数据质量监控Griffin——使用
一、环境
生产环境
数据质量监控griffin:
地址:http://XXXXXXXXX:4200/#/health
账号:admin
密码:123456
二、Griffin是干什么的?
官方介绍
大数据模块是大数据平台中数据方案的一个功能组件,Griffin(以下简称Griffin)是一个开源的大数据数据解决质量模式,它支持所有数据和流数据方式检测质量模式,可以从不同维度(不同标准执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)收集数据资产,从而提高数据的准确度、可信度。
在格里芬的架构中,主要分为定义、测量和分析三个部分,如下图所示:
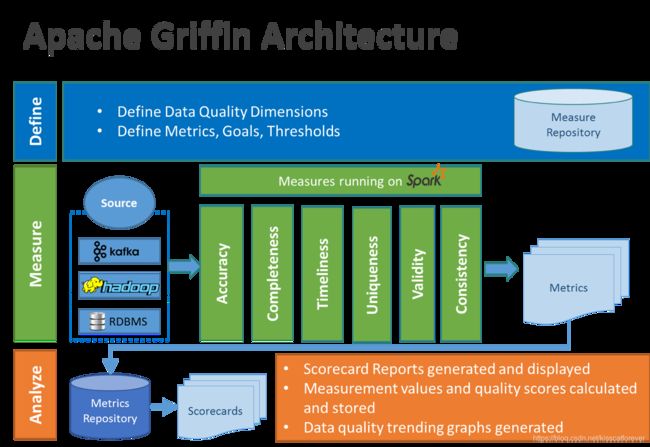
各部分的职责如下:
-
Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
-
Measure:主要负责执行统计任务,生成统计结果
-
Analyze:主要负责保存与展示统计结果
以上来自官方文档 ⬆️
Griffin起源于eBay中国,并于2016年12月进入Apache孵化器,Apache软件基金会2018年12月12日正式宣布Apache Griffin毕业成为Apache顶级项目。
Griffin是属于模型驱动的方案,基于目标数据集合或者源数据集(基准数据),用户可以选择不同的数据质量维度来执行目标数据质量的验证。支持两种类型的数据源:batch数据和streaming数据。
-
对于batch数据,我们可以通过数据连接器从Hadoop平台收集数据。
-
对于streaming数据,我们可以连接到诸如Kafka之类的消息系统来做近似实时数据分析。在拿到数据之后,模型引擎将在spark集群中计算数据质量。
数据质量指标说明
精确度:度量数据是否与指定的目标值匹配,如金额的校验,校验成功的记录与总记录数的比值。
完整性:度量数据是否缺失,包括记录数缺失、字段缺失,属性缺失。
及时性:度量数据达到指定目标的时效性。
唯一性:度量数据记录是否重复,属性是否重复;常见度量为hive表主键值是否重复。
有效性:度量数据是否符合约定的类型、格式和数据范围等规则。
一致性:度量数据是否符合业务逻辑,针对记录间的逻辑的校验,如:pv一定是大于uv的,订单金额加上各种优惠之后的价格一定是大于等于0的。
三、工作流程
-
注册数据,把想要检测数据质量的数据源注册到griffin。
-
配置度量模型,可以从数据质量维度来定义模型,如:精确度、完整性、及时性、唯一性等。
-
配置定时任务提交spark集群,定时检查数据。
-
在web界面上查看指标,分析数据质量校验结果。

四、batch方式使用方法
1.登录
health : 数据健康监控大屏
measure:数据质量标准制定
jobs:定时任务
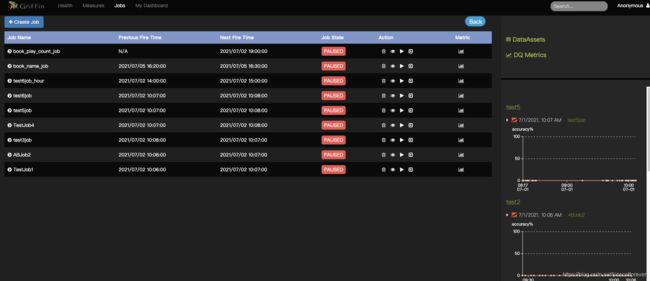
mydashboard:详细大屏

