python爬虫之数据解析
前言
python爬虫之数据解析(正则表达式,bs4,xpath)
主要运用在聚焦爬虫模块中,涉及到的数据解析方法有:正则表达式,bs4以及xpath
1.使用对象-聚焦爬虫
聚焦爬虫:爬取页面中指定的页面内容
2.数据解析原理概述
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
3.数据解析流程
【----文中所有学习资料文末免费领!----】
(1)进行指定标签的定位
(2)标签或者标签对应的属性中存储的数据值进行提取(解析)
4.聚焦爬虫编码流程
(1)指定url —> (2) 发起请求 —> (3)获取响应数据 —> (4) 数据解析 —> (5)持久化存储
5.数据解析实现分类
(1)基于正则表达式实现数据解析
(2)基于bs4模块中的Beautiful Soup模块实现数据解析
(3)基于xpath实现数据解析(通用性很强)
5.1 基于正则表达式实现数据解析
补充:常用正则表达式
单字符:
.: 除换行以外所有字符
[] : [a-w]匹配集合中任意一个字符
\d : 匹配数字 [0-9],digital
\D : 匹配非数字
\w : 数字、字母、下划线、中文
\W : 非\w
\s : 所有的空白字符,包括空格、制表符、换页符等等,等价于[\f\n\r\t\v]
\S : 非空白
数量修饰:
* : 任意多次, >= 0
+ : 至少1次, >= 1
? : 可有可无 0次或1次
{m} : 固定m次
{m,}: 至少m次
{m,n}: m-n次
边界:
$ : 以某某结尾
^ : 以某某开头
分组:
(ab)
贪婪模式: .*
非贪婪(惰性)模式:.*?
re.I : 忽略大小写
re.M : 多行匹配
re.S : 单行匹配
re.sub(正则表达式,替换内容,字符串)
编程流程
(1)指定需爬取的网站
(2)分析需获取的数据,如获取图片,某个标签里的文字,某个ID里的数据等
(3)分析需获取的数据获取方式。如在小红书首页中想获取该网页中的某些图片,这些图片是通过发送什么请求获取到的,url是什么,请求方式是什么(get或post等),响应数据是什么类型(text/html或application/javascript等类型)
(4)分析需获取的数据组成方式。如在小红书首页中想获取该网页中的某些图片,这些图片都是由img标签中的src方式获得,且这些img标签前的内容为class为hitv_horizontal的div标签
(5)编写正则表达式,利用正则表达式获取所需数据。以步骤(4)中例子为例,已知需获取图片标签由img标签的src属性获得,且这些img标签前的内容为class为hitv_horizontal的div标签,则可编写如下正则表达式:
ex = '.*?) '
'
(6)引入requests库,对需爬取网站url发起请求,获取该网页上所有数据page_text
(7)引入re库,使用re.findAll()函数对page_text进行正则匹配,获得所需数据
(8)若需保存获得的数据,可将其持久化保存至本地磁盘
eg:
import requests
import re # 使用rs.findAll(),利用正则表达式获取数据
import os # 使用os,在系统中创建文件夹
if __name__ == '__main__':
# 创建一个文件夹,保存所有图片
if not os.path.exists('./images'):
os.mkdir('./images') # 在当前文件夹下创建images文件夹
url = 'xxx.com' # 指定url
headers = {
'User-Agent': '' # 进行UA伪装
}
# 使用通用爬虫对url对应的一整张页面进行爬取
response = requests.get(url=url,headers=headers)
page_text = response.text
# 使用聚焦爬虫将页面中所有的图片进行解析/爬取
ex = '.*?'
