postgresql高可用及postgis安装
postgresql高可用及postgis安装
- postgresql 高可用
-
-
- 进程
- 流式复制
-
- 流复制原理
- 流复制实现
- master 节点配置
- slave 节点配置
- 查看同步状态
- 在主库查看状态
-
- postgis
-
-
- docker安装postgis
-
postgresql 高可用
进程
 - Postmaster 主进程
- Postmaster 主进程
- 它是整个数据库实例的主控制进程,负责启动和关闭该数据库实例
- 实际上,使用pg ctl来启动数据库时,pg_ctl也是通过运行postgres来启动数据库的,只是它做了一些包装,更容易启动数据库
- 它是第一个PostgreSQL进程,此主进程还会fork出其他子进程,并管理它们
BgWriter 后台写进程
- 为了提高插入、删除和更新数据的性能,当往数据库中插入或者更新数据时,并不会马上把数据持久化到数据文件中,而是先写入Buffer中
WalWriter 预写式日志进程
- 预写式日志是在修改数据之前,必须把这些修改操作记录到磁盘中,这样后面更新实际数据时,就不需要实时的把数据持久化到文件中了。即使机器突然宕机或者数据库异常退出, 导致一部分内存中的脏数据没有及时的刷新到文件中,在数据库重启后,通过读取WAL日志,并把最后一部分WAL日志重新执行一遍,就能恢复到宕机时的状态了
- WAL日志保存在pg_wal目录(早期版本为pg_xlog) 下。每个xlog 文件默认是16MB,为了满足恢复要求,在pg_wal目录下会产生多个WAL日志,这样就可保证在宕机后,未持久化的数据都可以通过WAL日志来恢复,那些不需要的WAL日志将会被自动覆盖
Checkpointer 检查点进程
- 检查点(Checkpoints)是事务序列中的点,保证在该点之前的所有日志信息都更新到数据文件中。在检查点时,所有脏数据页都冲刷到磁盘并且向日志文件中写入一条特殊的检查点记录。在发生崩溃的时候,恢复器就知道应该从日志中的哪个点(称做 redo 记录)开始做 REDO 操作,因为在该记录前的对数据文件的任何修改都已经在磁盘上了。在完成检查点处理之后,任何在redo记录之前写的日志段都不再需要,因此可以循环使用或者删除。在进行 WAL 归档的时候,这些日志在循环利用或者删除之前应该必须先归档保存
- 检查点进程 (CKPT) 在特定时间自动执行一个检查点,通过向数据库写入进程 (BgWriter) 传递消息来启动检查点请求
AutoVacuum 自动清理进程
* 执行delete操作时,旧的数据并不会立即被删除,在更新数据时,也不会在旧的数据上做更新,而是新生成一行数据。旧的数据只是被标识为删除状态,在没有并发的其他事务读到这些旧数据时,它们才会被清除掉
PgArch 归档进程
- 默认没有此进程,开启归档功能后才会启动archiver进程WAL日志文件会被循环使用,也就是说WAL日志会被覆盖,利用PgArch进程会在覆盖前把WAL日志备份出来,类似于binlog,可用于备份功能
- PostgreSQL 从8.X版本开始提供了PITR ( Point-In-Time-Recovery)技术,即就是在对数据厍进行过一次全量备份后,该技术将备份时间点后面的WAL日志通过归档进行备份,将来可以使用数据库的全量备份再加上后面产生的WAL 日志,即可把数据库向前恢复到全量备份后的任意一个时间点的状态
startup 启动进程
- 用于数据库恢复的进程
流式复制
流复制 streaming replication 是实现PostgreSQL的高可用的常见技术.PostgreSQL流复制相当于MySQL的主从复制,可以实现数据同步和数据备份
PostgreSQL通过 WAL 日志来传送的方式有两种:基于文件的日志传送和流复制。不同于基于文件的日志传送,流复制的关键在于“流”,所谓流就是没有界限的一串数据,类似于河里的水流,是连成一片的。
流复制出现是从2010年推出的PostgreSQL9.0开始的
流复制原理
备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record
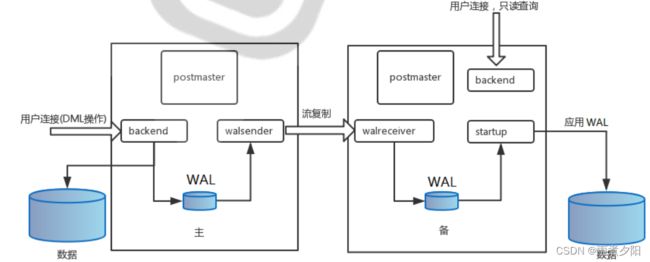
流复制实现
环境准备
192.168.144.60 Master
192.168.144.40 slave
master 节点配置
#创建复制的用户并授权
[postgres@master ~]$ psql
postgres=#create role repluser with replication login password 'qazxsw';
#修改pg_hba.conf进行授权
[postgres@master ~]$vim /usr/local/pgsql/data/pg_hba.conf
host replication repluser 0.0.0.0/0 md5
#修改配置(可选):
[postgres@master ~]$vim /usr/local/pgsql/data/postgresql.conf
synchronous_standby_names = '*' #开启此项,表示同步方式,需要同时打开synchronous_commit = on,此为默认值,默认是异步方式
synchronous_commit = on #开启同步模式
archive_mode = on #建议打开归档模式,防止长时间无法同步,WAL被覆盖造成数据丢失
archive_command = '[ ! -f /archive/%f ] && cp %p /archive/%f'
wa1_level = replica #设置wal的级别
max_wal_senders = 5 #这个设置可以最多有几个流复制连接,一般有几个从节点就设置几个
wal_keep_segments = 128 #设置流复制保留的最多的WAL文件数目
wal_sender_timeout = 60s #设置流复制主机发送数据的超时时间
max_connections = 200 # 一般查多于写的应用从库的最大连接数要比较大
hot_standby = on #对主库无影响,用于将来可能会成为从库,这台机器不仅仅是用于数据归档,也用于数