2.配置数据标准
在measure,点击Create Measure,创建数据质量模型。
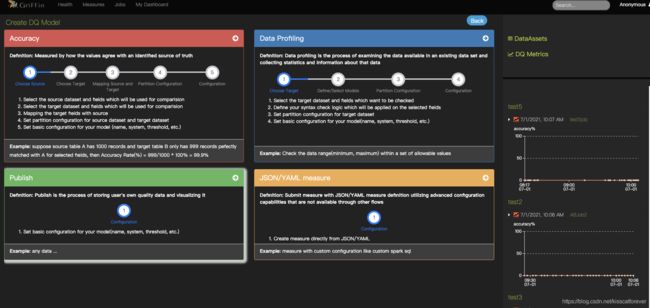
Accuracy:准确性模型
例子:假设源表 A 有 1000 条记录,目标表 B 只有 999 条记录与所选字段的 A 完全匹配,那么准确率(%) = 999/1000 * 100% = 99.9%
Data Profiling : 数据分析模型
例子 :检查一组允许值内的数据范围(最小值、最大值)
Publish:暂不开放
JSON/YAML measure:暂不开放
2.1 Accuracy 准确性模型配置
1.依次选择来源和目标字段


2.来源和目标字段映射:
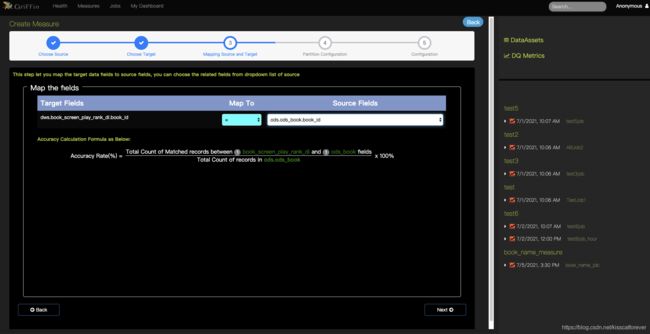
这里会根据这个模型公式计算准确度:

3.padition 配置:
选择数据分区、条件和是否输出结果文件。(无分区表可以跳过)

4.标准名字:

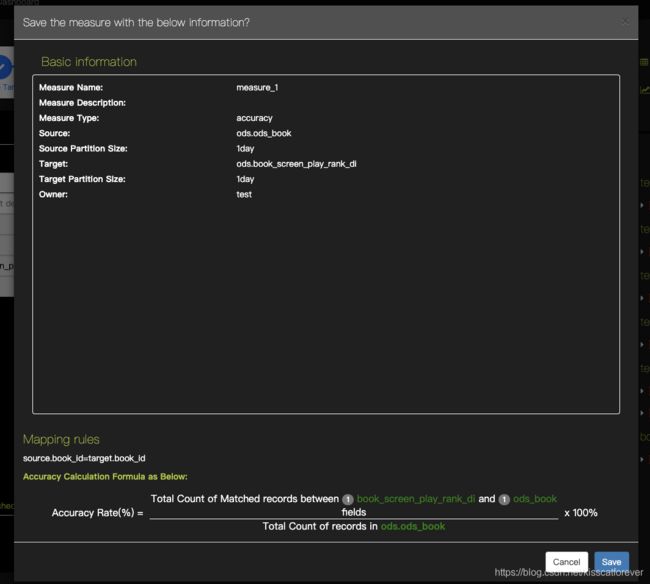

2.2 Data Profiling 数据类型校验模型
1.选择检测源头

2.选择检测类型

3.分区配置

4.编辑名字
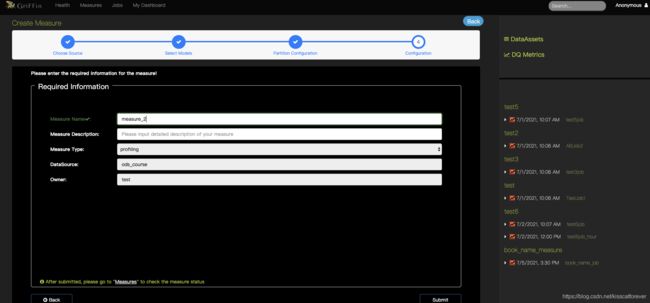
3.创建定时任务
模型创建好了,我们可以创建定时检测任务:
job–>create Job

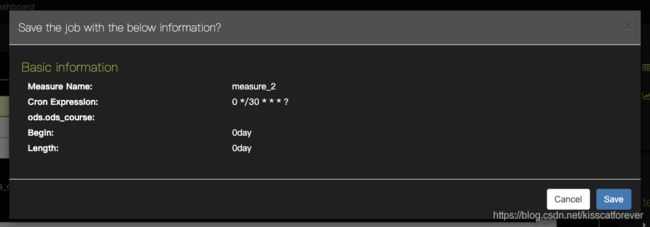
这里会用到cron表达式:
从下面链接生成即可
https://cron.qqe2.com/
0 */30 * * * ? 每三十分钟执行一次
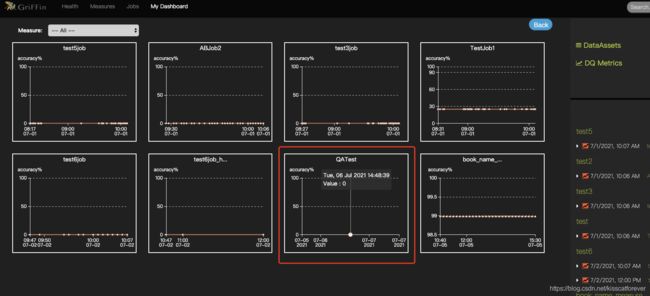
4.结果查看