img_src_list = re.findall(ex,page_text,re.S)
# re.S 单行匹配,会把换行符提取出来进行每一行的匹配
# re.M 多行匹配,不会进行换行符的提取
for src in img_src_list:
# 注意:获取到图片完整的url地址需加上 https:
src = 'https:' + src
# 请求到了图片的二进制数据(content即为获取到了所求对象的二进制数据的方法)
img_data = requests.get(url=src,headers=headers).content
# 生成图片名称,-1表示获得的数组的最后一位
# 如:src = //pic.qiutubaike.com/system/pictures/test_1.jpg
# 此时的src[-1]表示的就是test_1.jpg
img_name = src.split('/')[-1]
# 图片存储的路径
imgPath = './images/'+img_name
# 将获得的图片二进制数据保存至文件中
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
注意:使用正则表达式解析数据可适用于各种编程语言(如Java等),bs4为python特有的数据解析方式,只适用于python语言
案例:分页爬取某网站图片
案例分析:需爬取的url: https://www.xxx.com/pic/page/%d/?s=5184961 (当前糗事百科已暂停运营,该网址只是作者用来练习随意编写的)
import equests
import re
import os
# 需求:分页爬取某网站下的所有图片
if __name__ == '__main__':
# 创建一个文件夹,保存所有的图片
if not os.path.exits('./images'):
os.mkdir('./images')
# 设置一个通用的url模板
url = 'https://www.xxx.com/pic/page/%d/?s=5184961'
headers = {
'User-Agent': '', # 进行UA伪装
}
# 设置页数
pageNum = 1
for pageNum in range(1,40):
# 对应页码的url,如第一页的url:https://www.xxx.com/pic/page/1/?s=5184961
new_url = format(url%pageNum)
# 使用通用爬虫获取指定页面的数据
page_text = requests.get(url=new_url,headers=headers)
# 使用聚焦爬虫将页面中所有的图片进行解析/爬取
ex = '.*?'
img_src_list = re.findAll(ex,page_text,re.S)
for src in img_src_list:
# 请求到了图片的二进制数据
img_data = requests.get(url=url,headers=headers).content
img_name = src.split('/')[-1]
# 图片存储的路径
imgPath = './images/'+img_name
# 将获得的图片二进制数据保存至文件中
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
5.2 基于bs4实现数据解析
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
BeautifulSoup是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。
5.2.1 数据解析原理
(1)标签定位 (2)提取标签或标签属性中存储的数据值
5.2.2 bs4数据解析的原理
(1)实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
(2)通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取(提取标签或标签属性中存储的数据值)
5.2.3 编程流程
(1)环境安装
pip install bs4
pip install lxml # bs4在使用时需要一个第三方库lxml
注意:若bs4安装失败,可能是python的pip源设置问题,解决方法如下:
此时需要将pip源设置为国内源(阿里源、豆瓣源、网易源等)
若为Windows系统,则:
① 打开文件资源管理器(文件夹地址栏中)
② 地址栏上输入 %appdata%
③ 在这里面新建一个文件夹 pip
④ 在pip文件夹里面新建一个文件叫做 pip.ini,内容如下即可:
[global]
timeout = 6000
index-url = https://mirrors.aliyun.com/pypi/simple/
trusted-host = mirrors.aliyun.com
若为Linux系统,则需键入如下命令:
① cd ~
② mkdir ~/.pip
③ vi ~/.pip/pip.conf
④ 编辑内容,和Windows一模一样
(2)如何实例化BeautifulSoup对象?
