从零开始学习YOLOv5 保姆级教程
一、前言
YOLO系列是one-stage且是基于深度学习的回归方法,而R-CNN、Fast-RCNN、Faster-RCNN等是two-stage且是基于深度学习的分类方法。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升

Input: 输入部分是YOLOv5的起点,接收输入图像并将其进行预处理,将图像大小调整为模型所需的输入尺寸。
Backbone: 骨干网络是YOLOv5的核心组成部分,负责从输入图像中提取特征。YOLOv5使用的骨干网络是一种轻量级的卷积神经网络,如CSPDarknet53或Swin-Transformer,具有良好的特征提取能力。
Neck: Neck部分是YOLOv5中的特征融合模块,用于融合不同层级的特征图。常用的脖子结构包括特征金字塔网络(FPN),用于增强目标的多尺度表示和语义信息的融合。
Output: 输出部分是YOLOv5的最终预测结果生成模块,通过在不同尺度的特征图上应用一系列卷积层和激活函数,输出目标的位置坐标、类别概率和置信度。根据预测结果进行后处理,如非极大值抑制(NMS),用于过滤和合并重叠的边界框,得到最终的检测结果。
源码下载地址
ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite (github.com)
二.环境配置
最新Anaconda安装-保姆级教程
Pytorch安装教程:最新保姆级教程
完全零基础的可以先看下博主的这两篇文章先做好基础准备
2.1.创建环境
打开命令行,输出cmd,在终端输入一下命令
conda create -n yolov5 python=3.8 # yolov5为所创建虚拟环境名称;python版本可以更换
推荐用3.8,不容易报错。
第一次建可能需要一些时间
2.2环境内配置pytorch
激活环境
conda activate yolov5配置pytorch
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple这是换好源的下载链接,如果20分钟内没有下载完,需要考虑是不是有地方出错了,正常10分钟左右搞定。
验证是否成功
python
import torch
print(torch.__version__)
print(torch.cuda.is_available())输出为 ture就成功了
2.3.环境依赖安装
yolov5 依赖包和环境一键安装
如果你的电脑里有多个requirements.txt文件,需要cd 到指定的文件夹下载之星以下命令。
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/这时你打开你下载的YOLOv5的模型应该就能跑了。
三.运行YOLOv5
打开detect.py
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
只需要注意这两个参数:如下图所以,正常情况是不需要动的
source :指向的是图片地址
weights:是权重参数
yolov5s.pt文件需要去官网下载
官网的界面往下翻
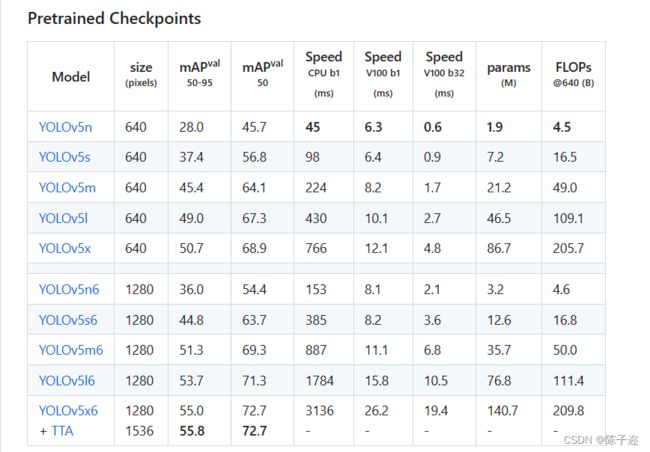
点击你想下载的权重文件,这边可以直接下载yolov5s就可以了

下载完直接放在最外边就可以了,如果读取不了,就用绝对路径。

run 运行
按照提示找到保存图片的地方
至此,yolov5版的hello world就成功了
有遇到问题的小伙伴,欢迎评论区留言