Text-to-SQL小白入门(三)IRNet:引入中间表示SemQL
摘要
本文主要介绍了IRNet论文的基本信息,比如标题、摘要、数据集、结果&结论,以及论文中提出的不匹配问题和词汇问题以及对应的解决方案,重点学习了中间表示SemQL。
引言
学习论文时,可以先粗略看看论文标题-摘要-数据集-结果/结论,最后想详细了解信息的话可以重点看看模型结构/代码实践等
论文标题
今天学习的论文是西安交通大学、北京邮电大学、微软发表于2019年ACL的文章《Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation》,后面大家简称为IRNet (Intermediate Representation Network简写)。
- 英文标题:Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
- 中文翻译:使用中间表示(Intermediate Representation)在跨域数据集实现复杂的Text-to-SQL
- 论文作者:Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, Dongmei Zhang
- 作者单位:西安交通大学、北京邮电大学、微软
- 发表会议:2019 ACL(Annual Meeting of the Association for Computational Linguistics),CCF-A
- 文章链接:https://arxiv.org/abs/1905.08205
- 代码链接:GitHub - microsoft/IRNet: An algorithm for cross-domain NL2SQL
看论文的意外之喜,仙交厉害啊
郭家琪和刘烃老师也是首个跨领域多轮Text2SQL中文数据集——CHASE数据集的作者!!!
那就顺带再放一下陕西省天地网重点实验室-刘烃老师组介绍:软件系统安全小组-陕西省大数据知识工程重点实验室

论文摘要
摘要已经把论文的核心说清楚了
核心创新点是在从自然语言问题->到SQL语言过程中,引入中间层表示,论文中称为SemQL
也就是:NL -> SemQL -> SQL
- 作者提出了一种称为IRNet的方法,适用于复杂和跨领域的Text2SQL。
- IRNet旨在解决两个挑战:
- mismatch problem:自然语言(NL)表达的意图与SQL实现细节之间的不匹配;
- lexical problem:大量的领域外的词给预测列带来了挑战。
- 与端到端合成SQL查询不同,IRNet将合成过程分解为三个阶段。
- schema linking:IRNet在问题和数据库模式之间执行模式链接。
- 生成SemQL:IRNet采用基于语法的神经模型来合成一个SemQL查询。(SemQL查询是作者设计的连接NL和SQL的中间表示)
- 生成SQL:IRNet确定地从具有领域知识的合成SemQL查询中推断出SQL查询。
- 在数据集Spider上,IRNet达到了46.7%的准确率,比以前最先进的方法获得了19.5%的绝对改进。
- IRNet在数据集Spider获得了第1名。(2019年的时候)
论文数据集
论文数据集使用的是Spider数据集。
- Spider数据集是多数据库、多表、单轮查询的Text2SQL数据集,也是业界公认难度最大的大规模跨领域评测榜单,由2018年耶鲁大学提出,由11名耶鲁大学学生标注。
- 数据集下载地址:Spider: Yale Semantic Parsing and Text-to-SQL Challenge
- 数据集介绍参考:Text-to-SQL小白入门(一)
论文结果&结论
结果
效果提升巨大!!!
- Spider数据集上完全匹配精度exact matching accuracy在开发集和测试集都取得第1的效果,重点是提升巨大。
- 加上BERT后,提升效果更大。

特别困难的SQL需要有经验的SQL从业者才能写出,确实有点为难模型了。
- 可以发现在Spider的简单SQL上准确率已经77.2%,特别困难的SQL准确率才25.3%。

