Redis五种数据类型的应用场景
前言:Redis 是一种基于键值对的NoSQL缓存数据库,key都是由字符串构成的,而它的值主要由string(字符串),hash(哈希),list(列表),set(集合),zset(有序集合)五种基本数据结构构成,除此之外还支持一些其他的数据结构和算法。在开发中,字符串类型是用的最多的数据类型,导致我们忽视了redis的其他四种数据类型,在具体场景下选择具体的数据类型对提升Redis性能有非常大的帮助。
一、string
字符串类型是Redis最基础的数据结构,字符串类型可以是JSON、XML甚至是二进制的图片等数据,但是最大值不能超过512MB。Redis 里的字符串是SDS简单动态字符串,会根据实际情况动态调整。
1.1、缓存
简单key-value存储:在Web服务中,使用MySQL作为数据库,Redis作为缓存。由于Redis具有支撑高并发的特性,通常能起到加速读写和降低后端压力的作用。Web端的大多数请求都是从Redis中获取的数据,如果Redis中没有需要的数据,则会从MySQL中去获取,并将获取到的数据写入Redis。
1.2、分布式锁
setnx key value,当key不存在时,将key 的值设为 value ,返回1;
若给定的 key 已经存在,则setnx不做任何动作,返回0。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁;如果setnx返回0表示获取锁失败,整体思路大概就是这样
1.3、计数器
Redis中有一个字符串相关的命令incr key,incr命令将 key 中储存的数字值增一,返回结果分为以下三种情况:
-
值不是整数,返回错误
-
值是整数,返回自增后的结果
-
key不存在, key 的值会先被初始化为 0 ,返回1
比如文章的阅读量,视频的播放量等等都会使用redis来计数,每播放一次,对应的播放量就会加1,同时将这些数据异步存储到数据库中达到持久化的目的。
(1)知乎每个问题的被浏览器次数
set key 0
incr key // incr readcount::{帖子id} 每阅读一次
get key // get readcount::{帖子id} 获取阅读量 (2) IP限制
为了安全考虑,有些网站会对IP进行限制,限制同一IP在一定时间内访问次数不能超过n次。
1.4、共享Session
在分布式系统中,用户的每次请求会访问到不同的服务器,这就会导致session不同步的问题,假如一个用来获取用户信息的请求落在A服务器上,获取到用户信息后存入session。下一个请求落在B服务器上,想要从session中获取用户信息就不能正常获取了,因为用户信息的session在服务器A上,为了解决这个问题,使用redis集中管理这些session,将session存入redis,使用的时候直接从redis中获取就可以了。
二、hash
Redis的散列可以让用户将多个键值对存储到一个Redis的键里面,散列非常适用于将一些相关的数据存储在一起。类似map的一种结构,将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存到redis中,以后每次读写内存时,就可以操作hash里的某个字段。
2.1、hash内部编码
哈希类型的内部编码有两种:
-
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)同时所有值都小于hash-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,所以比hashtable更加节省内存。
-
hashtable(哈希表):当ziplist不能满足要求时,会使用hashtable。
2.2、使用场景
由于hash类型存储的是多个键值对,比如数据库有以下一个用户表结构
| id | name | age |
|---|---|---|
| 1 | 何哥 | 18 |
将以上信息存入redis,用表名:id作为key,用户属性作为值:
hset user:1 name 何哥 age 18使用哈希存储会比字符串更加方便直观
三、list
Redis 里的 List 是一个链表,由于链表本身插入和删除比较块,但是查询的效率比较低,所以常常被用做异步队列。Redis 里的 List 设计非常牛,当数据量比较小的时候,数据结构是压缩链表,而当数据量比较多的时候就成为了快速链表。
列表类型用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素,列表的两端都可以插入和弹出元素。
3.1、消息队列
在业务中异步队列使用 rpush/lpush 操作队列,使用 lpop 和 rpop 出队列,具体结构如下图所示:
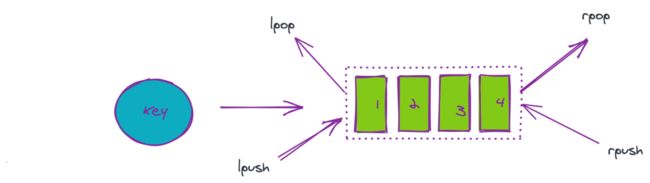
Redis虽然支持消息队列的实现,但是并不支持ack。所以redis实现的消息队列不能保证消息的可靠性,除非自己实现消息确认机制,不过这非常麻烦,所以如果是重要的消息还是推荐使用专门的消息队列去做。
3.2、文章列表
因为列表的元素不但是有序的,而且还支持按照索引范围获取元素。因此我们可以使用命令lrange key 0 9分页获取文章列表
四、set
set集合类型也可以保存多个字符串元素,与列表不同的是,集合中不允许有重复元素并且集合中的元素是无序的。一个集合最多可以存储2^32-1个元素。
无序集合,自动去重,将数据放到set中就可去重,可以基于JVM的HashSet去重,如果系统部署在多台机器上,就可以用redis进行全局去重。可以基于set做交集,并集,差集的操作。如把2个人的粉丝列表弄一个交集,就能看到两个人的共同好友是谁。
4.1、用户标签
例如一个用户对篮球、足球感兴趣,另一个用户对橄榄球、乒乓球感兴趣,这些兴趣点就是一个标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同感兴趣的标签。给用户打标签的时候需要①给用户打标签,②给标签加用户,需要给这两个操作增加事务。
-
给用户打标签
sadd user:1:tags tag1 tag2-
