很干的 Nginx
前言
本篇文章有些概念性的东西,是结合自己的理解表达出来的,可能有些理解不到位的地方。希望多多指教,谢谢大家。
红包献上
最小单元配置
worker_processes 1; # 工作的进程个数
events {
worker_connections 1024; # 一个进程可以创建多少个链接(默认 1024)
}
http {
# 引入其他配置(返回前端的头部信息,告诉浏览器返回的数据格式)
include mime.types;
# 如果没有命中 mime.types 的类型,则默认返回 application/octet-stream 的数据格式
default_type application/octet-stream;
# 数据零拷贝 (减少了 nginx 读取文件,拷贝文件,直接将文件返回给到前端)
sendfile on;
# 保存连接超时时间
keepalive_timeout 65;
# 虚拟主机
server {
# 监听端口
listen 80;
# 域名、主机名
server_name localhost;
location / { # / 转发
# 指向 nginx 目录下的 html 目录
root html;
# 默认展示页
index index.html index.htm
}
# 错误码为 500 502 503 504 会命中 50x.html
error_page 500 502 503 504 /50x.html
# 访问 /50x.html 会被代理到 nginx 下的 html 目录下
location = /50x.html {
root html
}
}
}
二级域名转发
根据不同的二级域名返回不同的站点
如:
- 域名 blog.hhmax.xyz 返回博客站点
- 域名 www.hhmax.xyz 返回主站站点
原理:将不同的二级域名都指向同一个 IP 地址,在通过 Nginx 在转发时,根据不同的二级域名,返回不同的站点
下面通过俩种方式进行演示:
内网模拟站点映射
在 C:\Windows\System32\drivers\etc\hosts 文件中添加
39.104.61.35 blog.hhmax.xyz
39.104.61.35 www.hhmax.xyz
测试是否映射成功
ping blog.hhmax.xyz
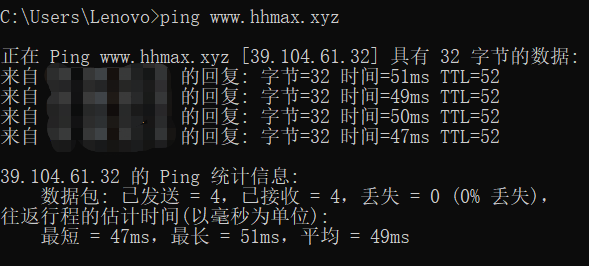
ping www.hhmax.xyz
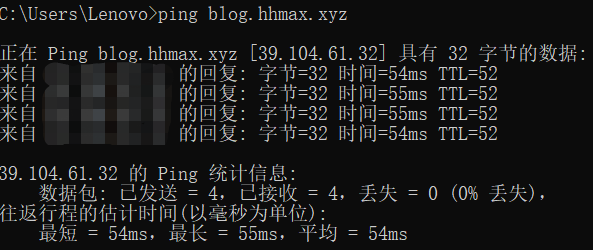
接下来进行 Nginx 配置,配置内容如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name www.hhmax.xyz;
location / {
root html; # 转发到 nginx/html/index.html 或 index.htm
index index.html index.htm
}
},
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
root blog; # 转发到 nginx/blog/index.html 或 index.htm
index index.html index.htm
}
}
}
外网模拟站点映射
需要购买域名以及一台服务器,并且服务器要备案成功才能映射成功

选中域名解析,并添加记录

需要设置的字段
- 记录类型:这里选择 A - 将域名指向一个 IPV4 的地址
- 主机记录:可以填写一个二级域名(即我们要设置的 blog 和 www)
- 记录值:映射的地址(即我们要映射的服务器IP地址)
可添加多条记录,并映射到其他 IP 或相同 IP
接下来进行 Nginx 配置,配置内容如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name www.hhmax.xyz;
location / {
root html; # 转发到 nginx/html/index.html 或 index.htm
index index.html index.htm
}
},
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
root blog; # 转发到 nginx/blog/index.html 或 index.htm
index index.html index.htm
}
}
}
注意:上述 Nginx 配置监听的端口是 80 端口,服务器可能需要开启

反向代理
正向代理
概念:代理服务器充当客户端的中间人,代表客户端向目标服务器发送请求。在正向代理中,客户端通过代理服务器来访问互联网上的资源,而不是直接与目标服务器通信。

好处:隐藏客户端的真实 IP 地址和身份,增加了匿名性和安全性
反向代理
概念:代理服务器接收客户端请求,并将请求转发给后端服务器。在反向代理中,客户端不直接与后端服务器通信,而是与代理服务器进行通信。

