java:190)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetJobDataRead.run(ResultSetJobDataRead.java:121)
at org.jkiss.dbeaver.ui.controls.resultset.ResultSetViewer$ResultSetDataPumpJob.run(ResultSetViewer.java:5140)
at org.jkiss.dbeaver.model.runtime.AbstractJob.run(AbstractJob.java:105)
at org.eclipse.core.internal.jobs.Worker.run(Worker.java:63)
Caused by: java.sql.SQLSyntaxErrorException: In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'shop.shohin.torokubi'; this is incompatible with sql_mode=only_full_group_by
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.StatementImpl.executeInternal(StatementImpl.java:763)
at com.mysql.cj.jdbc.StatementImpl.execute(StatementImpl.java:648)
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.execute(JDBCStatementImpl.java:330)
at org.jkiss.dbeaver.model.impl.jdbc.exec.JDBCStatementImpl.executeStatement(JDBCStatementImpl.java:131)
... 12 more提示sql 都有错误。
为何呢? 后面再做分析,暂时放在这儿
为了测试distinct 参数,我稍微修改了一下db 中打孔器的价格,从null 改为了500

如上,distinct 可以做count 函数的参数,其实,distinct也可以做其他所有聚合函数的参数,比如如下sql,我们可以尝试获取销售单价在有distinct参数和无distinct参数时的值差别 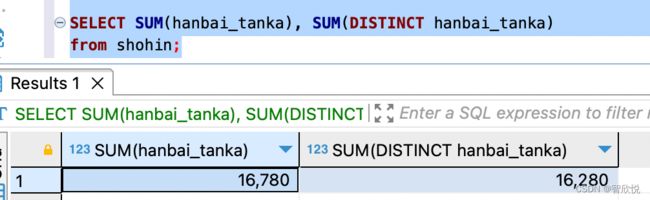
如上,都是计算销售单价的合计值,但这两个最终的结果却不同,为何呢?
因为在销售单价这一列中,有2个相同值 500 元。上述查询中,
SUM(hanbai_tanka) 是直接查询该列所有的数值加在一起的和,而SUM(distinct hanbai_tanka) 的查询逻辑是,先将该列中重复的数据去除,然后计算数值的总和。因此,上面的查询为
SUM(hanbai_tanka) = 1000 + 500 +4000 +3000 + 6800 + 500 + 880 + 100 =16780
SUM(distinct hanbai_tanka) = 1000 + 500 + 4000 + 3000 + 6800 + 880 +100 =16280
2, 对表进行分组
使用group by 子句可以像切蛋糕那样将表进行分割。通过使用聚合函数 和group by 子句,可以根据“商品种类” 和 “登记日期” 等将表分割后再进行聚合
聚合键中包含null时,在结果中会以“不确定” 行(空行)的形式表现出来
使用聚合函数和group by 子句时需要注意以下4点,
a 只能写在select 子句中
b, group by 子句中不能使用select子句中列的别名
c, group by 子句的聚合效果是无序的
d, where 子句中不能使用聚合函数
1)group by 子句
之前学习记录中,我们看到的聚合函数的使用方法中,无论是否包含null,无论是否删除了重复数据,都是针对表中的所有数据进行的聚合处理。而接下来的这里,我们先把表分成几组,然后再进行聚合处理。也就是按照“商品种类” 、“登记日期”等进行聚合。
1> 使用group by 子句进行聚合的sql 格式
select <列名1>, <列名2 >, <列名3>
from < 表名>
group by < >, < >, <>
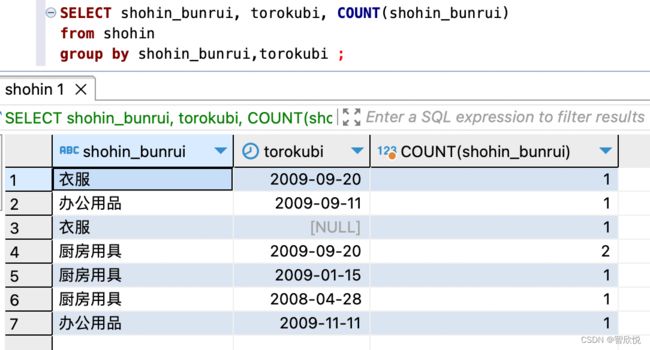
例如,我们按照商品种类来统计一下数据行数(=商品数量)
如上,商品种类一共有3种,衣服,办公用品,厨房用具

在此,我们需要分析一个问题,即group by 有和没有的区别。 如果没有group by 子句,聚合函数count(*) 相当于把整个表作为一个group,将该组中的数据行数进行计算。但是如果使用了group by, 系统会先把整个表按照聚合键(group by 子句中指定的列称为聚合键或者分组列)来切分成多个组,之后count 对每个组中的数据行数进行计算。
实际上,group by子句也和select子句一样,可以通过逗号分隔指定多列
如下,我们做测试如图
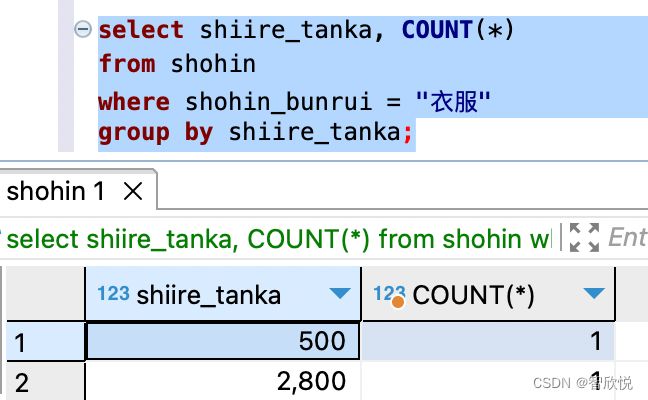
2> 使用where 子句时 Group by 的执行结果
在使用了group by 子句的select语句中,也可以正常使用where 子句。子句的排列顺序如图
使用where 子句和group by 子句进行聚合处理
select <列名1>, <列名2>,<列名3>
from <表名>
where
group by <列名1>,<列名2>,<列名3>
但请注意: group by 和 where 子句并用时,select语句的执行顺序如下所示
From ——> where ——> group by——>select
像这样使用where子句进行聚合处理时,会先根据where子句制定的条件进行过滤,然后再进行聚合处理。 如下
3> 与聚合函数和group by子句有关的常见错误
a, 常见错误问题1——在select子句中书写了多余的列
在使用count 这样的聚合函数时,select子句中的元素有严格的限制。实际上,使用聚合函数时,select子句中只能存在以下三种情况
(1)常数
(2)聚合函数
(3)group by 子句中指定的列名(也就是聚合键)
如上面记录的一个错误,此处由于select语句中使用了count这样的聚合函数,所以在select语句中不能出现类似torokubi 这样的shohin 表中其他的数据列,这样sql 将无法执行。
