CUDA编程实战(使用Sobel算子对rgb图片进行边缘检测)
写在前面,本篇文章为一个CUDA实例,使用GPU并行计算对程序进行加速。如果不需要看环境如何配置,可以直接到看代码部分:点击直达
关于如何更改代码和理解代码写在这个地方:点击直达
运行环境:
系统:windows10专业版
显卡:NVIDIA 1050Ti
软件环境:VS2019,NVIDIA CUDA,Opencv
写在前面:因为本篇文章记录的是CUDA的实例,所以默认已经安装了CUDA和OpenCV的环境,所以本文仅写了如何从打开visual studio2019到配置好环境再到写完代码运行
如果安装cuda出现问题,可以看我的这篇文章,希望可以帮助到你。文章链接
1.确认环境配置
因为有些人使用的是较早的vs版本,所以对cuda的配置是手动的,所以这里提供一个代码(也是官方代码)来证明是否cuda配置完成了,直接把下述代码复制粘贴,能运行即证明cuda配置完成。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 2.新建项目
2.1打开vs

2.2创建新项目

2.3选择文件位置和项目名称
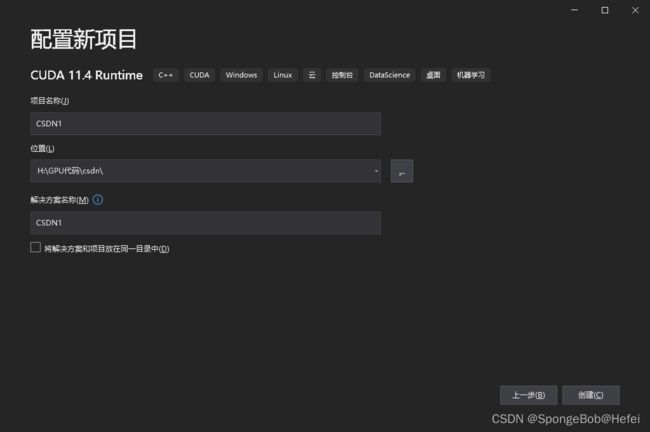
2.4打开之后运行一下自带代码,运行成功表示CUDA运行正常,开始进行OpenCV的环境配置
3.配置OpenCV
3.1打开属性配置

3.2找到oepncv安装所在目录,然后切到如下位置
即打开项目->配置属性->VC++目录->包含目录
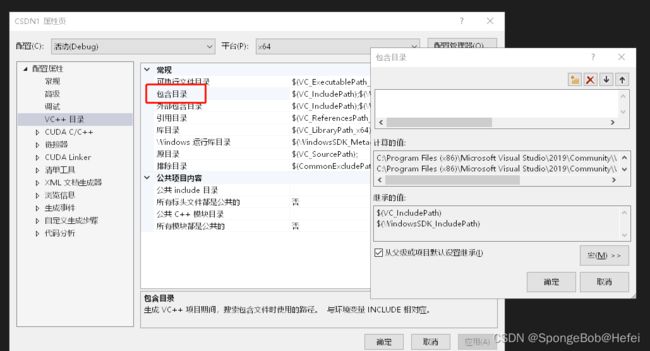
3.3在包含目录里面添加OpenCV的位置
主要添加Opencv的include文件夹和include下面的opencv2文件夹
如果include文件夹下面不仅有opencv2的文件夹,还有一个opencv的文件夹,则除了添加题主添加的两项,还需要将opencv的文件夹也要放到包含目录里面来(原理不是很清楚,但是看到很多的博主都放到了里面,所以建议还是放进去)

3.4 在库目录中添加OpenCV
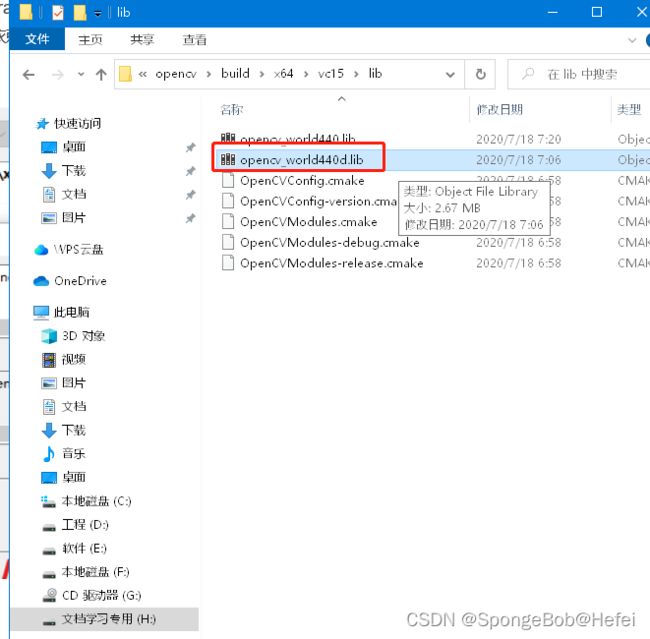
关掉包含目录之后,打开库目录,然后对Opencv的lib文件进行引用,因为每个人的版本不同,所以看到的文件夹可能不同,只要记住放的是以下目录即可:
H:\import OpenCV\opencv\build\x64\vc15\lib

