在之前的《机器学习洞察》系列文章中,我们分别针对于多模态机器学习和分布式训练、无服务器推理进行了解读,本文将为您重点介绍 JAX 的发展并剖析其演变和动机。下面,就让我们来认识一下 JAX 这一新崛起的深度学习框架——
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
开源机器学习框架的演进

从这张 GitHub Star 趋势图可以看到,自 2019 年 JAX 出现到如今保持着一个向上的抛物线走势。
在考察一个开源机器学习框架时,例如开发者熟知的 PyTorch, TensorFlow, MXNet 等,往往会从支持模型的广泛性、部署的成熟性、生态系统的丰富性来对它做一个评估:包括是否支持 Hugging Face 等主流模型,以及其框架相关研究论文的数量,还有它可提供复现代码的论文数量等等。
JAX 的源起
- 为什么 Eager 模式是在 TensorFlow 1.4 版本之后引入的?
- Eager 模式在 TensorFlow 2.0 之后变成了一个默认的执行模式,和原有的 Graph 模式的区别是什么?
- …
回归并理清这些历史问题有助于开发者了解机器学习的演变逻辑,并了解 JAX 是如何吸取之前的教训,帮助开发者更方便地实践深度学习或机器学习应用。
Eager 模式 V.S. Graph 模式
在 TF 引进了 Eager 模式之后,它会采用更直观的界面,使用自然的 Python 代码和数据结构,而且享受更加便携的调试,在 Eager 模式中可以通过直接调用操作来检查和测试模型,而之前 Graph 这种模式有点类似于 C 和 C++,它的编程是写好程序之后要先进行编译才能运行。
Eager 模式有自然控制的流程,使用 Python 而不是图控制流,以及支持 GPU 和 TPU 的加速。做为开发者,我们希望可以客观地看待不同的框架,而不是比较他们的优劣。值得思考的一个问题是:通过了解 TF 的 Eager 模式对于 Graph 模式的改进,它的改进逻辑和思路在 JAX 中都有身影。
什么是 JAX

JAX 作为现在越来越流行的库,是一种类似于 NumPy(使用 Python 开源的数值计算扩展库)的轻量级用于阵列的计算。JAX 最开始的设计不仅仅是为了深度学习而设计的,深度学习只是它的一小部分,它提供了编写 NumPy 程序的能力,这些程序可以使用 GPU/TPU 自动拆分和加速。
JAX 用于基于阵列的计算时,开发者无需修改代码就可以在 CPU/GPU/ASIC 上同时运行,并支持原生 Python 和 NumPy 函数的四种可组合函数转换:
- 自动微分 (Autodiff)
- 即时编译 (JIT compilation)
- 自动向量化 (Vectorization)
- 代码并行化 (Parallelization)
JAX 初体验
我们可以通过下面这个简单的测试对比 JAX 和 NumPy 的计算性能。
输入一个 100 X 100 的二维数组 X,选取 ml.g4dn.12xlarge 计算实例通过 NumPy 和 JAX 分别对矩阵的前三次幂求和:
def fn(x):
return x + x*x + x*x*x
x = np.random.randn(10000, 10000).astype(dtype='float32')
%timeit -n5 fn(x)
436 ms ± 206 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)我们发现此计算大约需要 436 毫秒。接下来,我们使用 JAX 实现以下计算:
jax_fn = jit(fn)
x = jnp.array(x)
%timeit jax_fn(x).block_until_ready()
3.67 ms ± 10.7 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
JAX 仅在 3.67 毫秒内执行此计算,比 NumPy 快 118 倍以上。可见,JAX 有可能比 NumPy 快几个数量级(注意,JAX 使用 TPU 而 NumPy 正在使用 CPU)。
*以上为个人测试结果,非官方提供的数据,仅供研究参考
对比测试结果可得,NumPy 完成计算需要 436 毫秒,而 JAX 仅需要 3.67 毫秒,计算速度相差 100 多倍。这个测试也说明了为什么很多开发者对它的性能赞不绝口。
JAX 的动机剖析
我们希望通过回答这个问题来解读 JAX 的动机:
如何使用 Python 从头开始实现高性能和可扩展的深度神经网络?
