IT运维:使用数据分析平台监控 Kafka 服务
Apache Kafka 是由 LinkedIn 开发,并于2011年开源的分布式消息队列服务。但是通过快速持续的演进,目前它发展成为成熟的事件流处理平台,可用于大规模流处理、实时数据管道和数据集成等场景。
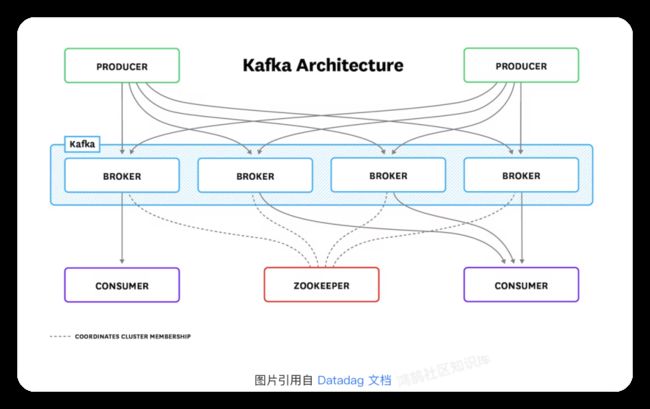
Kafka 的服务端组件包括一个或者多个 broker。Broker 按照 topic 来管理数据的分区、复制以及存储,并提供针对 topic 的发布/订阅(简称“pub/sub”)功能。生产者将事件发布到 topic,而消费者则订阅 topic。当新事件被发布到某个 topic 时,订阅该 topic 的消费者就会接收到该新事件。
Kafka 通常与 ZooKeeper 一起部署,使用 ZooKeeper 存储集群的元数据。但是在最新的版本中(3.3及其之后的版本),Kafka 将逐渐摆脱对 ZooKeeper 的依赖。
下图展示的是一个完整的 Kafka 部署,包含了上述的各个组件:
监控目标
一个完整的 Kafka 服务的监控方案需要包括 Kafka 服务的监控、ZooKeeper 服务的监控以及服务运行环境(如服务运行所在的服务器节点)的监控,但本文的内容不会覆盖整个监控方案,而是专注于 Kafka 服务状态的监控。监控的范围包括:
-
Brokers 的实时状态
-
Topics/partitions 的实时状态以及历史数据
-
Consumer groups 的实时状态以及历史数据
解决方案
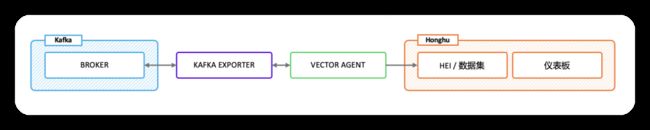
使用 Kafka exporter 收集 brokers, topics 以及 consumer groups 的相关指标,并通过 HTTP API 提供数据
使用 Vector agent 通过 Kafka exporter HTTP API 采集数据,并将数据通过 HEI 导入指定的数据集
使用仪表板展示 brokers, topics 以及 consumer groups 的状态信息
操作步骤
1、部署 Kafka exporter [操作步骤]
(https://github.com/danielqsj/kafka_exporter)
2、创建数据集 [操作步骤]
(https://www.yanhuangdata.com/honghu_manual/docs/data_management/eventset/#%E5%88%9B%E5%BB%BA%E6%95%B0%E6%8D%AE%E9%9B%86)
如使用已经存在的数据集,可跳过此步骤
3、创建 HEI endpoint [操作步骤]
(https://www.yanhuangdata.com/honghu_manual/docs/gdi/push_based/#%E6%96%B0%E5%BB%BAhei%E7%AB%AF%E5%8F%A3%E6%8E%A5%E6%94%B6%E6%95%B0%E6%8D%AE)
如使用已经存在的 HEI endpoint,可跳过此步骤
4、部署 Vector agent 导入数据 [操作步骤]
(https://vector.dev/docs/setup/quickstart/)
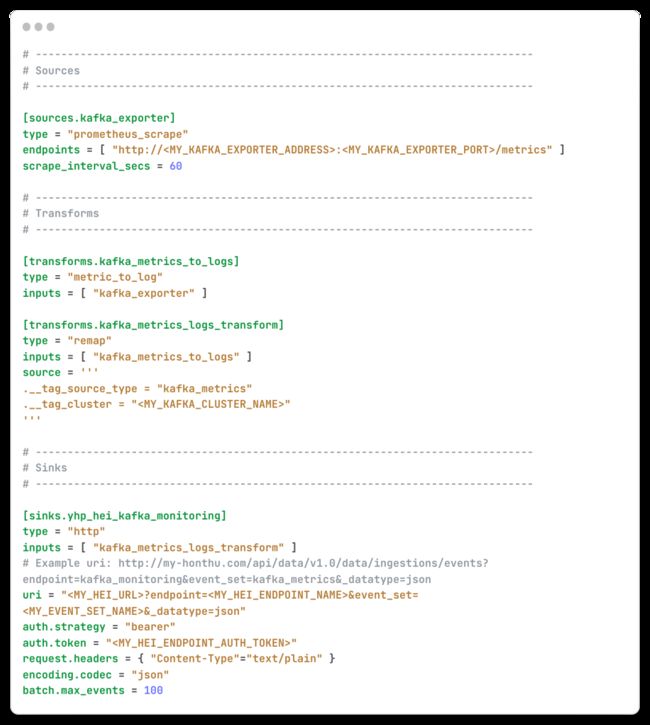
5、导入 Kafka 监控仪表板 [操作步骤]
(https://www.yanhuangdata.com/honghu_manual/docs/dashboard/#%E5%88%9B%E5%BB%BA%E4%BB%AA%E8%A1%A8%E6%9D%BF)
kafka_monitoring_overview.json
kafka_monitoring_topics.json
仪表板 Screenshot
Kafka 监控 / 概览

Kafka 监控 / Topics

后续工作
上述监控方案仅使用了 Kafka 服务中最关键的指标数据。为了实现更加完善的监控,后续还将引入更多的指标数据和日志数据,例如:
1、Kafka JVM 运行状态指标
2、Kafka 的错误日志