MySql数据库
MySql架构
1.连接层: 负责接收客户端的连接请求,可以进行认证(验证账号密码)
2.服务层:接收sql,语言解析,优化,缓存
3.引擎层:引擎层是真正落地实施的具体方式,不同的存储引擎特点不同。
4.物理文件存储层:使用各种文件用来储存数据,以及各种的日志文件。
储存引擎
存储引擎是具体的操作数据的方式。
Innodb:支持事务,支持行级锁(一个事务对某行数据操作时,只会锁定某一行数据,不锁定其他行,效率高),支持外键约束,支持缓存,支持全文索引,不会存储表中的总行数。
MyISAM:不支持事务,不支持主外键,不支持行级锁,支持表锁(进行DML操作时会锁定整张表),主要用于查询多,增删改较少的场景。支持全文索引,存储表的总行数。
索引
索引是类似于书的目录,可以通过目录(索引)快速的定位数据真实的位置。是排好序的,快速查找的数据结构。(B+树)
在数据库中单独维护一个树,树中的每个节点存储主键和数据的物理地址,可以通过树形结构,快速锁定到数据的位置。
优势:快速的定位数据位置,减少IO次数,降低了排序成本。
劣势:维护索引需要占用存储空间。增删改查操作时,还需要维护索引树,需要消耗时间。
索引分类
主键索引: ALTER TABLE 表名 add PRIMARY KEY 表名(列名);
删除主键: ALTER TABLE 表名 drop PRIMARY KEY ;
单值索引:CREATE INDEX news_title_index ON news(title)
删除索引: DROP INDEX 索引名 ON 表名;
唯一索引: 保证列数据不重复,可以为null
CREATE UNIQUE INDEX 索引名 ON 表名(列名);
组合索引: 一个索引对应多个列,就是多个列组成一个索引
注意,要满足,最左前缀原则 A,B,C三列
A,B建立组合索引,满足最左 前缀原则, 必须要出现最左边的列
A and B 生效
B and A 生效
A and A 生效
B and C 不生效
全文索引:模糊查询 like,会导致索引失效
EXPLAIN关键字添加在SQL语句的前面可以查看SQL语句的执行效率。
建立索引的原则
那些情况需要创建索引:
1.主键自动建立唯一索引
2.频繁作为查询条件的字段应该创建索引(where后面的语句)
3.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
4.查询中与其它表关联的字段,外键关系建立索引
5.分组中的字段
那些情况不要创建索引:
1.表记录太少
2.经常增删改查的表:提高查询速度,同时却会降低更新表的速度,如果对表进行插入,
修改,删除,因为更新表时,MySql不仅要保存数据,还要保存索引文件。
3.Where条件里用不到的字段,因此应该只为最经常查询和最经常排序的数据列建立索引,
某个数据列包含许多重复的内容,建立索引没有太大的实际效果。例如性别: 男 女
索引结构:
Data Structure Visualization
索引是一个树形结构:B+树,首先二叉树被排除掉(自平衡)被排除了,树的高度比较高,会影响查询效率。B树自平衡多路树,在一个节点中放多个数据,横向扩展,降低树的高度。
B+树 自平衡多路树 排好序:非叶子节点只存储索引,数据都存储在叶子节点。会存在一些数据冗余。

叶子节点之间会有一个相互指向的指针(对于自增主键,范围查找是非常合适的)
聚簇索引和非聚簇索引
聚簇索引,找到了索引,就找到了数据,例如主键索引,innodb引擎下,数据都在叶子节点存储,通过主键查找,找到了主键,也就找到了数据(属于聚簇式)。
SELECT id FROM news WHERE id = 3
非聚簇索引: 索引和数据是分离的,找到了索引,还没有找到数据,需要根据主键,再次回表查询,才能够查询到数据
通过学号(不是主键)查询学号和姓名, 先通过学号找到主键,再次通过主键去查找数据,这种场景是非聚簇的。 还有myisam引擎中,除了只查询主键列以外,查询其他列的都是非聚簇索引。