在 NumPy 中创建深度学习系统
通常,Python 程序员会从 NumPy 之类的东西开始,因为它是一种熟悉的、基于数组的数据处理语言,在 Python 社区中已经使用了几十年。如果你想在 NumPy 中创建深度学习系统,你可以从预测方法开始。
这里可以用一个详细的例子说明问题,从 NumPy 上的深度学习的场景说起:
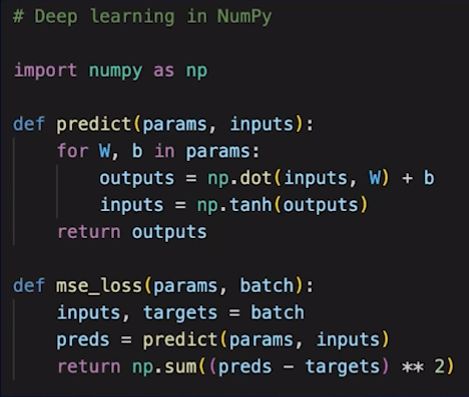
上述代码展示了订阅一个前馈的神经网络,它执行了一系列的点积和激活函数,然后将输入转化为某种可以学习的输出。一旦定义了这样的一个模型,接下来需要做就是要定义损失函数,这个函数将为你提供正在尝试优化的那些指标,来适应最佳的机器学习模型。例如以上代码的损失函数是以均方误差损失函数 MSE 为例。
现在我们来分析下:在深度学习场景使用 NumPy 还缺少什么?
硬件加速 (GPU/TPU)
自动微分 (autodiff) 快速优化
添加编译 (Compilation) 融合操作
向量化操作批处理 (batching)
大型数据集并行化 (Parallelization)
1)硬件加速 (GPU/TPU):首先深度学习需要大量的计算,我们想在加速的硬件上运行它。所以我们想在 GPU 和 TPU/ASIC 上运行这个模型,这对于经典的 NumPy 来说有点困难;
2)自动微分 (autodiff) 快速优化:接下来我们想要做自动微分,这样就可以有效地拟合这个损失函数,而不必自己来实现数值微分;
3)然后我们需要添加编译 (Compilation):这样你就可以将这些操作融合在一起,使它们更加高效;
4)向量化操作批处理 (Batching):另外,当我们编写了某些函数后,可能希望将其应用于多个数据片段,而不再需要重写预测和损失函数来处理这些批量数据;
5)大型数据集并行化 (Parallelization):最后,如果我们正在处理大型数据集,会希望能够支持跨多个 cores 或多台 machines 做并行化操作。
JAX 的动机剖析:XLA 和自动定位
JAX 非常重要的一个动机就是 XLA 和自动定位。让我们来看看 JAX 可以做些什么,来填补前面分析的在深度学习场景使用 NumPy 还缺少的功能。
首先,用 jax.numpy 替换 numpy 导入模块。在许多情况下,jax.numpy 与经典的 NumPy 具有相同的 API,但 jax.numpy 可以完成前面分析时发现 NumPy 缺少,但是在深度学习场景却非常需要的的东西。
JAX 可以通过 XLA 后端,来自动定位 CPU、GPU 和 TPU 或者 ASIC,以便快速计算模型和算法。
JAX 动机剖析:Autograd
第二个重要动机是 Autograd。开发者可以通过下面的代码调用 Autograd 版本:
通过 from jax import grad 模块,使用 Autograd 的更新版本,JAX 可以自动微分原生 Python 和 NumPy 函数。它可以处理 Python 功能的大子集,包括循环、Ifs、递归等,甚至可以接受导数的导数。
JAX 提供了一组可组合的变换,其中之一是 grad 变换。
例子中,像 mse_loss 这样的损失函数,通过 grad (mse_loss) 将其转换为计算梯度的 Python 函数。