给标签添加用户
sadd tag1:users user:1
sadd tag2:users user:1使用交集(sinter)求两个user的共同标签
sinter user:1:tags user:2:tags4.2、抽奖功能
集合有两个命令支持获取随机数,分别是:
-
随机获取count个元素,集合元素个数不变
srandmember key [count]-
随机弹出count个元素,元素从集合弹出,集合元素个数改变
spop key [count]用户点击抽奖按钮,参数抽奖,将用户编号放入集合,然后抽奖,分别抽一等奖、二等奖,如果已经抽中一等奖的用户不能参数抽二等奖则使用spop,反之使用srandmember。
五、zset(sorted set )
zset是Redis中最具有特色的数据结构(跳跃列表),首先它有set不可重复的特性,在这个基础上,还可以给value赋予一个排序权重score,所谓的有序其实就是根据这个得分来排序。排序的set,可以去重还可以排序,写进去的时候给一个分数,自动根据根据分数排序,分数可以自定义排序规则。
Redis 有序集合zset和集合set一样也是String类型元素的集合,且不允许重复的成员。不同的是 zset 的每个元素都会关联一个分数(分数可以重复),redis 通过分数来为集合中的成员进行从小到大的排序。Redis的zset天生是用来做排行榜的,榜单,总榜,热榜。
5.1、zset内部编码
有序集合类型的内部编码有两种:
-
ziplist(压缩列表):当有序集合的元素个数小于list-max-ziplist-entries配置(默认128个)同时所有值都小于list-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,更加节省内存。
-
skiplist(跳跃表):当不满足ziplist的要求时,会使用skiplist。
5.2、zset类型操作命令
1)基本命令: zadd/ zrange/ zrevrange/zrem/zcard
2)常用命令: zrangebyscore/zrevrangebyscore/zcount
zadd
语法:zadd key score member [score member…]
作用:将一个或多个 member 元素及其 score 值加入到有序集合 key 中,如果 member存在集合中, 则更新值;score 可以是整数或浮点数
返回值:数字,新添加的元素个数
zincrby
语法:ZINCRBY key increment member
作用:对有序集合中指定成员的分数加上增量 increment
zrange
语法:zrange key start stop [WITHSCORES]
作用:查询有序集合,指定区间的内的元素。集合成员按 score 值从小到大来排序。
start,stop 都是 从 0 开始。0 是第一个元素,1 是第二个元素,依次类推。
以 -1 表示最后一个成员,-2 表示倒数第二 个成员。WITHSCORES 选项让 score 和 value 一同返回。
返回值:自定区间的成员集合
zrevrange
语法:zrevrange key start stop [WITHSCORES]
作用:返回有序集 key 中,指定区间内的成员。
其中成员的位置按 score 值递减(从大到小)来排列。 其它同 zrange 命令。
返回值:自定区间的成员集合
zrem
语法:zrem key member [member…]
作用:删除有序集合 key 中的一个或多个成员,不存在的成员被忽略
返回值:被成功删除的成员数量,不包括被忽略的成员。
zcard
语法:zcard key
作用:获取有序集 key 的元素成员的个数
返回值:key 存在返回集合元素的个数, key 不存在,返回 0
zrangebyscore
语法:zrangebyscore key min max [WITHSCORES ] [LIMIT offset count]
作用:获取有序集 key 中,所有 score 值介于 min 和 max 之间(包括 min 和 max)的成员,有序成员是按递增(从小到大)排序。
min ,max 是包括在内 , 使用符号 ( 表示不包括。
min , max 可以使用 -inf ,+inf 表示 最小和最大 limit 用来限制返回结果的数量和区间。
withscores 显示 score 和 value
返回值:指定区间的集合数据
zrevrangebyscore
语法:zrevrangebyscore key max min [WITHSCORES ] [LIMIT offset count]
作用:返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成 员。
有序集成员按 score 值递减(从大到小)的次序排列。其他同 zrangebyscore
zcount
语法:zcount key min max
作用:返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max ) 的成员的数量
显示整个有序集成员,让 score 和 value 一同返回:
redis > ZRANGE salary 0 -1 WITHSCORES
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"5.3、排行榜
用户发布了n篇文章,其他人看到文章后给喜欢的文章点赞,使用score来记录点赞数,有序集合会根据score排行。流程如下
用户发布一篇文章a,初始点赞数为0,即score为0
zadd user:article 0 a有人给文章a点赞,递增1
zincrby user:article 1 a查询点赞前三篇文章
zrevrangebyscore user:article 0 2查询点赞后三篇文章
zrangebyscore user:article 0 2参考链接:
凉了呀,面试官让我设计一个排行榜
一文搞定Redis五大数据类型及使用场景
一口气说出 Redis 16 个常见使用场景
Redis--zset类型操作命令