论文阅读 CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
文章目录
-
- CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
-
- Abstract
- I. INTRODUCTION
- II. RELATED WORK
- III. PROPOSED METHOD
-
- A. Leveraging Contextual Information
- B. Spatial-and-Scale-Aware Attention Module
- IV. EXPERIMENTS
-
- A. Datasets and Evaluation Metrics
- B. Implementation Details
- C. Experimental Results
- D. Ablation Study
- V. CONCLUSIONS
CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
Abstract
准确且稳健地检测光学遥感图像中的多类对象对许多现实世界应用至关重要,如城市规划、交通控制、搜索和救援等。然而,针对ground-level传感器捕获的图像设计的目标检测技术,在直接应用于遥感图像时通常会出现明显的性能下降,这在很大程度上是由于遥感图像中对象外观差异造成的,这些差异包括稀疏纹理、低对比度、任意方向、大尺度变化等。本文提出了一种新颖的目标检测网络(CAD-Net),它利用attention-modulated特征以及全局和局部上下文来解决从遥感图像中检测对象面临的新挑战。CAD-Net通过捕捉与全局场景的联系 (at scene-level)和与局部相邻对象或特征(at object-level)的相关性,学习了objects的全局和局部上下文信息。此外,设计了一个 spatial-and-scale-aware的注意力模块,引导网络集中关注更具信息量的区域和特征,以及更合适的特征尺度。在两个公开可用的遥感图像目标检测数据集上进行的实验表明,所提出的CAD-Net实现了优越的检测性能。
I. INTRODUCTION
近年来,卫星和遥感技术的最新进展导致每天产生大量的高清遥感图像,这远远超出了任何手动操作和处理的范围。因此,自动分析和理解遥感图像对于使这些图像在城市规划、搜索、救援、环境监测等许多现实世界应用中变得至关重要。特别是,多类对象检测,即在遥感图像中同时定位和分类各种对象(如飞机、车辆、桥梁、环形交叉口等),由于传感器分辨率的提高。这一挑战超越了传统的场景级分析,旨在识别遥感图像的场景语义,如建筑物、草地、海洋等。
深度神经网络,特别是卷积神经网络(CNN),在近年来极大地推动了目标检测的发展。已经提出了许多基于CNN的目标检测器,通过在诸如PASCAL VOC和MS COCO、等多个大规模目标检测数据集上取得了非常有希望的结果。另一方面,大多数现有技术在应用于遥感图像时通常会出现明显的性能下降,主要是由于以下三个因素所致,如图1所示。首先,光学遥感图像中的对象通常缺乏图像对比度和纹理细节等视觉线索,这对于最先进的检测技术的性能至关重要。其次,遥感图像中的对象通常密集分布,出现任意方向并且具有大尺度变化,这使得目标检测变得更加具有挑战性。第三,光学遥感图像中捕获的对象通常受到大量噪声的影响,这是由于在光线被反射并传播回卫星传感器时遭受各种干扰。

在这项工作中,我们设计了一种Context-Aware Detection Network(CAD-Net)用于光学遥感图像中的目标检测。图2显示了所提出的CADNet的概述。如图2所示,CAD-Net包括一个全局上下文网络(GCNet),该网络学习interested objects与其相应 global scenes之间的关联,即对象特征与整个图像特征之间的关联。GCNet受到这样的观察启发,光学遥感图像通常涵盖大范围的区域,其中场景级语义通常对对象位置和对象类别提供重要线索,例如船只通常出现在海洋/河流中,直升机很少出现在居住区周围等。此外,CAD-Net还包括一个Pyramid
Local Context Network (PLCNet),该网络学习与 objects of interest周围的multi-scale cooccurrence features and/or co-occurrence objects。与由地面传感器捕获的图像相比,顶视角的遥感图像通常包含更丰富且更具区分性的 co-occurrence features and/or objects,这对于对象类别和位置推理非常有用,例如车辆彼此相互出现,港口中的船只,河流上的桥梁等。此外,设计了一个空间和尺度感知的注意力模块,引导网络关注适当图像尺度上更具信息量的上下文区域。

