用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
文章目录
- 一、前言
-
- 1.1 大赛介绍
- 1.2 项目背景
- 二、基于智能文字场景个人财务管理创新应用
-
- 2.1 作品方向
- 2.2 票据识别模型
-
- 2.2.1 文本卷积神经网络TextCNN
- 2.2.2 Bert 预训练+微调
- 2.2.3 模型对比
- 2.2.4 效果展示
- 2.3 票据文字识别接口
- 三、未来展望
一、前言
1.1 大赛介绍
中国大学生服务外包创新创业大赛作为服务外包产业领域唯一的国家级赛事,位列“全国普通高校学科竞赛排行榜评估体系”,自2010年以来已连续举办14届,分为区域赛和全国决赛两个阶段。本届大赛吸引了803所全国院校的8006支团队报名参赛,报名团队数再创新高。其中4097支团队通过审核进入初赛,216 支队伍进入全国总决赛。
本次竞赛内容紧密围绕企业发展中的现实问题,与产业结合度更紧密,特别是智能文字识别技术。这项技术融合了多种先进技术,如智能图像处理、光学字符识别、深度学习、自然语言处理等,能够在多场景下进行文字信息的识别和分析,具有广泛的应用价值。无论是在生产、教育还是生活中,智能文字识别技术都有着重要的作用,能够提高工作效率、降低成本、提升用户体验。
1.2 项目背景
记账是一项重要的生活习惯,可以帮助我们更好地了解自己的支出与收入,以便做出更明智的财务决策。然而,目前市面上大多数的记账 APP 需要手工录入才能完成记账,或者需要获取外卖、支付等应用程序的信息才能进行消费记录,存在功能不齐全、隐私过度收集等问题。尤其是对于中老年人来说,使用记账本应用十分吃力,因为他们对于这些新技术的使用并不熟练。针对这些问题,我们可以通过技术创新来提供更加便捷、高效的记账工具,让人们更好地管理自己的财务。
合合信息作为人工智能科技企业的代表,积极参与了赛题的拟定与赛道建设,设立了“基于智能文字场景个人财务管理创新应用”的相关议题,与众多高校学子共同探索技术创新与落地的多重可能,共同探讨如何通过技术手段解决老年人记账难题,以及如何优化已有软件产品以更好地满足现代人群的需求。
这场竞赛不仅是一次技术交流与创新的盛会,更是对社会问题的思考与解决的起点。青年学子们的参与不仅为解决记账难题和优化软件产品提供了新的思路和方向,也为推动科技进步与社会发展贡献了自己的力量。
二、基于智能文字场景个人财务管理创新应用
在基于智能文字场景个人财务管理创新应用这个项目中,“中国计量大学-去南京整薯条”队伍的作品深深吸引了我,下面我们就来看看作品情况。
2.1 作品方向
“中国计量大学-去南京整薯条”队伍作品实现了登录登出、数据存贮功能、消费信息录入、消费数据的展示与编辑、自动判断消费类型、多维度展示消费数据、支持消费凭据类型等等。这里我们主要介绍消费信息录入创新功能中最重要的技术:票据识别模型。

2.2 票据识别模型
“去南京整薯条”队伍在使用合合信息提供的商铺小票识别接口基础上, 使用提供的通用文字识别将票据上的信息全部提取出来,并用 TextCNN 模型和 Bert 预训练+微调分别对所有提取出来的词句进行分类,返回最有可能为商铺名的短语。
2.2.1 文本卷积神经网络TextCNN
文本卷积神经网络(TextCNN)是一种常用于文本分类自然语言处理任务的深度学习模型。优点在于它能够通过卷积操作捕捉文本中的局部特征,实现对不同长度的词组合的有效建模。同时,TextCNN具有参数共享和局部连接的特性,减少了模型的参数量和计算复杂度。它还能够通过多尺度感知提取文本的全局和局部信息,从而更好地理解文本的语义和结构。此外,TextCNN在处理大规模文本数据时具有高效性能,能够快速处理大量的文本信息。综上所述,“去南京整薯条”队伍选择 TextCNN 作为模型之一,来进行票据识别。
在本任务中,由于商铺名短语识别任务涉及的相关短语包含大量特定的词语,如果 使用通用的文字词向量库会导致分类性能下降。故在本任务中,将测试集中所有数据进行词向量映射,使该方式生成的词向量更加灵活,并且更加适用于商铺名的识别。
