Stable Diffusion XL(SDXL)原理详解
技术报告:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
官方代码:Stability-AI-generative-models
模型权重:HuggingFace-Stability AI
非官方代码:Linaqruf/kohya-trainer
diffuser库:diffusers/pipelines/stable_diffusion_xl
通过各种实验验证,SDXL已经超越了先前发布的各种版本的Stable Diffusion,并且与当前未开源的文生图SOTA模型(如midjorney)具有不相上下的效果。本文将介绍SDXL相比于之前的SD(SD1.5, SD2.0等)改进之处。相比之前各个版本的SD,SDXL 的主要改进之处在于:
- 使用了更大的Unet backbone,大约是之前版本SD的3倍
- 使用了几个简单但是非常有效的训练技巧,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等
- 增加了一个refinement 模块来改善生成图片的质量
本文主要根据技术报告SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis来讲解SDXL的原理,在下一篇文章中我们会通过源码解读来进一步理解SDXL的改进点。
1. SDXL原理
1.1 整体架构
SDXL和之前的版本一样也是基于latent diffusion架构,对于latent diffusion,首先会采用一个autoencoder模型来图像压缩为latent,然后扩散模型用来生成latent,生成的latent可以通过autoencoder的decoder来重建出图像。SDXL整体模型结构如下图所示:

相比之前SD版本,Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。
相比SD1.x和SD2.x,SDXL使用了更大的backbone,下图展示了三者结构和参数量上的对比,SDXL的参数量大约为之前版本的SD的3倍

1.2 VEA
SDXL的autoencoder依然采用KL-f8,但是并没有采用之前的autoencoder,而是基于同样的架构采用了更大的batch size(256 vs 9)重新训练,同时对模型的参数采用了EMA(指数移动平均),从而改善生成图片的局部和高频细节。重新训练的VAE模型相比之前的模型,其重建性能有一定的提升,下图展示了在COCO2017验证集上的测试结果。PNSR和SSIM指标越大越好,LPIPS和FID指标越小越好,具体可参考文章[1][2]。

上表中的三个VAE模型其实模型结构是完全一样,其中SD-VAE 2.x只是在SD-VAE 1.x的基础上重新微调了decoder部分,但是encoder权重是相同的,所以两者的latent分布是一样的,两个VAE模型是都可以用在SD 1.x和SD 2.x上的。但是SDXL-VAE是完全重新训练的,它的latent分布发生了改变,不可以将SDXL-VAE应用在SD 1.x和SD 2.x上。在将latent送入扩散模型之前,我们要对latent进行缩放来使得latent的标准差尽量为1,由于权重发生了改变,所以SDXL-VAE的缩放系数也和之前不同,之前的版本采用的缩放系数为0.18215,而SDXL-VAE的缩放系数为0.13025。
1.3 Unet
SDXL相比之前的版本,Unet的变化主要有如下两点:
- 采用了更大的UNet,如1.1章节中的表可以看到,之前版本的SD Unet 参数量为860M,而SDXL参数量达到了2.6B,大约是其的3倍。
- Unet 结构发生了改变,从之前的4stage变成了3stage
图1.3.1和图1.3.2分别展示了SDXL和SD1.x的Unet结构图
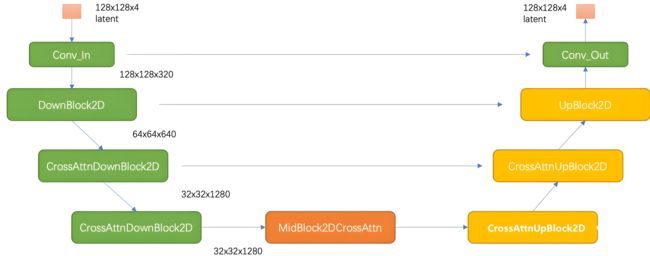
如上图所示,相比之前的SD,SDXL的第一个stage采用的是普通的DownBlock2D,而不是采用基于attention的CrossAttnDownBlock2D;此外,SDXL只用了3个stage,只进行了两次2x下采样,而之前的SD使用4个stage,包含3个2x下采样。SDXL的网络宽度(channels)相比之前的版本并没有改变,3个stage的特征channels分别是320、640和1280。
SDXL参数量的增加主要是使用了更多的transformer blocks,在之前的版本,每个包含attention的block只使用一个transformer block(self-attention -> cross-attention -> ffn),但是SDXL中stage2和stage3的两个CrossAttnDownBlock2D模块中的transformer block数量分别设置为2和10,并且中间的MidBlock2DCrossAttn的transformer blocks数量也设置为10。
1.4 text encoder
SD 1.x采用的text encoder是123M的OpenAI CLIP ViT-L/14,SD 2.x将text encoder升级为354M的OpenCLIP ViT-H/14,SDXL不仅采用了更大的OpenCLIP ViT-bigG(参数量为694M),而且同时也用了OpenAI CLIP ViT-L/14,分别提取两个text encoder的倒数第二层特征,其中OpenCLIP ViT-bigG的特征维度为1280,而CLIP ViT-L/14的特征维度是768,两个特征concat在一起总的特征维度大小是2048,这也就是SDXL的context dim。
如下图所示,OpenCLIP ViT-bigG相比OpenCLIP ViT-H/14,在性能上有一定的提升,其中在ImageNet上zero-shot性能为80.1%