好处:
- 可以实现负载均衡,将请求分发到多个后端服务器,提高系统的性能和可靠性(负载均衡)
- 可以缓存静态资源,减少后端服务器的负载(动静分离)
Nginx 与 Tomcat 形成内网,Tomcat 不能直接绕过 Nginx 通过网关,发送消息。必须通过 Nginx 来发送消息。这种模式称为 隧道式代理
由此,也暴露出一个问题,当数据量很大时,尽管 Tomcat 的带宽有 100M,但 Nginx 的带宽只有 10 M。由于需要借助 Nginx 来向外传递数据,最终的传输数据没有设想的那么好。Tomcat 带宽再好,也要受限于 Nginx。
为了解决上述的缺点:
衍生出一种模式: Nginx 只处理进来的请求,而出去的数据不经过 Nginx 进行转发。Tomcat 直接将数据通过网关发送给到用户(中间会经过其他网关进行转发)。这种模式称为 DR 模式
反向代理配置
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
# 当访问 blog.hhmax.xyz 是代理到 http://www.baidu.com
proxy_pass http://www.baidu.com
}
location /api { # 笔记
# 当访问 blog.hhmax.xyz/api 是代理到 内网中的 http://127.0.0.1:3200
proxy_pass http://127.0.0.1:3200;
}
}
}
注意:上述例子中代理到后端服务 3200 端口也需要开放

负载均衡
概念:用于在多个服务器之间分配和平衡工作负载,以提高系统的性能、可靠性和可扩展性。当一个服务器无法处理所有的请求时,负载均衡将请求分发给其他可用的服务器,以确保每个服务器都能够处理适当的负载。
普通轮询
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 轮询的服务器
upstream httpds {
server 192.168.5.51:80;
server 192.168.6.51:80;
server 192.168.7.51:80;
}
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
proxy_pass http://httpds;
}
}
}
192.168.5.51:80、192.168.6.51:80、192.168.7.51:80 三台服务器提供的服务都一样。
权重轮询
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 权重值越大,被轮询到的可能性越大
upstream httpds {
server 192.168.5.51:80 weight=8;
server 192.168.5.51:80 weight=1;
server 192.168.5.51:80 weight=7;
}
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
proxy_pass http://httpds;
}
}
}
另外一些配置
- down (若配置,则该台服务器不参与轮询)
- backup(若配置,则该台服务器为备用机,当其他轮询服务器不能使用时,才会使用该服务器)
具体使用如下:
http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; upstream httpds { server 192.168.5.51:80 weight=8 down; server 192.168.5.51:80 weight=1; server 192.168.5.51:80 weight=7 backup; } server { listen: 80, server_name blog.hhmax.xyz; location / { proxy_pass http://httpds; } } }
轮询缺点
由于是轮询,所以导致没法保存会话信息,如在 192.168.5.51:80 用户登录成功。当用户再次访问该站点时,被 Nginx 轮询到192.168.7.51:80 ,此时这台服务器是不知道用户已经登录了,所以需要重新在登录。
解决方案
随着技术的发展,为了解决轮询带来的会话信息无法保存,衍生出了两种方案来解决上述问题
- 其一:借助 cookie、session、redis
流程:
- 用户输入其登录信息
- 服务器验证信息是否正确,并创建一个 session,并将其存入到 redis
- 服务器为用户生成一个 sessionId,将具有 sesssionId 的 cookie 将放置在用户浏览器中
- 在后续请求中,携带 cookie,访问服务器。哪怕是轮询到其他服务器,也可以通过 sessionId 去 redis 拿去登录信息
- 一旦用户注销应用程序,会话将在客户端和服务器端都被销毁
Node + Koa2 代码实现
// app.js
const app = new Koa()
const Koa = require('koa')
const redisStore = require('koa-redis')
const session = require('koa-generic-session')
//session 与 redis
app.keys = ['dfhQWE_123#ewr']
app.use(session({
key: 'token.sid', //cookie name 默认是 `koa.sid`
prefix: 'token:sess:', // redis key 的前缀,默认是 `koa:sess:`
//配置cookie
cookie:{
path:"/",
httpOnly:true,
maxAge:24 * 60 * 60 * 1000 // 1 day
},
//配置redis
store: redisStore({
all:`127.0.0.1:6379`
})
}))
// router
router.post('/login', async (ctx, next) => {
const { account = '-', password = '-' } = ctx.request.body;
if (config.account == account && config.password == password) {
// TODO 将账号信息(id)保存到 session 中
ctx.session.user = {
account: config.account
}
ctx.body = {
errorno: 0,
message: '登录成功'
}
return
}
ctx.body = {
errorno: 4001,
message: '账号或密码错误'
}
});
// 中间件校验 loginCheck
module.exports = async (ctx, next) => {
// // TODO:判断用户是否已经登录
if (ctx.session.user) {
await next()
return
} else {
ctx.body = {
errorno: 4000,
message: '用户未登录'
}
}
}
// 判断是否已经登录成功
router.post('/getNotes', loginCheck, async (ctx, next) => {
const data = await searchData();
ctx.body = {
errorno: 0,
message: '',
data
}
});
- 其二:无状态的会话通信 (JWT)
流程:
- 用户输入其登录信息
- 服务器验证信息是否正确,并返回已签名的 Token
- Token 存储在客户端
- 之后的 HTTP 请求都将 Token 添加到请求头里
- 服务器解码 JWT,并且如果令牌有效,则接受请求
- 一旦用户注销,令牌将在客户端被销毁,不需要与服务器进行交互一个关键是,令牌是无状态的。后端服务器不需要保存令牌或当前session的记录
Node + Koa2 代码实现
// app.js
const app = new Koa()
const Koa = require('koa')
const jwtKoa = require('koa-jwt')
app.use(jwtKoa(
{
secret:'1Hrj$_enferk' //密钥
}
).unless({
path:[/^\/users\/login/] //自定义哪些目录忽略 JWT 验证
}))
//登录成功对信息进行加密
const jwt = require('jsonwebtoken')
token = jwt.sign(userInfo, '1Hrj$_enferk', { expiresIn: '1h' })
// router
const until = require('util')
const verify = until.promisify(jwt.verify)
router.get('/getUserInfo', async (ctx, next) => {
const token = ctx.header.authorization
try {
const payload = await verify(token.split(' ')[1], '1Hrj$_enferk')
ctx.body = {
errno:0,
userInfo: payload
}
} catch (ex) {
ctx.body = {
errno:-1,
msg:'失败'
}
}
})
方案对比
共同点:为了解决:登录和存储登录用户信息
不同点:
- JWT 用户信息加密存储在客户端,不依赖 cookie ,可跨域。
- session 用户信息存储在服务端,依赖于 cookie,默认不可跨域
JWT 的优点:
- 将加密信息存放在客户端,减少服务端的内存压力。
- 不依赖于 cookie 可以将信息进行跨域分享。
JWT 的不足:
- 服务端无法控制信息,一旦用户修改信息后,服务端无法第一时间修改加密信息。
Session 的优点:
- 可以对用户信息进行控制。
Session 的不足:
- 存储要依赖于 redis 和 cookie ,并且不能跨域。
- 一旦上线启动多进程,而不依赖 redis 是无法实现多进程之间的信息共享。
动静分离
在还没有前后端分离的开发模式的情况下(MVC),一些静态资源都是集中和后端代码放在 Tomcat 。而这些静态资源大多数情况下都是不变的,如:图片,JavaScript 代码。
并且 Nginx 可以缓存静态资源,减少后端服务器的负载。因此,可以将一些静态资源放到 Nginx 中,从而使一些静态资源与业务逻辑进行抽离。
具体配置如下:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location / {
proxy_pass http://192.168.6.52
}
location ~*/(css|img|js) {
# 路径中有 /css /img /js 使会指向 nginx/html 中的 css、img、js
root html;
index index.html index.htm
}
}
}
随着技术的发展,特别是前后端分离的开发模式,上述情况也不复存在,后端也不用考虑到静态资源该怎么处理,都转移给到前端了
资源防盗链
保护网站资源不被其他网站盗用的技术措施
防盗链的实现原理:
- 服务器收到请求后,获取请求头中的
referer字段 - 验证
referer字段是否符合预设的规则,例如是否在允许的域名列表中 - 如果
referer验证通过,则允许访问资源;否则,拒绝访问或返回特定的错误页面
情况一:页面引用图片请求头中会携带 referer 头,值就是引用该资源的这个地址
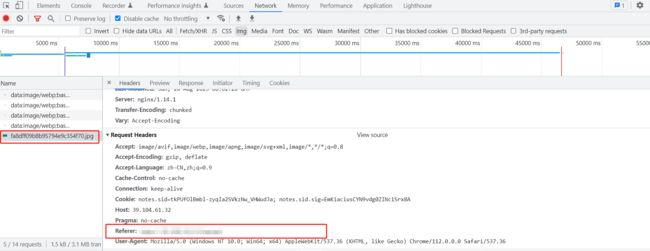
情况二:单独复制该图片地址,重新打开窗口访问时,请求该图片时,referer 头就不会携带给到后端