本工作的贡献有四个方面。首先,它设计了一种创新的上下文感知网络,用于在光学遥感图像中学习全局和局部上下文,以实现最佳的目标检测。据我们所知,这是第一次在遥感图像的目标检测中融合全局和局部上下文信息。其次,它设计了一个空间和尺度感知的注意力模块,引导网络在适当的图像特征尺度上关注更具信息量的区域。第三,它验证了遥感目标检测的独特性,并为弥合与由地面传感器捕获的图像的目标检测之间的差距提供了富有洞察力和创新性的解决方案。第四,不需要过多复杂的设计,它开发了一个端到端可训练的检测网络,在两个具有挑战性的遥感图像目标检测数据集上实现了最先进的性能。
II. RELATED WORK
略过
III. PROPOSED METHOD
我们提出的上下文感知检测网络(CAD-Net)的框架如图2所示。CAD-Net基于经典的两阶段检测网络结构 - Faster RCNN ,并结合了FPN。我们设计了一个全局上下文网络(GCNet)和一个金字塔局部上下文网络(PLCNet),分别用于提取global scene level和 local object level的上下文信息。我们还设计了一个空间和尺度感知的注意力模块,引导网络集中关注更具信息量的区域,以及更适当的图像特征尺度。所有设计的组件都是现成的,可以被整合到现有的检测网络中,无需任何适应和额外的监督信息。更多细节将在接下来的小节中讨论。
A. Leveraging Contextual Information
给定一张图像 I 和一个region proposal P,相对于 P 的对象 OP 的检测可以被表述为
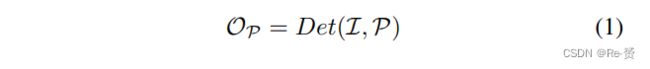
其中,Det(·)表示joint的对象分类和边界框回归。在广泛采用的region-based的检测方法中,方程式1通常通过RoIPooling 来近似,该方法引导网络关注 proposal region并忽略图像的其余部分。因此,新的表述可以表示为

其中,Ψ(·)表示RoIPooling操作。
方程式2中的近似是基于这样的假设:特定区域P的所有有用信息都位于区域本身内。这个假设适用于大多数来自地面传感器的图像,其中通常捕获和保留了有辨别力的对象特征。但是对于光学遥感图像,由于各种噪声和信息丢失,边缘和纹理等有辨别力的对象特征通常会严重退化。在这种情况下,与感兴趣对象紧密相关的全局和局部上下文变得重要,并且应该被纳入以补偿feature degradation和information loss。因此,全局和局部上下文的融合可以被表述为:
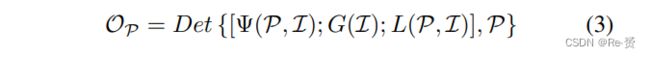
其中,G(·)表示用于获取全局上下文特征的GCNet,L(·)表示用于获取局部上下文特征的PLCNet,(· ; ·)表示串联。
-
Global Context Network:遥感图像通常捕捉到大片区域,携带了强烈语义信息。此外,所拍摄场景的语义常常与场景内的对象密切相关,例如海洋与船只,机场与飞机等。基于这些观察,我们设计了一个全局上下文网络(GCNet),该网络学习全局场景语义,并将其用作更好地检测遥感图像中的对象的priors。更具体地说,GCNet学习了场景与场景内对象之间的关联,并将所学关联作为一定的全局上下文,以弥补辨别性对象特征的损失。GCNet可以被表述为:
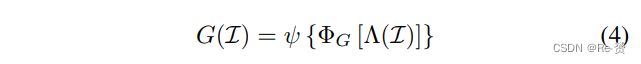
其中,Λ(I)表示特征提取网络的最终特征图,即ResNet-101主干网络的C5级,如图2所示。ΦG(·)由一系列卷积层实现,用于提取全局特征,ψ(·)表示一个池化操作,将特征图的空间通道压缩成一个向量,有助于抑制对尺度变化的敏感性。在我们实现的系统中,我们经验性地采用了全局平均池化作为ψ(·) -
Pyramid Local Context Network: 除了全局上下文外,描述对象与其相邻对象and/or特征之间的局部上下文也捕获了有用的信息,并可以用来弥补信息损失。基于对象和它们的局部上下文都对尺度敏感的观察,我们设计了一个金字塔局部上下文网络(PLCNet),以学习对象与它们的局部上下文之间的对象/特征关联,如图3所示。