此外,SDXL还提取了OpenCLIP ViT-bigG的 pooled text embedding(用于CLIP对比学习所使用的特征),将其映射到time embedding的维度并与之相加
1.5 训练技巧
SDXL在训练上也使用了很多技巧,主要有如下几点
- 图像尺寸条件化
- 图像裁剪参数条件
- 多尺度(宽高比)图片训练
1.5.1 图像尺寸参数条件
Stable Diffusion 1.x/2.x 的训练过程中,主要分成两个阶段,先在256x256的图像尺寸上进行预训练,然后在512x512的图像尺寸上继续训练。这两个阶段的训练过程都要对图像最小尺寸进行约束。第一阶段中,会将尺寸小于256x256的图像舍弃;在第二阶段,会将尺寸小于512x512的图像舍弃。这样会导致训练数据中的大量数据被丢弃,数据利用率不高,而且很可能导致模型性能和泛化性的降低。
上述问题,一般思路是借助超分模型将尺寸过小的图像放大。但是超分模型可能会在对图像超分的同时会引入一些噪声伪影,影响模型的训练,导致生成一些模糊的图像。
Stable Diffusion XL为了在解决数据集利用率问题的同时不引入噪声伪影,将U-Net(Base)模型与原始图像分辨率相关联,核心思想是将输入图像的原始高度和宽度 c s i z e = ( w origin , h origin ) c_{\text size}=(w_\text {origin}, h_\text {origin}) csize=(worigin,horigin) 作为额外的条件嵌入U-Net模型中,height和width分别都用傅里叶特征编码,然后将特征concat后加在Time Embedding上,将图像尺寸引入训练过程,这样模型在训练过程中能够学习到图像的原始分辨率信息。在推理阶段,用户可以通过 c size c_\text {size} csize 参数设置期望的分辨率,从而更好地适应不同尺寸的图像生成。
上图展示了采用这种方案得到的512x512模型,送入不同的size时的生成图像对比,可以看到模型已经学到了识别图像分辨率,当输入低分辨率时,生成的图像比较模糊,但是当提升size时,图像质量逐渐提升
为了定量分析图像尺寸条件化的效果,作者在ImageNet上基于类别条件训练和验证LDM。作者分别训练了三个模型,其效果如下图所示:
- CIN-512 only:丢弃最小边小于512的所有图片,这导致最终训练集只有70K
- CIN-nocond:使用了所有的训练样本,但是训练时没有加图像尺寸条件
- CIN-size-cond:使用所有图片,并在训练时使用了图像尺寸条件
作者认为CIN-512-only 的差表现主要是因为模型在小数据集上过拟合了,而CIN-nocond效果没有CIN-size-cond的好是因为其生成的模糊图片造成了相似度更低。
1.5.2 图像裁剪参数条件
生成式模型中典型的预处理方式是先调整图像尺寸,使得最短边与目标尺寸匹配,然后再沿较长边对图像进行随机裁剪或者中心裁剪。虽然裁剪是一种数据增强方法,但是训练中对图像裁剪导致的图像特征丢失,可能会导致模型在图像生成阶段出现不符合训练数据分布的特征.
如下图所示,在SD1.x/2.x中会存在生成图像不完整的情况,比如生成的猫的头被裁剪了,并没有生成一个完整的猫。这很大可能就是在训练过程中数据预处理阶段的随机裁剪造成的。
NovelAI在之前就发现了这个问题(NovelAI Aspect Ratio Bucketing Source Code Release),并提出了基于分桶(Ratio Bucketing)的多尺度训练策略,其主要思想是先将训练数据集按照不同的长宽比(aspect ratio)进行分桶(buckets)。在训练过程中,每次在buckets中随机选择一个bucket并从中采样Batch个数据进行训练。将数据集进行分桶可以大量减少裁剪图像的操作,并且能让模型学习多尺度的生成能力;但相对应的,预处理成本大大增加。
Stable Diffusion XL使用了一种简单而有效的条件化方法,即图像裁剪参数条件化策略。其主要思想是在加载数据时,将左上角的裁剪坐标 ( c t o p , c left ) (c_{\text top}, c_\text {left}) (ctop,cleft) 通过傅里叶编码,并与原始图像尺寸一起作为额外的条件嵌入U-Net模型,从而在训练过程中让模型学习到对图像裁剪的认识。在推理时,我们只需要将这个坐标 ( c t o p , c left ) (c_{\text top}, c_\text {left}) (ctop,cleft) 设置为(0, 0)就可以得到物体居中的图像。
下图展示了采用不同的crop坐标的生成图像对比,可以看到(0, 0)坐标可以生成物体居中而无缺失的图像,通过调整坐标 ( c t o p , c left ) (c_{\text top}, c_\text {left}) (ctop,cleft) 可以让模型生成对应裁剪的图像
SDXL在训练过程中,可以将两种条件注入(size and crop conditioning)结合在一起使用。在结合一起使用时,首先在通道维度将两者特征向量连接,然后加到Time Embedding上。两个条件结合使用的伪代码如下图所示。

