Prometheus服务器监控搭建
Prometheus服务器监控搭建
Prometheus是一个开放性的监控解决方案,用户可以非常方便的安装和使用Prometheus并且能够非常方便的对其进行扩展。为了能够更加直观的了解Prometheus Server,接下来我们将在本地部署并运行一个Prometheus Server实例,通过Node Exporter采集当前主机的系统资源使用情况。 并通过Grafana创建一个简单的可视化仪表盘。
Prometheus server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包
export VERSION=2.4.3
curl -LO
https://github.com/prometheus/prometheus/releases/download/v$VERSION/prometheus-$VERSION.darwin-amd64.tar.gz
解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-${VERSION}.darwin-amd64.tar.gz
cd prometheus-${VERSION}.darwin-amd64```
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数–storage.tsdb.path="data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yml文件:
./prometheus
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus
Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,可以通过http://localhost:9090访问Prometheus的UI界面:
Node_Exporter采集服务数据
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node
exporter版本的二进制包
安装Node Exporter
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.15.2/node_exporter-$VERSION.linux-amd64.tar.gz
tar -xzf node_exporter-$VERSION.linux-amd64.tar.gz
运行node exporter:
cd node_exporter-$VERSION.darwin-amd64
cp node_exporter-$VERSION.linux-amd64/node_exporter /usr/local/bin/
node_exporter
访问http://localhost:9100/可以看到以下页面:

初始Node Exporter监控指标
访问http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:

每一个监控指标之前都会有一段类似于如下形式的信息:
HELP node_cpu Seconds the cpus spent in each mode.
TYPE node_cpu counter
node_cpu{cpu=“cpu0”,mode=“idle”} 362812.7890625
HELP node_load1 1m load average.
TYPE node_load1 gauge
node_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
node_boot_time:系统启动时间
node_cpu:系统CPU使用量
nodedisk*:磁盘IO
nodefilesystem*:文件系统用量
node_load1:系统负载
nodememeory*:内存使用量
nodenetwork*:网络带宽
node_time:当前系统时间
go_:node exporter中go相关指标
process_:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:

如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance=“localhost:9090”,job=“prometheus”} 1
up{instance=“localhost:9100”,job=“node”} 1
其中“1”表示正常,反之“0”则为异常。
Grafana监控数据可视化
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
安装grafana
官网下载地址:Grafana
安装指南:Grafana安装指南
根据自己的系统版本和配置,下载对应的包,官方提供了如下说明,可直接按照说明进行下载:
下载安装完成后,输入命令 service grafana-server start 启动服务。
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:

这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:

在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个类型为“Graph”的面板。 并在该面板的“Metrics”选项下通过PromQL查询需要可视化的数据:

点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:

Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard
Prometheus告警处理
Alertmanager和Prometheus Server一样均采用Golang实现,并且没有第三方依赖。一般来说我们可以通过以下几种方式来部署Alertmanager:二进制包、容器以及源码方式安装。
部署AlertManager
Alertmanager最新版本的下载地址可以从Prometheus官方网站https://prometheus.io/download/获取。
export VERSION=0.15.2
curl -LO https://github.com/prometheus/alertmanager/releases/download/v$VERSION/alertmanager-$VERSION.darwin-amd64.tar.gz
tar xvf alertmanager-$VERSION.darwin-amd64.tar.gz
创建alertmanager配置文件
Alertmanager解压后会包含一个默认的alertmanager.yml配置文件,内容如下所示:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
Alertmanager的配置主要包含两个部分:路由(route)以及接收器
(receivers)。所有的告警信息都会从配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器。
在Alertmanager中可以定义一组接收器,比如可以按照角色(比如系统运维,数据库管理员)来划分多个接收器。接收器可以关联邮件,Slack以及其它方式接收告警信息。
当前配置文件中定义了一个默认的接收者default-receiver由于这里没有设置接收方式,目前只相当于一个占位符。关于接收器的详细介绍会在后续章节介绍。
在配置文件中使用route定义了顶级的路由,路由是一个基于标签匹配规则的树状结构。所有的告警信息从顶级路由开始,根据标签匹配规则进入到不同的子路由,并且根据子路由设置的接收器发送告警。目前配置文件中只设置了一个顶级路由route并且定义的接收器为default-receiver。因此,所有的告警都会发送给default-receiver。关于路由的详细内容会在后续进行详细介绍。
启动Alertmanager
Alermanager会将数据保存到本地中,默认的存储路径为data/。因此,在启动Alertmanager之前需要创建相应的目录:./alertmanager
用户也在启动Alertmanager时使用参数修改相关配置。--config.file用于指定alertmanager配置文件路径,--storage.path用于指定数据存储路径。
查看运行状态
Alertmanager启动后可以通过9093端口访问,http://localhost:9093
Alert菜单下可以查看Alertmanager接收到的告警内容。Silences菜单下则可以通过UI创建静默规则,这部分我们会在后续部分介绍。进入Status菜单,可以看到当前系统的运行状态以及配置信息。
关联Prometheus与Alertmanager
在Prometheus的架构中被划分成两个独立的部分。Prometheus负责产生告警,而Alertmanager负责告警产生后的后续处理。因此Alertmanager部署完成后,需要在Prometheus中设置Alertmanager相关的信息。
编辑Prometheus配置文件prometheus.yml,并添加以下内容
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
重启Prometheus服务,成功后,可以从http://192.168.2.115:9090/config查看alerting配置是否生效。
此时,再次尝试手动拉高系统CPU使用率:
cat /dev/zero>/dev/null
等待Prometheus告警进行触发状态:
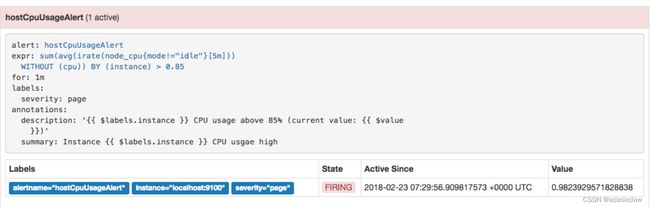
查看Alertmanager UI此时可以看到Alertmanager接收到的告警信息。