① 导包:from bs4 import BeautifulSoup
② 对象的实例化:
i. 将本地的html文档中的数据加载到该对象中(BeautifulSoup对象)
fp = open('./test.html','r',encoding='utf-8')
# BeautifulSoup对象的构造方法有两个参数,第一个参数表示需传数据的文档文件,第二个参数为固定值,即lxml,表示BeautifulSoup对象使用lxml对获取的数据进行解析
# 这里的soup对象即为将本地中的test.html文档中的数据传入到soup对象中,并将其进行数据解析获得的对象
soup = BeautifulSoup(fp,'lxml')
ii. 将互联网上获取的页面源码加载到该对象中(BeautifulSoup对象),此方法使用次数较为频繁,相比第一种更为便捷
page_text = response.text
soup = BeautifulSoup(page_text,'lxml')
③ BeautifulSoup提供的用于数据解析的方法和属性:
i. soup.tagName: 返回的是文档中第一次出现的tagName对应的标签
# 如:
print(soup.div) # 返回的是文档中第一次出现的div标签
ii. soup.find():
-
find(‘tagName’): 等同于soup.tagName,返回的是文档中第一次出现的tagName对应的标签
-
属性定位:根据标签的属性定位到需要找到的标签数据
# 如: print(soup.find('div',class_='song')) # 注意:soup.find()函数中的第一个参数为标签名,第二个参数为需找标签的属性,如类名、ID、attr等 # 注意:若第二个参数为需找标签的类名,则参数名需写为 class_,必须加'_',class为python里的关键字 # 此例中,控制台会输出类名为"song"的div的相关数据 # 即: -
soup.find_all(‘tagName’): 返回符合要求的所有标签(列表)
iii. soup.select():
-
select(‘某种选择器(id,class,标签…选择器)’),返回的是一个列表
// 为更好理解soup的select方法,以下网页源码为素材# 以上面页面的源码为例,想选择类名为tang的div print(soup.select('.tang')) # 会输出以上源码的所有内容 print(soup.select('.tang > ul > li > a'))[0] # 表示类名为tang元素的后代子元素中的第一个a标签元素,即 清明时节雨纷纷,路上行人欲断魂 -
层级选择器:
# 输出以上源码中类名为tang的div下的所有a标签元素 print(soup.select('.tang > ul > li > a')) # >表示的是一个层级 print(soup.select('.tang > ul a')) # 空格表示的是多个层级 # 注意:这里的select类似CSS语法里的后代选择器,第一个’>‘表示元素的子元素,第二个表示元素的所有元素中满足要求的元素
(3)获取数据
① 获取标签之间的文本数据:
-
方法:soup.元素.text/string/get_text()
-
各个方法之间的区别:
-
text/get_text():可以获取某一个标签中**所有的文本内容**。
-
string:只可以获取该标签下面**直系文本**的文本内容。
# 以上述网页源码为例 # 会输出div中的所有文本,即: 清明时节雨纷纷,路上行人欲断魂;秦时明月汉时关,万里长征人未还;岐王宅里寻常见,崔九堂前几度闻;杜甫;杜牧;杜小月;度蜜月;凤凰台上凤凰游,凤去台空江自流 print(soup.div.text) # 会输出b标签中的直系文本的文本内容:杜小月 print(soup.b.text)
-
② 获取标签中属性值:
方法:soup.元素[属性名]
# 如,想获取a标签元素的href属性值
print(soup.select('.tang > ul > li > a')[0]['href'])
# 会输出 http://www.baidu.com
5.2.4 案例
# 需求:爬取小说网址的某篇书籍章节以及对应章节内容
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 本次练习为爬取笔趣阁网站下的某篇书籍章节内容
# 1.指定需爬取的网站url
url = "https://www.bbiquge.net/book/59265/"
# 进行UA伪装
headers = {
'User-Agent': ''
}
# 2.进行首页数据爬取
for page in range(1,3):
n_url = url + 'index_' + str(page) + '.html'
index_text = requests.get(url=n_url,headers=headers).text
# 3.获取章节标题
# 在首页中获取需解析的章节的文本数据和章节内容的url
# (1)创建BeautifulSoup对象
soup = BeautifulSoup(index_text,'lxml')
# (2)找到包含章节内容的元素
dd_list = soup.select('.zjbox > .zjlist > dd')
# (3)依次解析章节内容里的a链接的href属性,并将获得的url发送请求,获得对应章节内容
# 创建文本文件对象,将内容持久化保存
fp = open('data/xiaoshuo.txt','w',encoding='utf-8')
for dd in dd_list:
# 获得章节标题
title = dd.string
# 获得对应章节内容
new_url = url + dd.a['href']
# 发起请求,获得章节内容网页
detail_text = requests.get(url=new_url,headers=headers).text
# 创建新的soup对象,获取章节内容
detail_soup = BeautifulSoup(detail_text,'lxml')
detail_page_text = detail_soup.find('div',id='readbox').text
fp.write(title + '\n\n\n\n')
fp.write(detail_page_text)
fp.write('\n\n\n')
print(title,'爬取成功!!!')