1.5.3 多尺度训练
现实数据集中包含不同宽高比的图像,然而文生图模型输出一般都是512x512或者1024x1024,作者认为这并不是一个好的结果,因为不同宽高比的图像有广泛的应用场景,比如(16:9)。基于以上原因,作为对模型进行了多尺度图像微调。
经过预训练之后,作者借鉴NovelAI所提出的方案 NovelAI Aspect Ratio Bucketing,将数据集中图像按照不同的长宽比划分到不同的buckets上(按照最近邻原则),SDXL所设置的buckets如下表所示,虽然不同的bucket的aspect ratio不同,但是像素总数(宽x高)都接近1024x1024,相邻的bucket其height或者width相差64个pixels。
在训练过程中,每个step可以在不同的buckets之间切换,每个batch的数据都是从相同的bucket中采样得到。在多尺度训练中,SDXL也将bucket size c a r = ( h tgt , w tgt ) c_{ar}=(h_\text{tgt}, w_ \text{tgt}) car=(htgt,wtgt)(即target size)作为条件加入UNet中,这个条件注入方式和之前图像原始尺寸条件注入一样。将target size作为条件,其实是让模型能够显示地学习到多尺度(或aspect ratio)。 在多尺度微调阶段,SDXL依然采用前面所说的size and crop conditioning,虽然crop conditioning和多尺度微调是互补方案,但是这里也依然保持这个条件注入。经过多尺度微调后,SDXL就可以生成不同aspect ratio的图像,SDXL默认生成1024x1024的图像。
1.5.4 小结
SDXL总共增加了4个额外的条件注入到UNet,它们分别是pooled text embedding,original size,crop top-left coord和target size(bucket size)。对于后面三个条件,它们可以像timestep一样采用傅立叶编码得到特征,然后我们这些特征和pooled text embedding拼接在一起,最终得到维度为2816(1280+25623)的特征。我们将这个特征采用两个线性层映射到和time embedding一样的维度,然后加在time embedding上即可,具体的实现代码如下所示
import math
from einops import rearrange
import torch
batch_size =16
# channel dimension of pooled output of text encoder (s)
pooled_dim = 1280
adm_in_channels = 2816
time_embed_dim = 1280
def fourier_embedding(inputs, outdim=256, max_period=10000):
"""
Classical sinusoidal timestep embedding
as commonly used in diffusion models
: param inputs : batch of integer scalars shape [b ,]
: param outdim : embedding dimension
: param max_period : max freq added
: return : batch of embeddings of shape [b, outdim ]
"""
half = outdim // 2
freqs = torch.exp(
-math.log(max_period)
* torch.arange(start=0, end=half, dtype=torch.float32)
/ half
).to(device=inputs.device)
args = timesteps[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
if dim % 2:
embedding = torch.cat(
[embedding, torch.zeros_like(embedding[:, :1])], dim=-1
)
return embedding
def cat_along_channel_dim(x: torch.Tensor,) -> torch.Tensor:
if x.ndim == 1:
x = x[... , None]
assert x . ndim == 2
b, d_in = x.shape
x = rearrange(x, "b din -> (b din)")
# fourier fn adds additional dimension
emb = fourier_embedding(x)
d_f = emb.shape[-1]
emb = rearrange(emb, "(b din) df -> b (din df)",
b=b, din=d_in, df=d_f)