- 2019年榜单Test集是54.7%,2023年榜单Test集已经是74.0(提升空间仍然很大)
结论
看完结论,完结散花,开始下一篇
论文提出了什么方法
解决了什么问题
在什么数据集上验证了效果
论文提出了一种神经网络方法SemQL,用于复杂的跨域文本到sql,旨在解决词法问题以及模式链接和中间表示的不匹配问题。在具有挑战性的Spider基准测试上的实验结果证明了IRNet的有效性。
问题引入
前面摘要已经大概讲了原来的SQL的主要问题有2个
接下来细致讲解一下
mismatch problem不匹配问题
因为WikiSQL数据集相对简单,一些先进的端到端方法已经能达到80%以上的准确率了,但是在Spider数据集上却表现不佳。
Spider数据集带来了新的挑战。
- Spider中的SQL查询包含嵌套查询和子句,如GROUPBY和HAVING,这比WikiSQL复杂。
考虑下图的Text2SQL,问题中从未提到要在SQL查询中进行分组的列“student id”。实际上,SQL中引入GROUPBY子句是为了方便聚合函数的实现。
- 输入NL:
Show the names of students who have a
grade higher than 5 and
have at least 2 friends
(查询成绩大于5并且有至少2个以上朋友的学生姓名。)- 输出SQL:
SELECT T1.name
FROM friend AS T1 JOIN highschooler AS T2
ON T1.student_id = T2.id WHERE T2.grade > 5
GROUP BY T1.student_id HAVING count(*) >= 2
从本质上来说,SQL是为有效地查询关系数据库而设计的,而不是为了表示自然语言NL的含义。因此,在用自然语言表达的意图和用SQL实现的细节之间不可避免地存在不匹配,即mismatch problem。
lexical problem词汇问题
Spider数据集中划分了train训练集、dev验证集、test测试集
因为dev验证集中有35%的数据库模式的单词没有出现在训练集,相比之下,在WikiSQL中这个数字只有22%。
大量的OOD(out-of-domain)领域外的单词对SQL查询中的column列名预测提出了另一个严峻的挑战,因为OOD单词通常在神经模型中缺乏准确的表示。论文认为这个挑战是一个词汇问题。
问题解决
论文提出了问题
那么就要解决问题
为了解决这些问题,论文提出了IRNet。通过中间表示intermediate representation和模式链接schema linking来解决不匹配问题和词汇问题。
Intermediate Representation中间表示
为了消除这种不匹配,论文设计了一种特定于领域的语言,称为SemQL,它作为NL和SQL之间的中间表示。
下图左边就是与上下文无关的SemQL语法,下图右边代表一个SemQL查询的例子。
SQL例子:
SELECT T1.name
FROM friend AS T1 JOIN highschooler AS T2
ON T1.student_id = T2.id WHERE T2.grade > 5
GROUP BY T1.student_id HAVING count(*) >= 2