案例分析:
(1)每一章的章节标题均在类名为 “zjbox”的div下的类名为 “zjlist” 的dl下的自定义列表dd里,故需先找到对应的dd元素
(2)每一章的对应章节内容需从服务器向浏览器发送url 为dd元素下的a链接(方便起见,暂时将其命名为章节内容页面),在获取章节内容里的完整数据中进行进一步数据解析
(3)更具体完整的数据包含在章节内容页面里的ID名为 “readbox”的div的文本数据,故需先获取包含完整章节内容的元素,在获取其对应的文本数据即可。
5.3 基于xpath实现数据解析
5.3.1 xpath简介
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索,是最通用也最常用的一种解析方式,可适用于各种语言进行数据爬取,通用性很强。
5.3.2 xpath解析原理
(1)实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
(2)调用etree对象中的xpath方法,结合**xpath表达式**实现标签的定位和内容的捕获(即获取标签或标签属性的存储的数据值)
5.3.3 编程流程
(1)环境的安装
pip install lxml # lxml是一个解析器
(2)实例化一个etree对象:
from lxml import etree
-
将本地的html文档中的源码数据加载到etree对象中:
etree.parse(filePath) # filePath为本地html文档的路径 -
可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text') # page_text为从互联网上获取的源码数据
(3)调用xpath的方法
xpath.('xpath表达式')
(3.1)xpath表达式解析
-
/: 表示的是从根节点开始定位。一个 / 表示的是一个层级。
-
//: 表示的是多个层级。可以表示从任意位置开始定位。
-
属性定位://div[@class=‘song’] 即,tag[@attrName=“attrValue”]
-
索引定位://div[@class=‘song’]/p[3] 注意:索引是从1开始的。
-
取标签存储的文本信息:
- /text() 获取的是标签中直系的文本内容
- // text() 获取的是标签中非直系的文本内容(所有的文本内容)
-
取标签的属性值:
- /@attrName 如,想获取img标签下的src属性值,则xpath表达式为:/img/@src
5.3.4 案例
# 新版本的lxml不可直接调用etree,需先引入html,在令etree = html.etree即可
from lxml import html
if __name__ == '__main__':
# 实例化一个etree对象,且将被解析的源码加载到该对象中
etree = html.etree
tree = etree.parse('test.html')
# 根据层级关系定位到所需标签,第一个 / 表示从原网页的根节点出发(即网页中的第一个标签,通常为)
# 其中,/ 表示从根节点开始定位,一个 / 表示一个层级
# 注意,xpath表达式只能根据层级定位进行标签的定位
# xpath的方法返回的是定位到包含标签元素信息的类型为Element的列表
# r = tree.xpath('/html/head/title')
# tree.xpath('//div')表示的是定位到网页中所有的div标签元素
# r = tree.xpath('//div')
# r = tree.xpath('/html//div')
# 想获取到类名为 song 的div元素
# r = tree.xpath('//div[@class="song"]')
# 想获取到类名为 song 的div元素下的第三个 p 标签元素,注意此时索引是从1开始的
# r = tree.xpath('//div[@class="song"]/p[3]')
# ----------------------
# 获取标签元素的文本信息
# 想获取类名为 tang 的div标签下的内容为 杜牧 的a标签元素,注意若不加[0]则表示的是列表值,想要获取字符串形式的文本内容,直接加索引即可,此时的索引是从0开始
# r = tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]
# 想获取类名为 tang 的div标签下的所有文本内容
# r = tree.xpath('//div[@class="tang"]//text()')
# ----------------------
# 获取标签元素下的属性值
# 获取类名为 song 的div标签下的img标签的src属性值
r = tree.xpath('//div[@class="song"]/img/@src')