配置一:两种情况都不能访问资源(图片)
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location /img {
valid_referers blog.hhmax.xyz;
if ($invalid_referer) {
return 403;
}
# 路径中有 /nginx/img
root img;
index index.html index.htm
}
}
}
valid_referers:配置的值得跟server_name一样

配置二:仅第二种情况可以访问资源
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location /img {
valid_referers none blog.hhmax.xyz;
if ($invalid_referer) {
return 403;
}
# 路径中有 /nginx/img
root img;
index index.html index.htm
}
}
}
valid_referers:配置的值得跟server_name一样
配置后:

没有权限访问图片,也可以配置返回一个错误页面,或者一个错误图片
- 错误页面
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location /img) {
valid_referers blog.hhmax.xyz;
if ($invalid_referer) {
return 401;
}
root img;
index index.html index.htm
}
error_page 401 /401.html
location = /401.html {
root html;
}
}
}
- 错误图片
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen: 80,
server_name blog.hhmax.xyz;
location /img {
valid_referers blog.hhmax.xyz;
if ($invalid_referer) {
return ^/ /img/x.png break;
}
root html;
index index.html index.htm
}
}
}
通过正常手段,访问或者引用资源(图片),通过上述方法是可以避免资源被盗用的。因为referer 字段通过某些手段是可以被伪造或篡改。因此防盗链并不能完全阻止盗链行为。为了增加安全性,可以结合其他技术手段,如加密链接、动态生成链接等,来提高防盗链的效果。