return emb
def concat_embeddings(
# batch of size and crop conditioning cf. Sec. 3.2
c_size: torch.Tensor,
c_crop: torch.Tensor,
# batch of target size conditioning cf. Sec. 3.3
c_tgt_size: torch.Tensor ,
# final output of text encoders after pooling cf. Sec . 3.1
c_pooled_txt: torch.Tensor,
) -> torch.Tensor:
# fourier feature for size conditioning
c_size_emb = cat_along_channel_dim(c_size)
# fourier feature for size conditioning
c_crop_emb = cat_along_channel_dim(c_crop)
# fourier feature for size conditioning
c_tgt_size_emb = cat_along_channel_dim(c_tgt_size)
return torch.cat([c_pooled_txt, c_size_emb, c_crop_emb, c_tgt_size_emd], dim=1)
# the concatenated output is mapped to the same
# channel dimension than the noise level conditioning
# and added to that conditioning before being fed to the unet
adm_proj = torch.nn.Sequential(
torch.nn.Linear(adm_in_channels, time_embed_dim),
torch.nn.SiLU(),
torch.nn.Linear(time_embed_dim, time_embed_dim)
)
# simulating c_size and c_crop as in Sec. 3.2
c_size = torch.zeros((batch_size, 2)).long()
c_crop = torch.zeros((batch_size, 2)).long ()
# simulating c_tgt_size and pooled text encoder output as in Sec. 3.3
c_tgt_size = torch.zeros((batch_size, 2)).long()
c_pooled = torch.zeros((batch_size, pooled_dim)).long()
# get concatenated embedding
c_concat = concat_embeddings(c_size, c_crop, c_tgt_size, c_pooled)
# mapped to the same channel dimension with time_emb
adm_emb = adm_proj(c_concat)
1.6 refiner
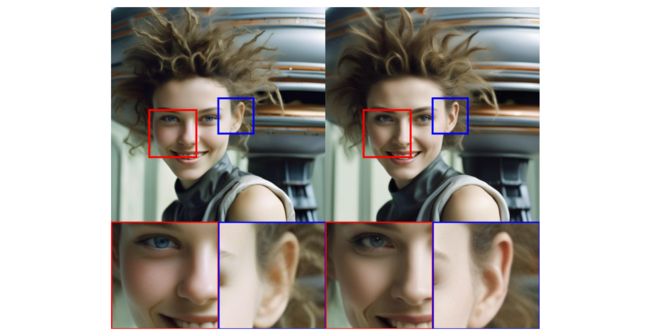
作者发现通过上述方式训练得到的LDM有时候生成的图片局部细节较差,如下图所示,左边是未使用refiner模型产出结果,右边是级联了refiner模型产出结果。
为了提高生成质量,使用高质量和高分辨率的图像在相同的隐空间(latent space)中又训练了一个单独的LDM(通常称之前训练的LDM是base模型,后面训练的LDM是refiner模型)。refiner model是和base model采用同样VAE的一个latent diffusion model,但是它只在使用较低的noise level进行训练(即只在前200 timesteps上)。在推理阶段,首先用base model生成latent,然后我们给这个latent加一定的噪音(采用扩散过程),并使用refiner model进行去噪,并且输入和base model相同的prompt。增加级联后的模型结构如下图所示。
refiner model和base model在结构上有一定的不同,其UNet的结构如下图所示,refiner model采用4个stage,第一个stage采用没有attention的DownBlock2D,网络的特征维度采用384,而base model是320。另外,refiner model的attention模块中transformer block数量均设置为4。refiner model的参数量为2.3B,略小于base model。refiner model的text encoder只使用了OpenCLIP ViT-bigG,也是提取倒数第二层特征以及pooled text embed。