print(r)
案例一:爬取58同城二手房标题数据
# 需求:爬取58二手房的房源信息
import requests
from lxml import etree
if __name__ == '__main__':
# UA伪装
headers = {
'User-Agent': ''
}
# 指定网站url
url = "https://bj.58.com/ershoufang/"
# 爬取页面源码数据
page_text = requests.get(url=url,headers=headers).text
# 创建文本文件
fp = open("../data/二手房数据.txt",'w',encoding="utf-8")
# 数据解析
# 1.实例化etree对象
tree = etree.HTML(page_text)
# 2.获取数据
div_list = tree.xpath('//div[@class="property"]')
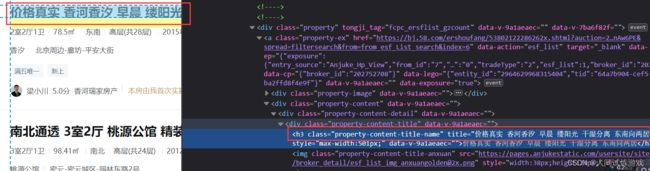
for div in div_list:
detail_text = div.xpath('.//div[@class="property-content-title"]/h3/@title')[0]
# detail_text = div.xpath('./a/div[2]/div[@class="property-content-title"]/h3/@title')
# 持久化保存二手房标题
# print(detail_text)
fp.write(detail_text+'\n')
print('保存成功!!!')
网页数据标签层级解析:

案例二:爬取昵图网的茶文化图片
# 需求:解析下载图片数据 https://www.nipic.com/topic/show_27246_1.html
import requests
from lxml import etree
if __name__ == "__main__":
# 1.爬取网页数据
url = "https://www.nipic.com/topic/show_27246_1.html"
headers = {
'User-Agent': ''
}
# 手动设定响应数据的编码格式
# response = requests.get(url=url,headers=headers)
# response.encoding = 'utf-8'
# page_text = response.text
page_text = requests.get(url=url,headers=headers).text
# 2.数据解析
tree = etree.HTML(page_text)
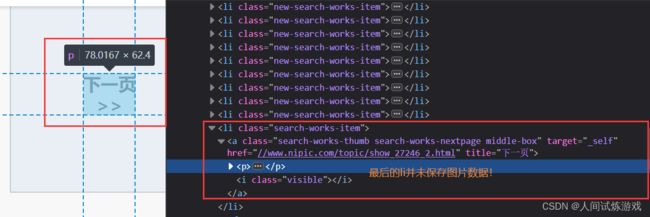
# 注意网页中的最后一个li存储的是下一页,并未存储图片信息
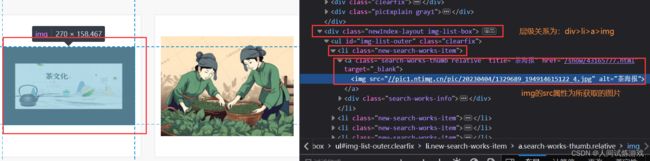
li_list = tree.xpath('//div[@class="newIndex-layout img-list-box"]/ul/li[@class="new-search-works-item"]')
for li in li_list:
text = li.xpath('./a/img/@src')[0]
new_url = 'https:' + text
# 生成图片名称
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# 注意:若中文乱码,可先在获取网页数据时,手动设置响应数据的编码格式,即本代码中的第15行
# 若手动设置响应数据的编码格式后仍不能解决中文乱码问题,可在出现中文乱码的位置修改设置
# 此方法为通用的解决中文乱码问题的方法
# 假设此时中文乱码发生在img_name,则需在获得img_name后手动加一行代码,即
# img_name = img_name.encode('iso-8859-1').decode('gbk')
img_data = requests.get(url=new_url,headers=headers).content
# 图片存储路径
img_path = '../data/壁纸img/' + img_name
# 将获得的图片二进制数据保存至文件中
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!!')