Autograd 的主要预期应用是基于梯度的优化。
有关更多信息,请查看 JAX 教程和示例:Https://github.com/hips/autograd
JAX 动机剖析:vmap
在使用梯度函数时,开发者希望将其应用于多个数据片段,而在 JAX 中,你不再需要重写预测和损失函数来处理这些批量数据。
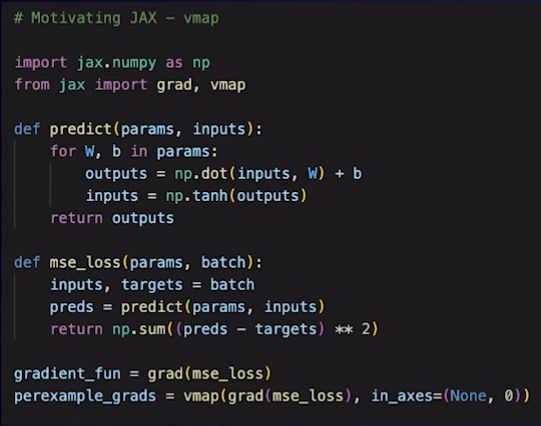
如图中代码最后一行 (perexample_grads …) 所诠释的那样,如果你通过 vmap transform 传递它,这会自动向量化这个代码,这样就可以在多个批次中使用相同的代码。
JAX 动机剖析:jit
JAX 还有一个重要的组合函数——jit,开发者可以使用 jit transform 实现即时编译。
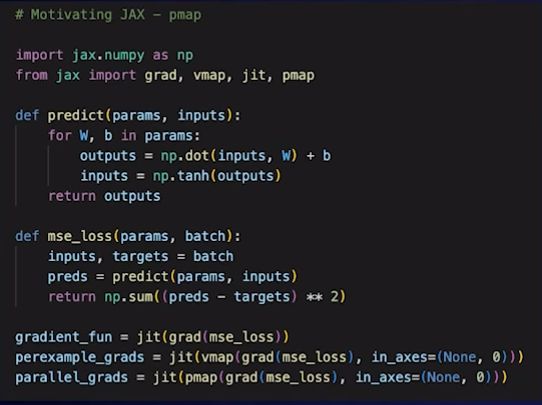
jit 结合后台可以使用 XLA 后端编译器将操作融合在一起,来自动定位 CPU、GPU 和 TPU 或者 ASIC,加速计算模型和算法。
JAX 动机剖析:pmap
最后,如果想并行化你的代码,有一个和 vmap 非常相似得转换叫 pmap。
通过代码运行 pmap,开发者能够本地定位系统中的多个内核或你有权访问的 GPU、TPU 或 ASIC 集群。

这最终成为一个非常强大的系统,可以在没有太多额外代码的情况下构建我们用类似于 NumPy 的熟悉 API,做深度学习的快速计算等工作负载。
JAX 的关键设计思想
通过上述对比可以看到, JAX 不仅为开发者提供了和 NumPy 相似的 API,上述的五大函数转换组合也让 JAX 可以在不需要额外代码的情况下,帮助开发者构建深度学习应用进行快速计算。
这里的关键思想是:
1)首先,在 JAX 中,Python 代码被追溯到中间表示,JAX 知道如何转换这个中间表示。
2)在下篇文章中我们也将详细分析 JAX 的工作机制:同样的中间表示,通过允许 XLA 进行特定领域 (CPU/GPU 等) 的编译,如何来瞄准不同的后端;
3)另外,JAX 还有基于 NumPy 和 SciPy 的面向用户的 API,如果开发者一直使用 Python 的技术栈,应该会对 JAX 感觉相当熟悉;
4)最后,JAX 提供了功能强大的变换:grad, git, vmap, pmap 等,来支持深度学习等计算,因此 JAX 可以做到之前 NumPy 代码无法做到的事情。
通过前面的介绍,我们可以看到,开发者熟悉的 API 和语法以及四种强大的转换组合让开发者更加喜欢 JAX,并让深度学习场景或者科学计算变得非常简便。篇幅有限,我们将在下篇文章中通过实例为开发者深入介绍 JAX 的工作机制和生态场景。您也可以在亚马逊云科技开发者社区官网《机器学习洞察》视频栏目观看这一部分的视频演讲:
点击查看视频:https://dev.amazoncloud.cn/video/videoDetail?id=63e393ace5e05...
欢迎回顾关于机器学习的往期文章,以及更多面向开发者的技术分享。请持续关注亚马逊云科技开发者社区官网《机器学习洞察》视频栏目!
往期推荐

作者
黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/63e33239e5e05b6ff89...