下图展示了增加refiner model和没有增加refiner model生成图片的对比,可见增加refiner model后确实能够改善人物脸部和背景的细节。

1.7 Put All Together
上文我们介绍了SDXL的各个模块,较为分散。现在我们将所有模块合并,来了解SDXL的总体训练过程。
总的来说训练SDXL是一个多阶段过程。
- 首先在内部数据集上对base模型进行预训练:使用255x256分辨率的图像,batch size设置成2048,训练60万个step,这里同时使用了上文所述的size和crop conditioning。
- 在512 x 512 分辨率的图像上继续训练20万step
- 最后在图像总分辨率约为1024x1024的图片上进行多尺度训练,这里训练同时使用了noise-offset技巧
注意以过程是SDXL训练base model的过程,技术报告中并未提及refiner模型训练的具体流程,但猜测与base model可能不太相同,作者强调了refiner model关注于高质量、高分辨率的图片。
1.8 noise-offset
章节1.7中的第三点中提到使用了noise-offset技巧,这里简单介绍介绍下整个技巧:
如果试图让 Stable Diffusion 生成\特别暗或特别亮的图像,它几乎总是生成平均亮度值相对接近0.5的图像(全黑图像为0,全白图像为1),如下图所示,四个prompt 分别为:Top left: A dark alleyway in a rainstorm (0.301); Top right: Monochrome line-art logo on a white background (0.709); Bottom left: A snow-covered ski slope on a sunny day (0.641); Bottom right: A town square lit only by torchlight (0.452)
之所以会出现这个问题,是因为训练和测试过程的不一样,SD所使用的 noise scheduler其实在最后一步并没有将图像完全变成随机噪音,这使得训练过程中学习是有偏的,但是测试过程中,我们是从一个随机噪音开始生成的,这种不一致就会出现一定的问题。offset-noise方法就是在训练过程中给采用的噪音加上一定的offset即可,具体的实现代码如下所示:
# Sample noise that we'll add to the latents
noise = torch.randn_like(latents)
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device
)
加上noise-offset后,同样是上面的promt,生成结果如下所示

2. SDXL效果
2.1 与SOTA模型对比
2.2 与Midjourney5.1比较
这里是基于PartiPrompts来进行对比的,PartiPrompts是谷歌在Parti这个工作中所提出的文生图测试prompts,它包含不同的类别比如动物和人等。
首先作者做了一个整体的测试,每个类别随机选择5个prompts分别使用SDXL和Midjourney v5.1生成4个1024x1024的图像,然后人工来投票,最终的对比结果如下所示,SDXL以微弱的优势战胜Midjourney v5.1(54.9% vs 44.1%)。