给定一个region proposal P(例如,图3中红色框中的船只proposal),一组不同尺度的相应区域的局部上下文被用来学习环绕 P 的跨尺度局部上下文,如图3所示。设计了一个上下文金字塔,首先提取和串联不同尺度的pooled features,然后通过卷积(即图3中的Conv)融合串联特征。最终融合的特征与区域特征以及前述的全局上下文特征一起,用于proposal分类和边界框回归。
如图3所示,即使是人类也会发现仅仅关注所提出的区域本身很难确定所提出的区域(在红色框中突出显示)是否是一艘船。在这种情况下,来自不同尺度的局部上下文(例如图3中显示的船只群和港口)将提供强有力的线索,表明区域提案很可能是一艘船。PLCNet被训练以学习这种相关的特征和/或对象,这在光学遥感图像中的稀疏纹理、低对比度以及严重信息丢失的情况下经常非常有帮助。
B. Spatial-and-Scale-Aware Attention Module
视觉注意力在计算机视觉任务中已被证明非常有用,例如图像描述、场景文本识别等。这个想法受到了人类视觉系统的启发,人类视觉系统不会一次性处理整个图像,而倾向于顺序地关注更具信息量的区域。在这项工作中,我们设计了一个空间和尺度感知的注意力模块,该模块学会自适应地关注相关尺度的特征图上突出的区域(空间感知和尺度感知)。空间感知特征有助于网络处理具有稀疏纹理和低对比度的对象与背景,而尺度感知特征有助于处理不同尺度的对象。这两者的结合有助于遥感图像学习目标检测模型。

提出的空间和尺度感知注意力模块是建立在由FPN生成的特征金字塔上的,该金字塔提取了特征图P2−P5,如图4所示。对于特定尺度的特征Pi(其中i ∈ [2, 5]),attention-modulated的特征图如下确定:

其中,σ(·) 是 sigmoid 函数,Si 是第 i 个特征图的注意力图,Ai 是第 i 个attention-modulated的特征图,而o表示逐元素相乘。注意力图计算 Φi(·) 通过一系列卷积层实现。注意,每个特定尺度都有一个单独的 Φi(·) 来计算相应的注意力图。这种设计确保了我们提出的注意力模块既具有空间感知性,也具有尺度感知性,使其能够在适当的尺度上关注更具信息量的区域,同时抑制不相关的信息。
图5显示了由所提出的空间和尺度感知的注意力模块生成的attention response maps。如图5所示,我们提出的注意力模块不仅具有空间感知性,还具有尺度感知性,可以选择性地关注不同尺度特征的更具信息量的区域。例如,小尺度的船只在更低层的网络层次 A2 和 A3(如图4所示)中获得更强的响应,这些层次捕获了更多的详细信息,而大尺度的港口则在更深的网络层次 A4 和 A5 中获得更强的响应,这些层次捕获了更高层次的信息,如第一个示例图像所示。此外,我们的注意力模块能够引导网络关注被噪声降低的有用纹理细节,例如第一个示例图像中港口的骨架和第二个示例图像中球场的中线。

IV. EXPERIMENTS
A. Datasets and Evaluation Metrics
略过
B. Implementation Details
Ground Truth Generation DOTA以四边形格式提供objects of interest的注释,而NWPU-VHR10以传统的轴对齐边界框格式提供注释。为了适应不同的设置,所提出的CAD-Net使用水平边界框(HBB)和方向边界框(OBB)作为 ground truth:

其中,θ位于[0, 90°)范围内,以确保每个对象只有一个ground truth。在训练中,根据一组与四边形注释最佳重叠的旋转矩形生成了如公式(8)中定义的OBB ground truth。对于DOTA数据集,我们提出的CAD-Net生成了HBB结果和OBB结果,如图2所示。对于NWPU-VHR10数据集,CAD-Net只生成HBB结果,因为该数据集未提供OBB地面真值。
Data Pre-processing 光学遥感图像通常具有巨大的图像尺寸,例如DOTA图像的尺寸可以高达6,000 × 6,000像素。为了适应训练阶段的硬件内存,我们将图像裁剪成尺寸为1,600 × 1,600像素的patches,相邻patches之间有800像素的重叠。在推断阶段,从测试图像中裁剪出尺寸为4,096 × 4,096像素的图像patches,相邻patches之间有1,024像素的重叠。如果图像尺寸小于裁剪的图像patches,则会进行零填充。还会执行其他标准的预处理过程,如全局对比度归一化。
Network Setup 我们采用ResNet-101 作为特征提取的网络主干。作为常见的做法,这个ResNet-101在ImageNet上进行预训练,然后在我们的训练过程中进行微调。由于遥感图像中的对象通常具有任意方向,我们所提出的CAD-Net被设计为能够同时生成HBB和OBB。
我们采用(SGD)进行网络优化。我们的模型在单个Nvidia Tesla P100 SXM2 GPU上进行训练,具有16GB的内存,使用了深度学习框架PyTorch 。批量大小设置为1。DOTA和NWPU-VHR10的总训练迭代次数分别为130,000和30,000,分别需要大约36小时和6小时。
C. Experimental Results
表I显示了在DOTA数据集的测试集上的实验结果,并与最先进的方法进行了比较。注意,表中列出的所有方法都采用了ResNet-101作为主干网络,除了YOLO v2和SSD分别采用了GoogLeNet和Inception网络。如表I所示,我们提出的CAD-Net在平均精度上超过了基线模型Faster RCNN(表中的FR-O),超出了15.8%,证明了它在遥感图像中的目标检测有效性。此外,在两个training setups下的表现优于最先进的方法,提升幅度最高达2%(“T”表示只使用训练图像进行训练,“T+V”表示训练图像和验证图像均用于训练)。此外,我们还指出,Azimi的方法采用了Inception模块 、可变形卷积 、在线困难样本挖掘(OHEM)、多尺度训练和推断等技术,而我们的目标是设计一个干净高效且性能出色的模型。通过包括这些经过充分验证的性能提升组件,我们的模型应该能够实现更高的检测准确度。