判断是聚簇索引还是非聚簇索引: 这次查询中,能够直接命中数据。
聚簇索引: 找到了索引,就找到了数据---聚簇索引
Innodb下: 使用主键作为查询条件,就是聚簇索引
使用非主键(title)的列添加索引查询, 就是非聚簇的,因为需要通过索引找到主键,然后通过主键二次回表查询,再通过主键找到数据
myIsam: 索引文件与数据文件是分开存放的,所以是非聚簇的。
事务
事务是数据为了保证数据操作的原子性,隔离性,持久性,一致性,为数据库提供的一套机制,在同一事务中,如果有多条sql执行,事务可以确保执行的可靠性。
事务满足ACID特性:
1.原子性:一个事务中有多条sql时,要么都执行,要么都不执行。
2.持久性:一旦事务提交,数据就持久保存在硬盘上。
3.隔离性:有好多个事务同时对数据进行操作,需要不同的隔离机制。来进行控制,防止数据不完整。
4.一致性:数据经过很多次的操作,最终的结果要与预期的结果一致,保证数据的完整性,原子性,持久性,隔离性都是为了保证数据的一致性。
事务的隔离级别:
有四种隔离级别:
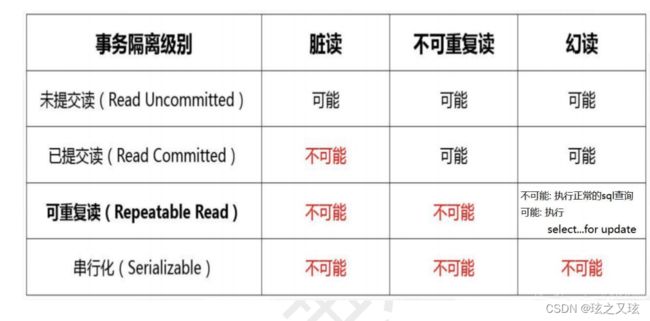
1.读未提交: B事务读到了A事务未提交的数据
产生问题:产生脏读(读到别的事务没有提交的数据,是垃圾数据,因为A事务可能会回滚), 不可重复读(两次读的过程中有其他事务对数据进行修改,导致两次读到的不同结果),幻读(主要指的是在事务中读取到了新增的数据行或者删除的数据行,导致读取结果不一致)。
解决办法:设置隔离级别为读已提交
2.读已提交:B事务读到了A事务已经提交的事务,解决了脏读的问题,产生问题不可重复读,幻读。
3.可重复读:B事务在开启后的两次查询中,两次查询的结果是相同的,解决了不可重复读,脏读。SELECT ... FOR UPDATE 是一种在数据库事务中使用的语句,目的是在读取数据时对相应的行进行锁定,以避免并发冲突,会产生幻读。
4.串行化(SERIALIZABLE):加锁,只要有一个事务进行操作,其他的事务就得等待,即使是读操作也会锁定,是最安全的,速度是最慢的。可以解决上述所有问题,MySql中默认的隔离级别为可重复读。
事物实现原理:
原子性: 原子性实现 依赖的是undo log(回滚日志),保存每次操作的反向操作. 如我们执行insert操作, 那么日志中保存delete操作。当回滚时执行反向操作。
持久性: 每次当执行修改数据操作时,先会将语句保存到redo log(重做日志)中.即使突然断电, 正常后也可以从日志中恢复数据。
隔离性(MVCC):多版本并发控制 Multi-Version Concurrent Control ,主要是针对读已提交和可重复读。
读已提交: 只要别的事务提交了,那么另一个事务就可以看到。
特点: 有可能同一个事务两次查询数据不一致,时时访问到的是最新的数据.。 当前读,每次读时,都会给版本链拍照,所以读到的数据是最新的(已提交)。
可重复读:B事务开始后,第一次读到的数据和之后读到的数据一致,这个过程中别的事务已经修改过了。也叫快照读,第一次读的时候,会把版本链拍照,下次读时,从版本快照中读,所有第一次和第二次读到数据是一致的。
使用隔离级别机制,为了实现并发的读-写,写-读操作,提高效率。
锁
Mysql支持行锁,间隙锁,表锁
行锁: 只给操作的行加锁,如果两个事物操作的是同一行,那必须一个一个执行.
间隙锁: 一般指的是范围区间, 对某一个区间进行加锁 例如ID>5 and id <10
表锁: 对整个表加锁,myisam默认是支持表锁.
共享锁: 又称为读锁, 如果我们事物在读数据时,不想让其他事物写,还要让其他事物可以读, 那么查询语句可以加共享锁 select … lock in share mode.
排它锁: 就是独占锁., 写操作默认加排他锁, 当我们读数据时,要求数据足够准确,可以给读操作加排他锁,select …for update