回归分析学习
回归分析
- 什么是回归分析
- 简单线性回归
-
- 线性回归(linear regression)
- 线性假设
- 如何拟合数据
- 线性回归的基本假设
- 损失函数(loss function)
-
- 最小二乘法(Least Square, LS)
- 梯度下降法(Gradient Descent,GD)
- 多元线性回归(multiple Linear Regression)
-
- 多元线性回归参数估计的推导(法二)
- 实例:家庭花销预测
- 以“误差平方和”为损失函数的优缺点
- 相关系数与决定系数
-
- 线性回归的相关系数
- 线性回归的决定系数(coefficient of determination)
- 总结
什么是回归分析
- Regression
- 回归分析是描述变量间关系的一种统计分析方法
- 例:在线教育场景
- 因变量Y:在线学习课程满意度(通常是一些预测或真实值)00000000000000000
- 自变量X:平台交互性、教学资源、课程设计(通常是一些特征)
- 前面提到过 西洋跳棋系统目标函数的设计也是一个回归问题
- 预测性的建模技术,通常用于预测分析
- 预测的结果多为连续值(但也可以是离散值,甚至是二值)
简单线性回归
线性回归(linear regression)
- 因变量和自变量之间是线性关系,就可以用线性回归来建模

线性回归的目的即找到最能匹配(解释)数据的截距和斜率
线性假设
- 线性: 有些变量间的线性关系是确定性的
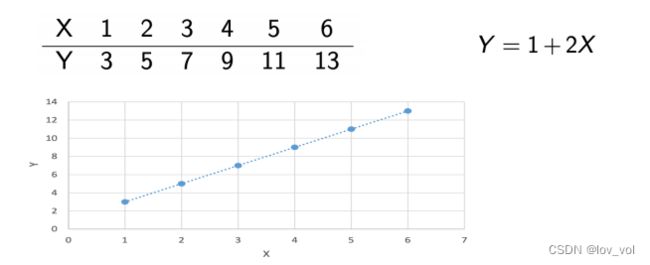
- 线性:然而通常情况下,变量间是近似的线性关系
如下图:
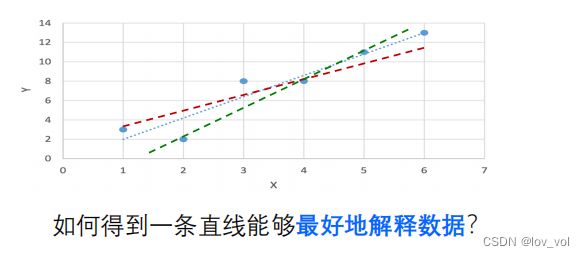
这些点不是线性的,为什么还要进行线性的拟合
- 可能本来是线性的,但是有噪声的扰动,就不是纯线性的
- 确实不是线性的,也不知道背后的规律,但是用线性拟合还不错
如何拟合数据
- 假设只有一个因变量和自变量,每个训练样例表示 ( x i , y i ) (x_i, y_i) (xi,yi)
- 用 y ^ i \hat y_i y^i 表示根据拟合直线和 x i x_i xi 对 y i y_i yi 的预测值
y ^ i = b 1 + b 2 x i \hat y_i= b_1 + b_2 x_i y^i=b1+b2xi
b1是截距,b2是斜率 - 定义 e i = y i − y ^ i e_i = y_i - \hat y_i ei=yi−y^i 为误差项,也叫残差 ϵ \epsilon ϵ
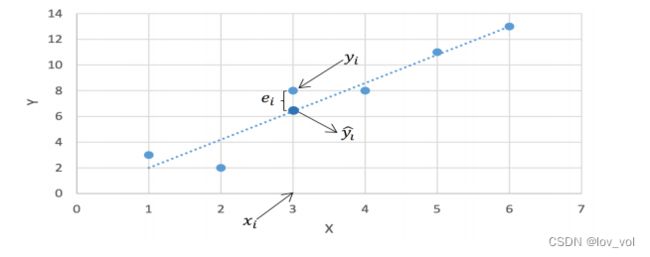
- 目标:得到一条直线使得对于所有训练样例的误差项尽可能小
- (本来是对于所有实例空间,但很难达成,所以就变成是所有训练样例)
线性回归的基本假设
- 自变量与因变量间存在线性关系;
- 数据点之间独立; (相互独立,如y1和y2项户独立,y1和y3相互独立,y1和y3相互独立)
- 自变量之间无共线性,也就是自变量相互独立; (特征是相互独立,如天气和带东西是相互独立,但是天气和带伞不是相互独立的,不建议用)
- 残差(误差项)独立,等方差,且符合正态分布(参考机器学习原则和方法的极限中心定理,)。
- iid(独立同分布得到的数据,如果足够多的话,不管背后是什么分布,叠加后的平均向量(值)也是服从正态分布的),对于同一个问题的误差,我们可以认为是同源的, 如果每个误差是独立来的,噪声足够多的话,那我们可以认为是误差平均向量符合正态分布的, 中心极限定理。
- 独立一般是机器学习数据的基本要求
损失函数(loss function)
- 多种损失函数都是可行的,凭直觉就可以想到:
- 所有误差项的加和 ∑ i = 1 n e i = ∑ i = 1 n ( y i − y ^ i ) \sum_{i=1}^{n} e_i = \sum_{i=1}^{n}(y_i-\hat y_i) ∑i=1nei=∑i=1n(yi−y^i)