据查询,在从库上配置此项后为只读
max_standby_streaming_delay = 30s #数据流备份的最大延迟时间
wal_receiver_status_interval = 10s #多久向主报告一次从的状态,当然从每次数据复制都会向主报
告状态,只是设置最长的间隔时间
hot_standby_feedback = on #如果有错误的数据复制,是否向主进行反馈
wal_log_hints = on #对非关键更新进行整页写入
[postgres@master ~]$pg_ctl restart -D $PG_DATA
slave 节点配置
[postgres@slave ~]$ pg_ctl stop -D $PGDATA
//删除从节点数据目录
[postgres@slave ~]$ rm -rf /usr/local/pgsql/data/*
//备份主库数据到备库
[postgres@slave ~]$ pg_basebackup -D /usr/local/pgsql/ -Ft -Pv -Urepluser -h 192.168.144.60 -p 5432 -R
//还原备份的数据,实现初始的主从数据同步
[postgres@slave ~]$ tar xf /usr/local/pgsql/base.tar -C /usr/local/pgsql/data/
//修改postgresql.conf文件
[postgres@slave ~]$ vi /usr/local/pgsql/data/postgresql.conf
#添加下面代码
primary_conninfo = 'host=192.168.144.60 port=5432 user=repluser password=qazxsw'
// 启动从节点
[postgres@slave ~]$ pg_ctl -D /usr/local/pgsql/data start
查看同步状态
[postgres@localhost ~]$ pg_controldata


在主库查看状态
postgres=# select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication;
pid | state | client_addr | sync_priority | sync_state
-------+-----------+----------------+---------------+------------
52560 | streaming | 192.168.144.40 | 0 | async
(1 row)
#服务器查看数据库是否为备库,f表主库 t表示为备库
postgres=# select * from pg_is_in_recovery();
-[ RECORD 1 ]-----+--
pg_is_in_recovery | f
查看流复制进程
[postgres@localhost ~]$ ps aux |grep walsender
postgres 52560 0.0 0.1 273576 2352 ? Ss 14:02 0:00 postgres: walsender repluser 192.168.144.40(40306) streaming 0/3000E40
postgres 52680 0.0 0.0 112824 988 pts/1 R+ 14:09 0:00 grep --color=auto walsender
postgis
PostGIS是流行的PostgreSQL对象关系数据库的空间数据库扩展。PostGIS“在空间上的”PostgreSQL服务器,允许它作为地理信息系统(GIS)和网络地图应用程序的后端空间数据库,与Microsoft的SQL server spatial和Oracle的spatial数据库扩展相同。
PostGIS是一个开源项目,PostGIS源代码根据GNU通用公共许可证(GPL)发布。
docker安装postgis
postgis安装。需要一堆的插件,且这些插件有版本依赖,在安装编译时很不方便,所以在这里推荐使用docker 进行安装。避免了繁杂的依赖编译过程。
如果需要用源码安装的可以到管网下载对应的插件进行手动编译安装,这里不做过多演示
插件下载地址:https://trac.osgeo.org/postgis/wiki/UsersWikiPostgreSQLPostGIS
我们这里可以去postgis官方指定的docker hub仓库下载docker镜像进行安装
仓库地址:https://registry.hub.docker.com/r/postgis/postgis
下载需要的版本:
我这里下载postgersql-14对应的版本

服务器拉取镜像
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/postgis/postgis latest c05523e87855 4 days ago 589 MB
//启动容器
[root@localhost ~]# docker run --name postgis -p 5432:5432 -e POSTGRES_PASSWORD=qazxsw -d docker.io/postgis/postgis
972093e32e9b2c35dd39c7fb13e36e7227a9327a074a3572ba8e0dc9f3d4ee18
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
972093e32e9b docker.io/postgis/postgis "docker-entrypoint..." 34 seconds ago Up 32 seconds 0.0.0.0:5432->5432/tcp postgis
//进入sql命令行
[root@localhost _data]# docker exec -ti 972093e32e9b psql -U postgres
psql (15.1 (Debian 15.1-1.pgdg110+1))
Type "help" for help.
postgres=#
通过客户端链接测试是否可以链接