网页图片数据层级解析:
 注意最后一个li并未保存图片信息
注意最后一个li并未保存图片信息
注意:xpath表达式也可使用或运算符
如:a_list = tree.xpath(‘//div[@class=“bottom”]/ul/li/a | //div[@class=“bottom”]/ul/div[2]/li/a’ )
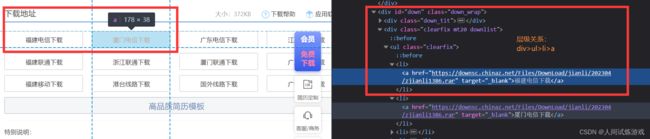
案例三:爬取站长素材页面的免费简历模板
# 需求:爬取站长素材中免费简历模板
import requests
from lxml import etree
import os
# 解析:
# 1.先获取站长素材中免费简历页面源码数据
# 2.对获取的站长素材免费简历页面数据进行数据解析,获取每个免费简历的a链接的href属性
# 3.对获取的a链接的href属性发起请求,获得简历下载页面的源码数据
# 4.对简历下载页面进行数据解析,获得下载简历的a链接的href属性
# 5.对获得的下载简历的a链接发起请求,获得对应的二进制数据,将其进行保存
# 6.隐藏任务:可进行分页操作
if __name__ == '__main__':
# 进行分页操作
# 第一页的url : https://sc.chinaz.com/jianli/free.html
# 后几页的url : https://sc.chinaz.com/jianli/free_2.html
headers = {
'User-Agent': ''
}
for page in range(1,6):
# 1.先获取站长素材中免费简历页面源码数据
if page == 1:
url = 'https://sc.chinaz.com/jianli/free.html'
else:
url = 'https://sc.chinaz.com/jianli/free_' + str(page) + '.html'
# 防止中文乱码
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
# 2.对获取的站长素材免费简历页面数据进行数据解析,获取每个免费简历的a链接的href属性
tree = etree.HTML(page_text)
# 注意:网页源码数据中所找的div类名后并未有 masonry-brick
# div_list = tree.xpath('//div[@class="sc_warp mt20"]/div[@class="box col3 ws_block masonry-brick"]')
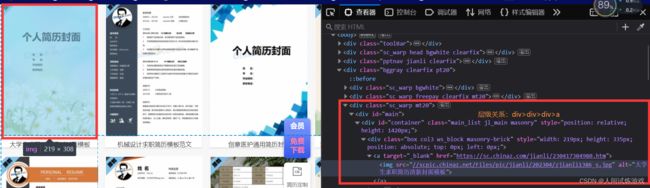
div_list = tree.xpath('//div[@class="main_list jl_main"]/div[@class="box col3 ws_block"]')
# 创建下载简历的文件夹
if not os.path.exists('../data/简历'):
os.mkdir('../data/简历')
for div in div_list:
a_url = div.xpath('./a/@href')[0]
# 生成简历名称
resourse_name = div.xpath('./a/img/@alt')[0] + '.rar'
# 3.对获取的a链接的href属性发起请求,获得简历下载页面的源码数据
detail_page_text = requests.get(url=a_url,headers=headers).text
# 4.对简历下载页面进行数据解析,获得下载简历的a链接的href属性
detail_tree = etree.HTML(detail_page_text)
detail_url = detail_tree.xpath('//div[@class="down_wrap"]/div[@class="clearfix mt20 downlist"]/ul/li[1]/a/@href')[0]
# 5.对获得的下载简历的a链接发起请求,获得对应的二进制数据,将其进行保存
resourse_data = requests.get(url=detail_url,headers=headers).content
resorse_path = '../data/简历/' + resourse_name
with open(resorse_path,'wb') as fp:
fp.write(resourse_data)
print(resourse_name,'下载成功!!!')
网页数据层级分析:
读者福利:如果大家对Python感兴趣,这套python学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
④ 20款主流手游迫解 爬虫手游逆行迫解教程包
⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
⑦ 超300本Python电子好书,从入门到高阶应有尽有
⑧ 华为出品独家Python漫画教程,手机也能学习
⑨ 历年互联网企业Python面试真题,复习时非常方便
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。
面试刷题



资料领取
上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓

好文推荐
了解python的前景:https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835
了解python的兼职副业:https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603