- 所有误差项绝对值的加和 ∑ i = 1 n ∣ e i ∣ = ∑ i = 1 n ∣ ( y i − y ^ i ) ∣ \sum_{i=1}^{n}|e_i| = \sum_{i=1}^{n}|(y_i - \hat y_i)| ∑i=1n∣ei∣=∑i=1n∣(yi−y^i)∣
- 考虑到优化等问题,最常用的是基于误差平方和的损失函数
m i n b 1 , b 2 : ∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − b 1 − b 2 x i ) 2 \underset{b_1,b_2}{min}: \sum_{i=1}^{n} e^2_i = \sum_{i=1}^{n}(y_i-\hat y_i)^2 = \sum_{i=1}^{n}(y_i-b_1-b_2x_i)^2 b1,b2min:∑i=1nei2=∑i=1n(yi−y^i)2=∑i=1n(yi−b1−b2xi)2
使用平方和,会把误差缩放, 比如 3 2 = 9 , 0. 1 2 = 0.01 3^2=9, 0.1^2=0.01 32=9,0.12=0.01, 我们一般认为损失大,影响就大,损失小影响就小。
最小二乘法(Least Square, LS)
-
为了求解最优的截距和斜率,可以转化为一个针对损失函数的
凸优化问题,称为最小二乘法
∂ ∑ i = 1 n e i 2 ∂ b 1 = − 2 ∑ i = 1 n ( y i − b 1 − b 2 x i ) = 0 ( 1 ) \frac{\partial \sum_{i=1}^{n} e^2_i}{\partial b_1} = -2\sum_{i=1}^{n}(y_i-b_1-b_2x_i) = 0\ \ \ \ \ \ \ (1) ∂b1∂∑i=1nei2=−2∑i=1n(yi−b1−b2xi)=0 (1)
∂ ∑ i = 1 n e i 2 ∂ b 2 = − 2 ∑ i = 1 n x i ( y i − b 1 − b 2 x i ) = 0 ( 2 ) \frac{\partial \sum_{i=1}^{n} e^2_i}{\partial b_2} = -2\sum_{i=1}^{n}x_i(y_i-b_1-b_2x_i) = 0\ \ \ (2) ∂b2∂∑i=1nei2=−2∑i=1nxi(yi−b1−b2xi)=0 (2) -
求解得到:
b 2 = ∑ i = 1 n ( x i − x ‾ ) ( y i − y ‾ ) ∑ i = 1 n ( x i − x ‾ ) 2 b_2 = \frac{\sum_{i=1}^{n}(x_i-\overline x)(y_i-\overline y)}{\sum_{i=1}^{n}(x_i-\overline x)^2} b2=∑i=1n(xi−x)2∑i=1n(xi−x)(yi−y)
b 1 = y ˉ − b 2 x ˉ b_1 = \bar y - b_2\bar x b1=yˉ−b2xˉ -
x ˉ 和 y ˉ \bar x和\bar y xˉ和yˉ分别表示自变量和因变量的均值
梯度下降法(Gradient Descent,GD)
- 除了最小二乘法,还可以用基于梯度的方法迭代更新截距和斜率
• 梯度下降法- 初始化 b 1 , b 2 b_1,b_2 b1,b2
- (可以随机, 随机不同的值,梯度下降不一样)
- 基于b1,b2就可以预测出 y ^ i \hat y_i y^i, 和真实值yi就可以算出残差(或残差绝对值、平方和)
- 重复:
- b 1 = b 1 − α b_1 = b_1 − \alpha b1=b1−α
- b 2 = b 2 − α b_2 = b_2 − \alpha b2=b2−α
- 基于残差更新b1,b2, α \alpha α就是更新项
- 对比LS:
- ∂ ∑ i = 1 n e i 2 ∂ b 1 \frac{\partial \sum_{i=1}^{n} e^2_i}{\partial b_1} ∂b1∂∑i=1nei2
- ∂ ∑ i = 1 n e i 2 ∂ b 2 \frac{\partial \sum_{i=1}^{n} e^2_i}{\partial b_2} ∂b2∂∑i=1nei2
- 有了新的b1,b2,就可以预测出新的 y ^ \hat y y^,计算新的误差项进行更新
- 初始化 b 1 , b 2 b_1,b_2 b1,b2
回忆西洋跳棋系统设计:
w i ← w i + c ∗ f i ∗ e r r o r ( b ) w_i \leftarrow w_i + c * f_i * error(b) wi←wi+c∗fi∗error(b)
w i w_i wi就是上面的 b 1 b_1 b1,c就是很小的常数项,如0.1, f i f_i fi是第i个数据的特征取值,error(b)就是残差,这里的残差就是本来的,有正有负,来回调整,调整的越来越小
- 梯度下降法也是找的局部最优
多元线性回归(multiple Linear Regression)
- • 当因变量有多个时,我们可以用矩阵方式表达

其实此时: y i = β 0 + β 1 + x i 2 + β 3 x i 3 + . . . . + β k x i k + ϵ i y_i=\beta_0 + \beta_1+x_{i2} + \beta_3x_{i3}+....+ \beta_kx_{ik} + \epsilon_i yi=β0+β1+xi2+β3xi3+....+βkxik+ϵi - 此时的误差项 e = [ e 1 e 2 ⋮ e n ] = y − X β e= \begin{bmatrix} e_1\\ e_2 \\ \vdots\\ e_n \end{bmatrix} =y-X\beta e= e1e2⋮en =y−Xβ
- 损失函数 ∑ i = 1 n e i 2 = e ′ e e ′ 表示转置 ( 线性代数 ) \sum_{i=1}^{n} e^2_i = e'e\ \ \ \ \ \ e'表示转置(线性代数) ∑i=1nei2=e′e e′表示转置(线性代数)
- 求解 ∂ e ′ e ∂ β = − 2 X ′ Y + 2 X ′ X β \frac{\partial e'e}{\partial \beta} = -2X'Y + 2X'X\beta ∂β∂e′e=−2X′Y+2X′Xβ
- 得到 β = ( X ′ X ) − 1 X ′ Y \beta = (X'X)^{-1}X'Y β=(X′X)−1X′Y
2 X ′ X β = 2 X ′ Y 2X'X\beta = 2X'Y 2X′Xβ=2X′Y
X ′ X β = X ′ Y X'X\beta=X'Y X′Xβ=X′Y
( X ′ X ) − 1 X ′ X β = ( X ′ X ) − 1 X ′ Y (X'X)^{-1}X'X\beta = (X'X)^{-1}X'Y (X′X)−1X′Xβ=(X′X)−1X′Y
β = ( X ′ X ) − 1 X ′ Y \beta = (X'X)^{-1}X'Y β=(X′X)−1X′Y
并不是所有的矩阵都有逆矩阵, 所以这里,多元线性回归只有(X‘X)有逆矩阵才可以进行误差项矩阵操作
多元线性回归参数估计的推导(法二)
∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − β 0 − β 1 x x 1 − . . . − β p x i k ) 2 \sum_{i=1}^{n} e^2_i = \sum_{i=1}^{n}(y_i - \beta_0 - \beta_1x_{x1} - ... - \beta_px_{ik})^2 ∑i=1nei2=∑i=1n(yi−β0−β1xx1−...−βpxik)2
对每一个需要估计的参数 β i \beta_i βi求偏导:
∑ ( y i − β 0 − β 1 x x 1 − . . . − β k x i k ) = 0 \sum(y_i - \beta_0 - \beta_1x_{x1} - ... - \beta_kx_{ik}) = 0 ∑(yi−β0−β1xx1−...−βkxik)=0
∑ ( y i − β 0 − β 1 x x 1 − . . . − β k x i k ) x i 1 = 0 \sum(y_i - \beta_0 - \beta_1x_{x1} - ... - \beta_kx_{ik}) x_{i1}= 0 ∑(yi−β0−β1xx1−...−βkxik)xi1=0
…
∑ ( y i − β 0 − β 1 x x 1 − . . . − β k x i k ) x i k = 0 \sum(y_i - \beta_0 - \beta_1x_{x1} - ... - \beta_kx_{ik}) x_{ik}= 0 ∑(yi−β0−β1xx1−...−βkxik)xik=0
( y − X β ) T X = 0 (y-X\beta)^TX = 0 (y−Xβ)TX=0
y T X = β T X T X → X T y = X T X β → b e t a = ( X T X ) − 1 X T y y^TX = \beta^TX^TX \ \ \ \ \ \rightarrow \ \ \ \ \ X^Ty = X^TX\beta\ \ \ \ \ \rightarrow \ \ \ \ beta=(X^TX)^{-1}X^Ty yTX=βTXTX → XTy=XTXβ → beta=(XTX)−1XTy
实例:家庭花销预测
- 记录了 25 个家庭每年在快销品和日常服务上
- 总开销()
- 每年固定收入( 2)、持有的流动资产( 3)
- 可以构建如下线性回归模型
y i = β 1 + β 2 x i 2 + β 3 x i 3 + ϵ i ; i = 1 , . . . , 25 y_i = \beta_1 + \beta_2x_{i2} + \beta_3x_{i3} + \epsilon_i; \ \ \ \ \ i=1,...,25 yi=β1+β2xi2+β3xi3+ϵi; i=1,...,25

- 最终的预测模型为
y ^ i = 36.79 + 0.3318 x i 2 + 0.1258 x i 3 \hat y_i = 36.79 + 0.3318x{i2} + 0.1258x_{i3} y^i=36.79+0.3318xi2+0.1258xi3 - 如果一个家庭每年固定收入为 50K$、持有流动资产 100K$,则
预计一年将会花费
y ^ i = 36.79 + 0.3318 ( 50 ) + 0.1258 ( 100 ) = 65.96 K \hat y_i = 36.79 + 0.3318(50) + 0.1258(100) = 65.96K y^i=36.79+0.3318(50)+0.1258(100)=65.96K$
以“误差平方和”为损失函数的优缺点
- 用误差平方和作为损失函数有很多优点
- 损失函数是严格的凸函数,有唯一解
- 求解过程简单且容易计算
- 同时也伴随着一些缺点
- 结果对数据中的“离群点”(outlier)非常敏感
- 解决方法:提前检测离群点并去除
- 损失函数对于超过和低于真实值的预测是等价的
- 但有些真实情况下二者带来的影响是不同的
- 结果对数据中的“离群点”(outlier)非常敏感
使用线性回归方法, 一般看两点:
- 是否满足线性回归的假设,如线性、独立
- 线性回归的不足对实验影响程度,影响大则不能使用
相关系数与决定系数
- 用来看线性回归拟合的是否足够好
线性回归的相关系数
- 定义因变量和自变量之间的相关系数 r