SemQL语法
如上图左边所示:简单理解一下:
- Z:表示两个查询集合R之间的操作:交集、并集、差集或者不做任何操作
- R:表示查询集:单纯查询(Select)| 查询过滤(Select Filter)| 查询排序后的结果(Select Order)| 查询聚合后的最值(Select Superlative)| 还有这些的组合情况
- Select:若干个通过查询得到的字段。
- Order:升序asc和降序desc
- Superlative:最多most或者最少least(论文图里面写的suerlative,应该是少写了一个字母)
- Filter:过滤条件之间的关系:and | or,或者其他的过滤条件(> | < | = | ..)
- A:aggregation聚合函数
- C:column列
- T:table表
SemQL例子
结合SemQL语法,理解一下上图右边:SemQL例子:从上往下,自顶向下遍历这颗SemQL树
- 只有一个查询集合,没有多个查询集的集合操作,所以直接从顶部 Z - R
- R是一个Select Filter (因为SQL中是 SELECT T1.name ... WHERE),这个Filter是由2个Filter组成的。
-
- Select 表friend的 name
- 两个Filter之间是and 关系
-
-
- 一个Filter是针对T2.grade > 5
- 另一个Filter是count(*) >= 2
-
SemQL优点:
受lambda DCS (Liang, 2013)的启发,SemQL被设计为树形结构,有两个优点:
- 有效地约束合成过程中的搜索空间。
- 鉴于SQL的树结构特性,遵循相同的结构也使其更容易直观地转换为SQL。
为什么能解决mismatch问题?
不匹配问题主要是由SQL查询中的实现细节和自然语言问题中缺少具体信息引起的。
因此,很自然地将实现细节隐藏在中间表示中,这构成了SemQL的基本思想。
考虑到上图右边部分,SQL查询中的GROUPBY、HAVING和FROM子句在SemQL查询中被消除,WHERE和HAVING中的条件在SemQL查询中的Filter子树中统一表示。
在后面的推理阶段,可以使用领域知识从SemQL查询确定地推断出实现细节。
- 举例子:SQL查询的GROUPBY子句中的列通常出现在SELECT子句中,或者它是聚合函数应用于其中一个列的表的主键。
SemQL推断SQL的前提
1.要求在SemQL中声明列所属的表。
- 比如列“name”及其表“friend”是在SemQL查询中声明的。
- 表的声明有助于区分模式中重复的列名。
2.基于数据库模式的定义是精确和完整的假设来执行推断。具体地说,
- 列是另一个表的外键,应该在模式中声明外键约束。
- 这个假设通常成立,因为它是数据库设计中的最佳实践。在Spider基准的训练集中,超过95%的例子都持有这个假设。
SemQL推断SQL的流程
以SQL查询中FROM子句的推理为例:
- 首先确定连接模式中SemQL查询中声明的所有表的最短路径
-
- (数据库模式可以表示为无向图,其中顶点是表,边是表的外键)
- 然后将所有在路径(path)上的数据表表都连接(joining)起来就得到了FROM从句
Schema Linking模式链接
IRNet中模式链接的目标是识别问题中提到的列名和表名,并根据它们在问题中提到的方式为这些列分配不同的类型:table | column | value
字符串匹配
实现方式:字符串匹配的方法。(简单但是高效)
- 首先枚举出一个NL问题中所有长度不大于的6的n-gram短语。(就是按不同长度找字符串子集)
- 从长度为1、2、3、4、5、6分别枚举一次,假如自然语言问题长度为x,总共可以有(6x -15)个分词
- 长度为1的短语有 x 个
- 长度为2的短语有 x - 1 个
- 长度为3的短语有 x - 2 个
- 长度为4的短语有 x - 3 个
- 长度为5的短语有 x - 4 个
- 长度为6的短语有 x - 5 个
- 如果某个n-gram短语恰好匹配上了某个字段名称, 或者是列名的子串, 那么就识别该n-gram短语是一个column
- 同理可以用相似的方法识别出某个n-gram短语是一个table;
- 如果某个n-gram短语同时被识别为column和table则优先认定为column;
- 如果某个n-gram短语以单引号开始+单引号结束,那么就认为是value
- 某个n nn-gram短语被指定了类型type, 那么所有与该n-gram短语字符串有重叠部分的n-gram短语全部被移除, 不再被考虑;
- 最后将所有识别出的实体序列(table 、column、value)与剩余的1-gram短语按原先NL问题中单词的顺序排列起来, 就可以得到一个互不重叠的实体序列;
- 根据⑤中得到的实体序列, 给序列中的每个n-gram短语分别附上table, column, value标签。这些短语在论文中称作一个span。
比如在下图中:自然语言问题Question中:
- Show、the、and等都是剩下的1-gram短语,标记为none
- book titles、years等是column
- books 是table
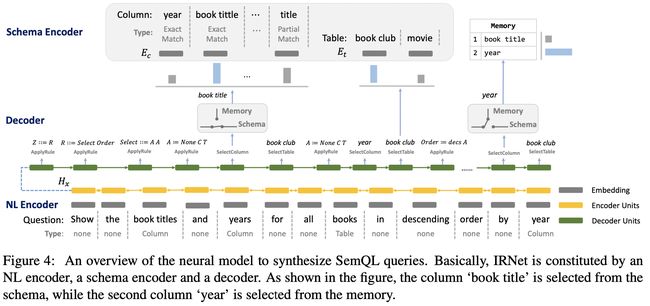
模型
前面分享了论文提出的问题以及对应的解决办法
接下来分享一下模型的其他部分,模型结果如上图所示
NL Encoder
- 作用:用于编码自然语言问题NL
- 输入:问题Question + n-gram的分词type
- 输出:Embedding
- 通过Bi-LSTM实现
Schema Encoder
- 作用:用于编码数据库schema信息。
- 输入:接受整个s作为输入
-
- s = (c, t)表示一个数据库结构schema
- c = {(column, type),(column, type),....(column, type)},表示所有的列和类型
- t 表示所有的table
- 输出:Embedding
Decoder
- 作用:用于生成SemQL查询。
- 鉴于SemQL的树状结构,论文使用基于语法的解码器(Yin和Neubig, 2017,2018),该解码器利用LSTM通过动作的顺序应用对SemQL查询的生成过程进行建模。
- 解码器与三种类型的操作交互以生成SemQL查询,包括APPLYRULE、SELECTCOLUMN和SELECTTABLE。
-
- ApplyRule(r):生成规则r应用于SemQL查询的当前派生树
- SelectColumn(c):从数据库schema中选择一个列column
- SelectTable(t):从数据库schema中选择一个表table
额外
memory augmented pointer network内存增强指针网络
- 作用:优化在合成SemQL过程中进行列column的选择。
- 具体:当一个字段被选到时, 该网络首先决定是否要在内存(memory)中选出, 这一点与普通的 pointer network不一样。
Coarse-to-fine粗力度到细粒度
- 作用:优化生成SemQL查询过程
- 具体:引入Coarse-to-fine框架,该框架是用来将SemQL查询的解码过程分解成两个阶段:
-
- 第一阶段: 一个框架(skeleton)解码器输出SemQL查询的框架(skeleton);
- 第二阶段:一个细节(detail)解码器通过选择字段和数据表来向第一阶段输出中填写缺失的细节
代码
GitHub - microsoft/IRNet: An algorithm for cross-domain NL2SQL

preprocess/sql2SemQL.py:
- 把sql 转化为 SemQL,便于训练。
sem2SQL.py:
- 把SemQL转化为 sql,便于输出测试。
参考
https://arxiv.org/abs/1905.08205
Spider: Yale Semantic Parsing and Text-to-SQL Challenge
【论文阅读】让数据库听懂人话(Text-to-SQL)_text2sql_囚生CY的博客-CSDN博客
Text-to-SQL小白入门(一) - 知乎