然后作者又在不同类目上进行了对比

2.3 与SD1.x相比
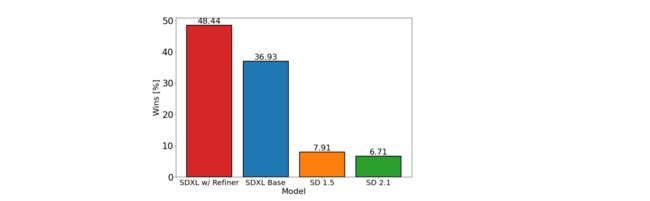
下图展示了用户在SD1.x和SDXL模型结果的偏好程度
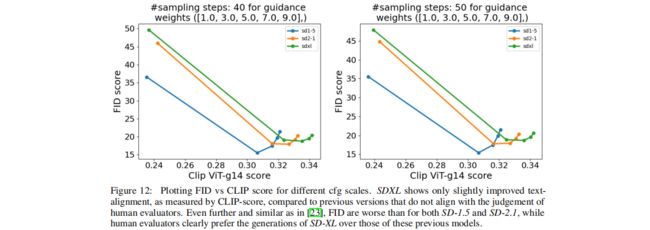
下图比较了SD1.x和SDXL在CLIP score和FID score两个指标上的对比。从CLIP score来看,SDXL采用了更强的text encoder,其CLIP score是最高的,但是从FID来看,SD 1.5是最低的(最好),而SDXL反而是最高(最差)的,直接用FID往往并不能很好地衡量图像的生成质量,因此和上图中人工测评相结合更能展示SDXL的真实表现
下面还展示了一些定性分析结果
3. SDXL局限性
尽管SDXL在生成真实、复杂图像方面相比上一代SD有了非常大的进步,最终效果也是让人足够惊艳,但是仍然存在一些问题,下图展示了SDXL的一些失败case

- 生成复杂结构的物体(如人手)仍然不够好。作者认为出现这样的原因可能是手在每个图片中的(姿势等)差异都比较大,这很难让模型学习到真实3D知识
- 模型生成的图像还是无法达到完美的逼真度,如微妙的灯光效果或微小的纹理变化等
- 该模型的训练过程严重依赖于大规模数据集,这可能会无意中引入社会和种族偏见
- 在样本包含多个对象或主题的情况下,模型可能会出现一种称为“概念混淆(concept bleeding)”的现象(即不同视觉元素的合并或重叠)。如下图,输入prompt为
A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says "SDXL"!,可见第三幅图出现了橙色的眼镜,这里是和橙色的外套弄混淆了
另外的一个case如下,输入prompt为:a baby penguin wearing a blue hat, red gloves, green shirt, and yellow pants,可见其将蓝色帽子和红色手套弄混淆了

作者认为这个问题主要原因在于预训练的文本编码器:首先text-encoder训练时将所有信息压缩到一个token里,导致属性和物品无法正确对应,其次训练时用的对比损失也会导致整个问题的发生,因为要模型正确区分这种对应关系需要不同的属性、物品对应关系的负样本出现在一个batch里,这显然很难。 - 生成清晰且比较长的文字仍然比较困难,生成的文本可能包含随机字符,如下图所示,输入prompt为:
a green sign that says "very deep learning" and is at the edge of the Grand Canyon
综上所述,尽管SDXL模型在图像生成方面具有显著的优势,但也存在一定的局限性。与合成复杂的结构、实现完美的真实感、进一步解决偏见、减轻概念混淆和改进文本渲染相关的挑战突出了未来研究和优化的途径。作者也提出了未来需要进一步改进的工作:
- 简化两阶段为单阶段模型:当前模型是base model + refiner mode 的两阶段模型,这造成需要更大内存来加载两个大模型,且对生成速度造成了很大影响
- 提高文本生成能力:与之前的SD相比,使用更大的text encoder提高了文本渲染能力,但是与byte-level的tokenizer相结合或简单的将模型进一步增大也许会进一步提升文本生成能力
- 模型结构可继续改进:可以尝试基于transformer的结构
- 知识蒸馏:通过知识蒸馏来减小模型规模,从而提高推理速度
- 在连续时间上训练
关注公众号 funNLPer 了解更多AI算法
4. 参考
- [1]. 有真实参照的图像质量的客观评估指标:SSIM、PSNR和LPIPS
- [2]. 图像质量评估—FID
- [3]. REACHING 80% ZERO-SHOT ACCURACY WITH OPENCLIP: VIT-G/14 TRAINED ON LAION-2BREACHING 80% ZERO-SHOT ACCURACY WITH OPENCLIP: VIT-G/14 TRAINED ON LAION-2B
- [4]. 文生图模型之SDXL
- [5]. GAN的量化评估方法——IS和FID,及其pytorch代码
- [6]. 深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
- [7]. Diffusion With Offset Noise