r = 1 n − 1 ∑ i = 1 n ( x i − x ‾ s x ) ( y i − y ‾ s y ) r=\frac{1}{n-1}\sum_{i=1}^{n}(\frac{x_i-\overline x}{s_x})(\frac{y_i-\overline y}{s_y}) r=n−11∑i=1n(sxxi−x)(syyi−y)
( x i − x ‾ s x ) ( y i − y ‾ s y ) (\frac{x_i-\overline x}{s_x})(\frac{y_i-\overline y}{s_y}) (sxxi−x)(syyi−y)是协方差,描述两个变量 X 和 Y 的线性相关程度
线性相关程度越高,r值越高;线性相关程度越低,r值越低
x ‾ : X 的均值 \overline x: X的均值 x:X的均值
s x : X 的标准差 1 n − 1 ∑ ( x i − x ‾ ) 2 s_x: X的标准差 \sqrt{\frac{1}{n-1}\sum(x_i-\overline x)^2} sx:X的标准差n−11∑(xi−x)2
r可能小于0
r小于0,说明Y和X之间是负相关关系,r>0,正相关
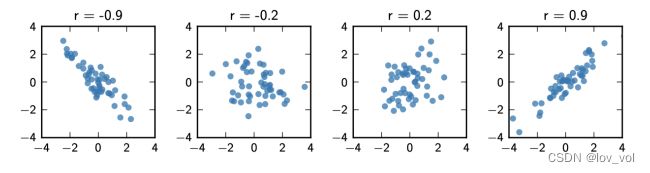
有了训练样例,即所有的x和y, 就可以计算因变量和自变量之间的线性相关程度是不是足够高,如果线性相关不高,那就不一定要用线性回归方法。因为它们本质上不一定是线性回归关系
线性回归的决定系数(coefficient of determination)
- 决定系数 R 2 R^2 R2,也称作判定系数、拟合优度
R 2 = 1 − ∑ i ( y i − y ^ i ) 2 ∑ i ( y i − y ˉ ) 2 y i : 真实值, y ^ i : 预测值, y ˉ 均值 ( 预测值的平均值) R^2 = 1 - \frac{\sum_i(y_i-\hat y_i)^2}{\sum_i(y_i-\bar y)^2}\ \ \ \ \ y_i:真实值,\hat y_i: 预测值,\bar y均值(预测值的平均值) R2=1−∑i(yi−yˉ)2∑i(yi−y^i)2 yi:真实值,y^i:预测值,yˉ均值(预测值的平均值)
R 2 = 1 − ∑ i ( y i − y ^ i ) / n ∑ i ( y i − y ˉ i ) / n = 1 − M S E V A R R^2 = 1-\frac{\sum_i(y_i-\hat y_i)/n}{\sum_i(y_i-\bar y_i)/n}=1-\frac{MSE}{VAR} R2=1−∑i(yi−yˉi)/n∑i(yi−y^i)/n=1−VARMSE
MSE: 均方误差 VAR:方差
M S E V A R \frac{MSE}{VAR} VARMSE是说明由y带来的影响,而 1 − M S E V A R 1-\frac{MSE}{VAR} 1−VARMSE则是x带来的影响 - 注意:有可能<0, R 2 R^2 R2不是 r 2 r^2 r2 ,而是一个值的表示
- 衡量了模型对数据的解释程度
- y的波动有多少百分比能被x的波动所描述
- R 2 R^2 R2越接近1,表示回归分析中自变量对因变量的解释越好
- 特别注意:变量相关 ≠ 存在因果关系
- 如X表示天气, Y表示步行, 有可能相关,但不能说存在因果关系

R2越接近1,说明 M S E V A R \frac{MSE}{VAR} VARMSE越接近0,说明误差( y i − y ^ i y_i-\hat y_i yi−y^i)越接近0, 匹配的越准,所以也叫拟合优度
R2小于0,说明 M S E V A R \frac{MSE}{VAR} VARMSE大于1,说明误差( y i − y ^ i y_i-\hat y_i yi−y^i)比方差还大,
数据挖掘中好多数据有相关,但因果关系需要排除其它控制变量的影响
总结
- 回归分析:描述变量间关系的统计分析方法
- 线性回归:最常用,基本假设
- 基于误差平方和的损失函数
- 最小二乘法
- 梯度下降法
- 扩展到多元线性回归
- 相关系数与决定系数:相关 ≠ 因果