“去南京整薯条”队伍训练的 TextCNN 模型中,输入的词向量大小为 30*50;模型 采用 4 种不同的区域大小,其大小分别为 2、3、4、5。对于每一种区域大小,都使用了 2 个不同的卷积核,通过 Relu 函数进行激活,生成特征图。再通过 max-pooling,所有 特征图进行串联,从而形成一个单一的特征向量。经过全连接层,输出结果。TextCNN模型图如所示:
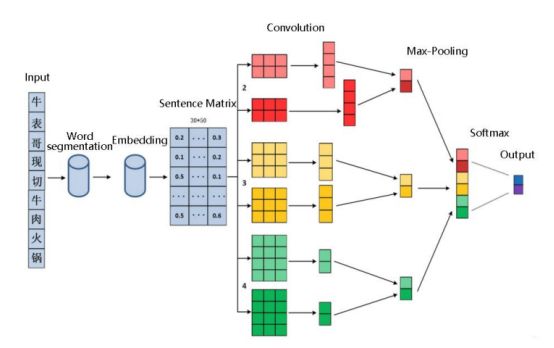
此模型局部特征提取能力强,文本分类表现优秀。
2.2.2 Bert 预训练+微调
Bert 是一种双向预训练语言模型,它可以用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。BERT的训练分为两个步骤:预训练和微调。在预训练阶段,BERT使用大量的无监督文本通过自监督训练的方式(通过使用受完形填空任务启发的Masked Language Model预训练目标)训练,把文本中包含的语言知识(包括:词法、语法、语义等特征)以参数的形式编码到Transformer-encoder layer中。在微调阶段,BERT使用少量的有标签数据进行微调,以适应特定任务。
“去南京整薯条”队伍使用 Hugging Face 自然语言处理(NLP)社区提供的“Transformers” 库中的“bert-base-chinese”模型作为预训练模型,并使用其配套的分词器来进行文本序列的特征提取。 使用了一个简单的线性层和全连接层来构建下游任务模型进行微调训练。Bert预训练模型+微调模式图如下:
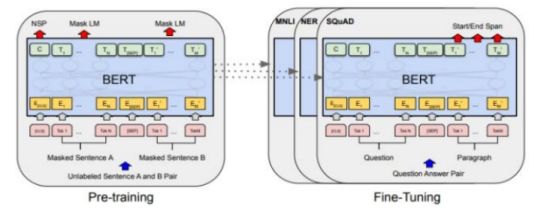
此模型兼顾序列中所有位置的信息,可以更好理解语义信息。
2.2.3 模型对比
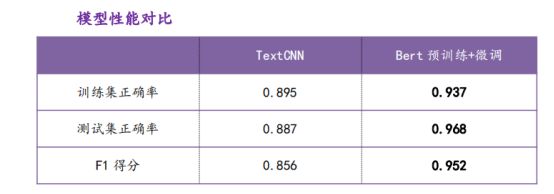
由表可知,Bert 预训练+微调的模式在训练集/测试集正确率和F1得分均明显超过 TextCNN,所以其团队在本项目中选用 Bert 预训练+微调模型。
2.2.4 效果展示
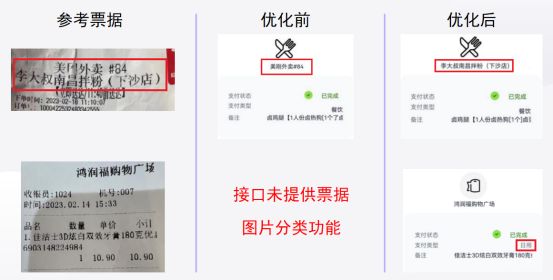
可以看到最终实现的效果,“去南京整薯条”队伍通过合合信息提供的通用文字识别接口与大模型的结合成功优化了票据信息识别和自动分类问题:
2.3 票据文字识别接口
传统OCR识别采用统计模式,处理流程较长,典型的传统OCR识别流程如图所示:
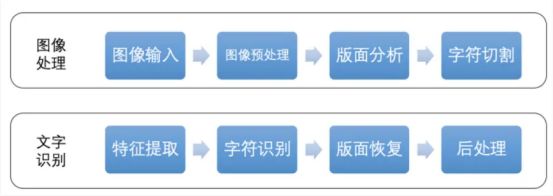
传统OCR识别方法存在诸多弊端:
1、对于图像质量差、模糊、亮度不均匀、反光、倾斜等各种问题识别效果很差。
2、对于自然场景下拍摄的复杂样本基本无法处理,没有修改提升空间,可用性不高。
针对以上问题,合合信息打造了一款智能文字识别训练平台。对于较大难度的证件类和票据类性能测试为例,面对旋转、阴影、反光、褶皱、形变、模糊、多语言、低像素、光照不均等复杂场景,合合信息智能文字识别产品均有较高的识别准确率,字符准确率分别为99.21%和99.59%,字段准确率分别为97.87%和98.42%。
通过融合不同行业和场景,支持增值税发票、火车票、出租车票、飞机行程单等多种国内外常见票据高精准度识别,提供便捷的票据处理服务。
并且在中国信息通信研究院(以下简称“中国信通院”)“可信ai—ocr智能化服务”评估工作,并获得“增强级”评级:
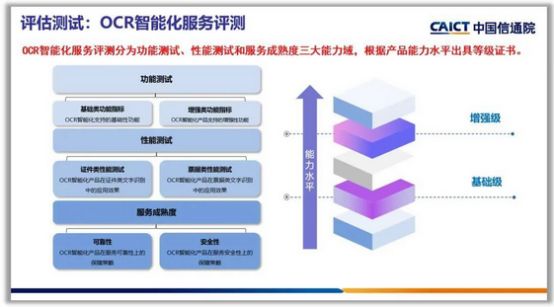
合合信息在自然语言处理、图像识别等领域拥有领先的技术和产品,对于研发大模型得天独厚的条件,期待合合信息在未来能够为用户和行业带来更多的惊喜和创新!
三、未来展望
本次合合信息提出的“基于智能文字场景个人财务管理创新应用”赛题,让学生在真实的业务场景中获得实践经验,消除人才发展目标与市场需求之间的信息不对称,促进校企双方在科研项目和人才培养等方面的深度合作,推动产学研用协同创新发展。
合合信息人力资源部负责人杜杰在大赛闭幕式上表示,未来是人工智能的时代,合合信息希望通过AI“星火计划”等系列人才培养计划和配套分享平台,致力于帮助科技青年在实践中提升专业能力。未来,将继续与高校和行业机构合作,共同探索产学研融合之路,为大学生提供更便捷的创新科技灵感落地渠道,从而实现科技创新和社会进步的双赢。