我们还在NWPU-VHR10数据集上对所提出的CAD-Net进行评估,并与最先进的方法进行了基准比较。由于NWPU-VHR10未指定训练和测试集的划分,我们按照广泛采用的划分方案随机选择了75%的正样本图像作为训练集,其余的正样本图像作为测试集,不包括任何负样本图像用于训练。表II显示了实验结果和与最先进方法的比较。我们提供了CAD-Net在NWPU-VHR10数据集上的3个随机分离的实验结果,以提供更有说服力的结果。如表II所示,与最先进的方法相比,所提出的CAD-Net也获得了卓越的目标检测性能。

图6展示了来自DOTA数据集的几个示例图像,以及使用基线模型(Faster RCNN与FPN)的检测结果(第一行),以及使用所提出的CAD-Net的检测结果(第二行)。如图6所示,最先进的通用检测技术Faster RCNN与FPN在不同情况下往往会产生错误的检测,例如第一个示例图像中的船只(被误检为大型车辆),第二个示例图像中不同风格的储罐(被误检为环形交叉口),第三个示例图像中被船只遮挡的港口和纹理细节较少的船只(false negatives),以及第四个示例图像中与背景对比度非常低的车辆(false negatives)。作为对比,所提出的CAD-Net能够在如图6第二行所示的各种不利情况下正确检测出这些物体。
卓越的检测性能很大程度上归因于所提出的CAD-Net内部包含了全局上下文、局部上下文、空间和尺度感知的注意力、强大且平衡的语义信息以及准确的旋转角度回归(如第III节所述)。
另一方面,在图6的第三行中,所提出的CAD-Net仍然容易在几种典型情况下出现检测失败。首先,如第一个示例图像所示,所提出的CAD-Net对强光干扰很敏感,这主要是由于训练集中缺乏相关的训练图像。其次,即使小型车辆的视觉质量良好(如第二个示例图像所示),CAD-Net也经常会产生漏检。我们坚信,这主要是由于训练图像的注释不准确。特别是,许多小型车辆没有被标注,可能是由于图像中大量的小型车辆和有限的人力资源。第三,CAD-Net可能无法检测到长而细的物体,例如桥梁,如第三个示例图像所示。这是基于proposal的检测技术(如Faster RCNN)的常见限制,它只能为具有有限宽高比的物体使用有限数量的锚点。第四,CAD-Net仍然倾向于错过那些严重重叠的物体,如第四个示例图像所示。我们认为这个问题可以通过合适的非极大值抑制(NMS)来更好地解决,我们将在未来的工作中进行探究。
D. Ablation Study
略过
V. CONCLUSIONS
This paper presents a novel CAD-Net, an accurate and robust detection network for objects in optical remotes sensing images. Global Context Network (GCNet) and Pyramid Local Context Network (PLCNet) are proposed, which extract scenelevel and object-level contextual information that is highly correlated to objects of interest and often provide extra guidance for object detection in remote sensing images. In addition, a spatial-and-scale-aware attention module is designed which guides the network to focus on scale-adaptive features for feature maps from each level and also to emphasize the degraded texture details. Extensive experiments over two public available datasets verify the uniqueness of object detection in remote sensing images, and also show that the proposed CADNet achieves superior object detection performance as compared with state-of-the-art techniques. On the other hand, the CAD-Net still tends to fail under several typical scenarios for ultra-long or heavily overlapped objects. We will investigate new approaches that is capable of better leveraging contextual information for more robust object detection in remote sensing images.