小常识10: 循环神经网络(RNN)与长短时记忆网络LSTM简介。
小常识10: 循环神经网络(RNN)与长短时记忆网络LSTM简介。
本文目的:在计算机视觉(CV)中,CNN 通过局部连接/权值共享/池化操作/多层次结构逐层自动的提取特征,适应于处理如图片类的网格化数据。在自然语言处理(NLP)中,循环神经网络被设计用于处理序列的神经网络,如应用 RNN 在语音识别,语言建模,翻译等。同时,现有的计算机视觉研究开始结合CNN与RNN的使用,应用于视频目标检测,图像字幕生成等既有图像数据,又具备序列化特点的任务。所以了解循环神经网络及其变种,有助于更好的理解神经网络的设计理念,能在不同的任务中合理选用不同的神经网络。
循环神经网络(RNN):
RNN是在自然语言处理领域中最先被用起来的,比如,RNN可以为语言模型来建模。我们写出一个句子前面的一些词,然后,让电脑帮我们写下接下来的一个词。比如下面这句:
我昨天上学迟到了,老师批评了____。
语言模型是对一种语言的特征进行建模,它有很多很多用处。比如在语音转文本(STT)的应用中,声学模型输出的结果,往往是若干个可能的候选词,这时候就需要语言模型来从这些候选词中选择一个最可能的。当然,它同样也可以用在图像到文本的识别中(OCR)。
使用RNN之前,语言模型主要是采用N-Gram。N可以是一个自然数,比如2或者3。它的含义是,假设一个词出现的概率只与前面N个词相关。我们以2-Gram为例。如果用2-Gram进行建模,那么电脑在预测的时候,只会看到前面的『了』,然后,电脑会在语料库中,搜索『了』后面最可能的一个词。不管最后电脑选的是不是『我』,我们都知道这个模型是不靠谱的,因为『了』前面说了那么一大堆实际上是没有用到的。如果是3-Gram模型呢,会搜索『批评了』后面最可能的词,感觉上比2-Gram靠谱了不少,但还是远远不够的。因为这句话最关键的信息『我』,远在9个词之前!现在读者可能会想,可以提升继续提升N的值呀,比如4-Gram、5-Gram.......。实际上,这个想法是没有实用性的。因为我们想处理任意长度的句子,N设为多少都不合适;另外,模型的大小和N的关系是指数级的,4-Gram模型就会占用海量的存储空间。
所以,该轮到RNN出场了,RNN理论上可以往前看(往后看)任意多个词。

在上面的示例图中,神经网络的模块A,正在读取某个输入 x_i,并输出一个值 h_i。循环可以使得信息可以从当前步传递到下一步。RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开:
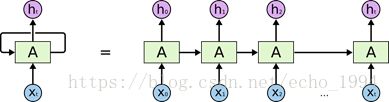
链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
以下是RNN的常用场景的输入输出结构图:

· many to one:常用在文本分类等任务中,将一句话关联到一个向量。并通过向量进行文本分类。
· many to many:第一个many to many在DNN-HMM语音识别框架中常有用到
· many to many(variable length):第二个many to many常用在机器翻译等任务。
以many to many为例,以下的神经网络结构将一个输入序列映射到相同长度的输出序列:

则其更新方程为:

其中的参数的偏置向量 b 和 c 连同权重矩阵 U、V 和W,分别对应于输入到隐藏、 隐藏到输出和隐藏到隐藏的连接。
训练算法:BPTT
篇幅限制,请参考 https://zybuluo.com/hanbingtao/note/541458
存在的缺点:
RNN的梯度爆炸和消失问题:RNN在训练中很容易发生梯度爆炸和梯度消失,这导致训练时梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。
通常来说,梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题: 1.合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
2.使用relu代替sigmoid和tanh作为激活函数。
3.使用其他结构的RNNs,比如长短时记忆网络(LTSM)
长短时记忆神经网络(LSTM):
其设计思路如下:
原始RNN的隐藏层只有一个状态,即h[隐藏状态],它对于短期的输入非常敏感,但是由于梯度消失问题的存在,使得其无法有效的对长序列建模,因此,lstm通过新增加一个状态,记作c[细胞状态],让它来保存长期的状态。以下为lstm的结构图:

为了模块组件的说明如下:

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

LSTM 通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
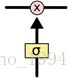
Sigmoid层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。
理解Lstm的关键在于理解其设计的三个门结构,分别是输入门,遗忘门,输出门。结合其更新方程来理解具体的设计:
【为便于阅读,直接截图,原始网页见参考资料3贴出的网页链接.】




扩展阅读:
1.除以上介绍的LSTM网络被广泛应用外,现有的针对序列数据的处理方式的改进有GRU(Gated Recurrent Unit)等计算复杂度更低的循环神经网络变种。同时BiLstm利用了序列的双向特性,被广泛应用在序列建模中。另外,循环神经网络的变种与传统机器学习序列模型的结合也值得关注,如LSTM+CRF应用于自然语言处理的标注类任务。
2.在机器学习领域中,Attention机制被广泛应用于各种序列建模的任务并且均取得了良好效果。推荐查阅相关的资料及论文,了解基于RNN/LSTM等序列模型结合Attention机制的应用。
参考资料:
1. https://zybuluo.com/hanbingtao/note/541458 [零基础入门深度学习(5) - 循环神经网络]
2. https://zybuluo.com/hanbingtao/note/581764 [零基础入门深度学习(6) - 长短时记忆网络(LSTM)]
3. https://www.cnblogs.com/wangduo/p/6773601.html?utm_source=itdadao&utm_medium=referral [理解 LSTM(Long Short-Term Memory, LSTM) 网络]
4. https://github.com/exacity/deeplearningbook-chinese/ [Deep Learning ]