五、Streaming使用方式
Streaming方式目前没有web可视化操作,需要手动配置脚本,手动提交spark任务来操作
env-streaming.json :
一般这个是核心配置文件,不需要修改。
{
"spark": {
"log.level": "WARN",
"checkpoint.dir": "hdfs://nameservice1/test/griffin/cp",
"batch.interval": "2s",
"process.interval": "10s",
"init.clear": true,
"config": {
"spark.master": "yarn",
"spark.task.maxFailures": 5,
"spark.streaming.kafkaMaxRatePerPartition": 1000,
"spark.streaming.concurrentJobs": 4,
"spark.yarn.maxAppAttempts": 5,
"spark.yarn.am.attemptFailuresValidityInterval": "1h",
"spark.yarn.max.executor.failures": 120,
"spark.yarn.executor.failuresValidityInterval": "1h",
"spark.hadoop.fs.hdfs.impl.disable.cache": true
}
},
"sinks": [
{
"name": "consoleSink",
"type": "CONSOLE",
"config": {
"max.log.lines": 100
}
},
{
"name": "hdfsSink",
"type": "HDFS",
"config": {
"path": "hdfs://nameservice1/griffin/streaming/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
},
{
"name": "elasticSink",
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://192.168.1.53:39200/griffin/accuracy"
}
}
],
"griffin.checkpoint": [
{
"type": "zk",
"config": {
"hosts": "172.16.70.161:2181",
"namespace": "griffin/infocache",
"lock.path": "lock",
"mode": "persist",
"init.clear": true,
"close.clear": false
}
}
]
}
dq.json :
这里配置了数据来源是kafka,配置了servers,topic等信息。
最后的sink要在env-streaming.json 文件中定义好。
{
"measure.type": "griffin",
"name": "streaming_accu",
"process.type": "STREAMING",
"data.sources": [
{
"name": "src",
"baseline": true,
"connector":
{
"name": "connector_name_source",
"type": "kafka",
"version": "0.8",
"config": {
"kafka.config": {
"bootstrap.servers": "192.168.1.178:9092,192.168.1.179:9092,192.168.1.180:9092",
"group.id": "griffin",
"auto.offset.reset": "largest",
"auto.commit.enable": "false"
},
"topics": "topic_sync_message",
"key.type": "java.lang.String",
"value.type": "java.lang.String"
},
"pre.proc": [
{
"dsl.type": "df-opr",
"rule": "from_json"
}
]
}
,
"checkpoint": {
"type": "json",
"file.path": "hdfs://nameservice1/griffin/streaming/dump/source",
"info.path": "source",
"ready.time.interval": "10s",
"ready.time.delay": "0",
"time.range": [
"-5m",
"0"
],
"updatable": true
}
},
{
"name": "tgt",
"connector":
{
"name": "connector_name_target",
"type": "kafka",
"version": "0.8",
"config": {
"kafka.config": {
"bootstrap.servers": "192.168.1.178:9092,192.168.1.179:9092,192.168.1.180:9092",
"group.id": "griffin",
"auto.offset.reset": "largest",
"auto.commit.enable": "false"
},
"topics": "topic_sync_message",
"key.type": "java.lang.String",
"value.type": "java.lang.String"
},
"pre.proc": [
{
"dsl.type": "df-opr",
"rule": "from_json"
}
]
}
,
"checkpoint": {
"type": "json",
"file.path": "hdfs://nameservice1/griffin/streaming/dump/target",
"info.path": "target",
"ready.time.interval": "10s",
"ready.time.delay": "0",
"time.range": [
"-1m",
"0"
]
}
}
],
"evaluate.rule": {
"rules": [
{
"dsl.type": "griffin-dsl",
"dq.type": "ACCURACY",
"out.dataframe.name": "accu",
"rule": "src.user_id = tgt.user_id",
"details": {
"source": "src",
"target": "tgt",
"miss": "miss_count",
"total": "total_count",
"matched": "matched_count"
},
"out": [
{
"type": "metric",
"name": "accu"
},
{
"type": "record",
"name": "missRecords"
}
]
}
]
},
"sinks": [
"consoleSink"
]
}
在spark中提交任务:
spark-submit --class org.apache.griffin.measure.Application --master yarn --deploy-mode client --queue default --driver-memory 1g --executor-memory 1g --num-executors 3 /opt/griffin/griffin-measure.jar /opt/griffin/env-streaming.json /opt/griffin/dq.json