shell&变量替换
目录
1.shell变量替换
替换数据
shell变量运算
1.整数运算
2. 小数运算
扩展
脚本题

1.shell变量替换
#从左往右最短删除匹配符号. #从前往后删除时*.
例:
Uel="www.baidu.com"
echo ${Uel}
www.baidu.com
echo ${Uel#*.}
baidu.com##从左往右最长删除匹配符号.
例:
Uel="www.baidu.com"
echo ${Uel}
www.baidu.com
echo ${Uel##*.}
com#从右往左最短删除 #从后往前删除时.*
Uel="www.baidu.com"
echo ${Uel}
www.baidu.com
echo ${Uel%.*}
www.baidu##从右往左最长删除匹配符号
Uel="www.baidu.com"
echo ${Uel}
www.baidu.com
echo ${Uel%%*.}
www替换数据
/源值/更改值 默认只替换第一个值
Uel="www.baidu.com,www.taobao.com,www.jd.com"
echo ${Uel} #输出变量
www.baidu.com,www.taobao.com,www.jd.com
echo ${Uel/www/} #删除第一个www
.baidu.com,www.taobao.com,www.jd.com更改值为空的等同于删除
两个//表示全部(整行里)替换
Uel="www.baidu.com,www.taobao.com,www.jd.com"
echo ${Uel} #输出变量
www.baidu.com,www.taobao.com,www.jd.com
echo ${Uel//www/} #删除整行里全部www
.baidu.com,www.taobao.com,www.jd.com例:查找文件 输出到一个文件里改名后备份并还原
mkdir /data
cd /data
mkdir file{1..10}.txt
mkdir /backup
cd /backup
vi file.sh
---------------------------------------------------------
#!/bin/bash #解释器名称
dir="/dackup"
time=$(date +%F)
find /data -type f -name "*.txt" |xargs &> /root/m.txt
for i in $(cat /root/m.txt)
do
mv ${i} ${i}.bak #给变量值改名
done
tar zcf ${dir}/file-${time}.tar.gz /data
find /data -type f -name "*.bak" |xargs &> /root/m.txt
for i in $(cat /root/m.txt)
do
mv ${i} ${i%.*} #还原
done
---------------------------------------------------------
chmod +x file.sh
./file.shxargs 格式化,使得横向显示
echo ${#str} #str 变量名 查询变量值的个数
案例
定义变量,happiness="towards the sea, with spring flowers blossoming,the the"
执行脚本,输出变量,并要求:
1) 打印变量值字符串长度
2) 删除所有的the
3) 替换第一个the为that
4) 替换所有the为that
用户按“1|2|3|4” ,输出相应选项内容。
vim happiness.sh
#!/bin/bash
happiness="towards the sea, with spring flowers blossoming,the the"
echo $happiness
cat <shell变量运算
1.整数运算
expr、$(())、$[],不支持小数运算
a+b 加
a-b 减
a*b 乘(expr计算时,用 \* )
expr ${num1} \* ${num2}

a/b 除
a%b 余
例1:
a=20 b=10 expr $a + $b echo $(( a + b )) echo $[ $a + $b ]
例2:递增和递减
echo $((a++)) 先取值后自增 echo $((a--)) 先取值后自减 echo $((++b)) 先自增后取值 echo $((--b)) 先自减后取值 echo $((100*(1+100)/2)) 求1到100之和
2. 小数运算
bc工具 安装
yum -y install bc
echo "2*4" |bc
echo "2^4" |bc
echo "scale=2;3/2" |bc 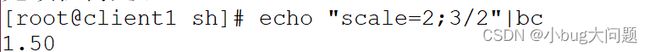
awk 'BEGIN{print 3/2}'扩展
流程控制语句--整数比对
-eq 等于则为真 [ $? -eq 0 ]
-ne 不等则为真 [ $? -ne 0 ]
-gt 大于则为真 [ 1 -gt 2 ]
-lt 小于则为真 [ 1 -lt 2 ]
-ge 大于等于则为真 [ 1 -ge 2 ]
-le 小于等于则为真 [ 1 -le 2 ]
脚本题
例1:查看内存使用率,仅保留整数
vim mem_use.sh #!/bin/bash Mem_use=$(free -m |grep ^M |awk '{print $3/$2*100}') if [ ${Mem_use%.*} -ge 80 ];then echo "memory is overfull: ${Mem_use%.*}%" else echo "memory is OK: ${Mem_use%.*}%" fi例2:查看磁盘使用状态,使用率超出80%就报警
思路:
怎么查看磁盘
怎么提取使用率
整数判断
vim disk.sh #!/bin/bash Disk=$(df -h |grep /$ |awk '{print $(NF-1)}') if [ ${Disk%\%} -ge 80 ];then echo "你的磁盘使用率过高:$Disk" else echo "你的磁盘使用率正常:$Disk" fi
正则表达式
==========================正则表达式======================
特殊字符:
$ 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。
( ) 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。
* 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。
+ 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。
. 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。
? 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。
\ 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。
^ 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。
{ 标记限定符表达式的开始。要匹配 {,请使用 \{。
| 指明两项之间的一个选择。要匹配 |,请使用 \|。
限定符:
* 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于 {0,}。
+ 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}。
{n} n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o。
{n,}n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。
{n,m} m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。
例子1:/[1-9][0-9]*/ 表示非0的正整数
例子2:/[0-9]{1,2}/ 表示从0-99
例子4:/[1-9][0-9]?/ 表示从1-99
修饰符
i ignore - 不区分大小写 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。
g global - 全局匹配 查找所有的匹配项。
m multi line - 多行匹配 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。