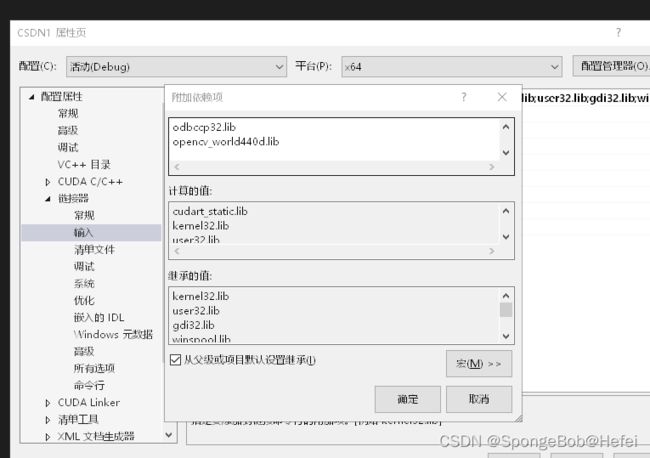
3.5在附加依赖项中添加OpenCV
打开附加依赖项,然后添加opencv_world440d.lib,这一步有两个文件,一个是不带d的.lib文件,一个是带d的.lib文件,区别在于一个是release的文件,一个是debug的文件,就如果你的vs是debug运行,就导入带d的lib文件,如果你的vs是release状态运行,就导入不带d的lib文件,因为题主是debug运行态,所以导入的是带d的文件

3.6添加下列代码,如果运行成功,表示OpenCV环境配置完成(记得更改图片位置,因为每个人的图片位置不一样,自己随意找一张图片就行了)
#include 
4.环境配置完毕,CUDA项目代码如下,放到.cu文件里直接运行就行了
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
代码讲解:
这个代码是题主的运行代码,里面涉及到文件的读取和处理,可能无法直接运行,做下路径更改后即可运行
注意事项如下:
1.需要一张图片,然后把自己的图片路径替换进去,windows系统下使用\时记得用两个斜线,一个\会读取文件失败,导致图片读取不了
2.代码首先执行读取图片,如果读取成功则继续执行,读取失败则直接返回
3.因为图片为RPG图片(sobel算子是作用在灰度图上的,题主当时调研的时候没有考虑到这一点,所以采用的是RGB图片进行处理,当然,三个维度的叠加导致最后的边缘界限和图片效果都长得不是很好看,如果想做灰度图的话可以直接调库把图片转换为二维的灰度图即可,这样效果可以更加显著),所以decode函数会对图片进行编码,即将一个三维矩阵按照行来进行拓宽。行数不变,列数变成原来的三倍,因为GB的元素值都被横向拓宽到了R上面,这样我们就可以对一个二维的数据进行处理
4.执行CPU之后会返回运行时间,然后INFO展示一下GPU的各种运行状态。
5.然后进入GPU CUDA运行,题主建议在统计运行时间时可以只计算运行时间,因为把数据装在到GPU上也需要时间,而cpu加载数据较快,这样显得加速比不明显,可以直接比较运行的时间,这样可以看得出几十倍的加速
6.代码写的较乱,有关核函数和CPU,GPU运行相关的代码可以直接套用,不需要更改,因为题主已经把他们给转换成了二维矩阵,运行都是按照矩阵运行的。
7.对于R和G,G和B的边缘元素点的处理方法,题主选择偷了个懒,直接保持原值,即如果监测到了他是边缘点,直接保持他原来的元素值,这样避免了R对G维度的干扰。
8.如果代码运行不起来,欢迎留言讨论,因为这个代码是五月份写的,然后后续很长时间没管,也删除了很多的函数(从开头定义的code函数部分就可以看到,这本身是用于图片保存的,即图片进行sobel算子运算后,我们将二维矩阵又变回三维矩阵,然后题主偷懒,就没有调用它),也有部分没删,出现bug欢迎一起探讨