【NLP】第10章 使用基于 BERT 的 Transformer 进行语义角色标记
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
Transformers 在过去几年里取得的进步比上一代 NLP 还要多。标准 NLU 方法首先学习句法和词汇特征来解释句子的结构。在运行语义角色标签( SRL )之前,将训练以前的 NLP 模型理解语言的基本语法。
Shi和Lin(2019)在他们的论文开始时询问是否可以跳过初步的句法和词汇训练。基于 BERT 的模型可以在不经过那些经典训练阶段的情况下执行 SRL 吗?答案是肯定的!
Shi和Lin (2019) 建议 SRL 可以被视为序列标记并提供标准化的输入格式。他们基于 BERT 的模型产生了令人惊讶的好结果。
本章将使用 Allen Institute for AI 根据Shi and Lin (2019) 论文提供的基于 BERT 的预训练模型。Shi和Lin通过放弃句法和词汇训练将 SRL 提升到一个新的水平。我们将看到这是如何实现的。
我们将从定义 SRL 和序列标记输入格式的标准化开始。然后,我们将开始使用艾伦人工智能研究所提供的资源。接下来,我们将在 Google Colab 笔记本中运行 SRL 任务,并使用在线资源来了解结果。
最后,我们将通过运行 SRL 样本来挑战基于 BERT 的模型。第一个示例将展示 SRL 的工作原理。然后,我们将运行一些更困难的样本。我们将逐步将基于 BERT 的模型推向 SRL 的极限。找到模型的极限是确保 Transformer 模型在现实生活中的实现保持现实和务实的最佳方式。
本章涵盖以下主题:
- 定义语义角色标签
- 定义 SRL 输入格式的标准化
- 基于 BERT 的模型架构的主要方面
- 仅编码器堆栈如何管理屏蔽的 SRL 输入格式
- 基于 BERT 的模型 SRL 注意力过程
- 艾伦人工智能研究所提供的资源入门
- 构建笔记本以运行基于 BERT 的预训练模型
- 在基本示例上测试句子标签
- 在困难的例子上测试 SRL 并解释结果
- 将基于 BERT 的模型发挥到 SRL 的极限并解释这是如何完成的
我们的第一步将是探索Shi和Lin (2019) 定义的 SRL 方法。
SRL 入门
SRL 对人类和机器一样困难。然而,变压器又一次采取了更接近我们的人类基线。
在本节中,我们将首先定义 SRL 并可视化一个示例。然后,我们将运行一个预训练的基于 BERT 的模型。
让我们从定义 SRL 的有问题的任务开始。
定义语义角色标签
Shi and Lin (2019) 提出并证明了我们可以找到谁做了什么,在哪里做了什么,而无需取决于词汇或句法特征。本章基于Peng Shi和Jimmy Lin在加州滑铁卢大学的研究。他们展示了转换器如何通过注意力层更好地学习语言结构。
SRL 将语义角色标记为一个词或一组词在句子中所扮演的角色以及与谓词建立的关系。
语义角色是名词或名词短语相对于句子中的主要动词所起的作用。例如,在句子中Marvin walked in the park,Marvin是句子中发生的事件的代理。代理是事件的执行者。主要动词或支配动词是walked。
谓词描述了有关主题或代理的某些内容。谓词可以是任何提供有关主题的特征或动作的信息的东西。在我们的方法中,我们将指谓语为主要动词。例如,在句子Marvin walked in the park中,谓词是walked受限形式。
词in the park 修饰walked和 是修饰语 的意思。
围绕谓词旋转的名词或名词短语是论据或论据项。Marvin例如,是谓词的一个参数。 walked
我们可以看到 SRL 不需要语法树或词法分析。
让我们可视化我们示例的 SRL。
可视化 SRL
本章将使用 Allen Institute 的视觉和代码资源(有关更多信息,请参阅参考资料部分)。艾伦人工智能研究所具有出色的互动性在线工具,例如我们的工具用于在本章中直观地表示 SRL。您可以在https://demo.allennlp.org/访问这些工具。
艾伦人工智能研究所提倡人工智能是为了共同利益。我们会很好地利用这种方法。本章中的所有图形都是使用 AllenNLP 工具创建的。
艾伦研究所提供不断发展的变压器模型。因此,本章中的示例在运行时可能会产生不同的结果。充分利用本章的最佳方法是:
- 阅读并理解除了运行程序之外所解释的概念
- 花时间了解所提供的示例
然后运行使用本章中使用的工具对您选择的句子进行自己的实验:https ://demo.allennlp.org/semantic-role-labeling 。
我们现在将可视化我们的 SRL 示例。图 10.1是 SRL 表示Marvin walked in the park:
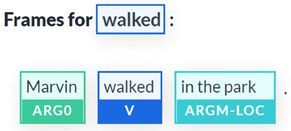
图 10.1:句子的 SRL 表示
我们可以请注意图 10.1中的以下标签:
- 动词:句子的谓词
- Argument : 名为ARG0的句子的一个参数
- 修饰语:句子的修饰语。在这种情况下,一个位置。它可以是副词、形容词或任何修饰谓词含义的东西
文本输出也很有趣,其中包含视觉表示标签的较短版本:
walked: [ARG0: Marvin] [V: walked] [ARGM-LOC: in the park]我们已经定义了 SRL 并通过了一个例子。是时候看看基于 BERT 的模型了。
运行基于 BERT 的预训练模型
这个部分将开始描述本章中使用的基于 BERT 的模型的架构。
然后我们将定义用于使用 BERT 模型对 SRL 样本进行实验的方法。
让我们先看看基于 BERT 的模型的架构。
基于 BERT 的模型的架构
AllenNLP 基于 BERT 的模型是一个 12 层的仅编码器 BERT 模型。AllenNLP 团队使用附加的线性分类层实现了Shi和Lin (2019)中描述的 BERT 模型。
有关 BERT 模型描述的更多信息,如有必要,请花几分钟时间返回第 3 章,微调 BERT 模型。
基于 BERT 的模型通过简单的方法和架构充分利用了双向注意力。Transformer 的核心潜力在于注意力层。我们已经看到了带有编码器和解码器堆栈的转换器模型。我们已经看到其他仅具有编码器层或仅具有解码器层的转换器。Transformer 的主要优势仍然在于注意力层的接近人类的方法。
Shi and Lin (2019)定义的谓词识别格式的输入格式显示了转换器以标准化方式理解语言的程度:
[CLS] Marvin walked in the park.[SEP] walked [SEP]培训流程已标准化:
[CLS]表示这是一个分类练习[SEP]是第一个分隔符,表示句子的结尾[SEP]后面是作者设计的谓词识别[SEP]是第二个分隔符,表示谓词标识符的结束
仅这种格式就足以训练 BERT 模型来识别和标记句子中的语义角色。
让我们设置运行 SRL 示例的环境。
设置 BERT SRL 环境
我们将使用 Google Colab 笔记本,可在AllenNLP - Demo的语义角色标签部分下找到 SRL 的 AllenNLP 视觉文本表示。
我们将应用以下方法:
- 我们将打开
SRL.ipynb、安装AllenNLP和运行每个示例 - 我们将显示 SRL 运行的原始输出
- 我们将使用 AllenNLP 的在线可视化工具可视化输出
- 我们将使用 AllenNLP 的在线文本可视化工具显示输出
本章自成一体。您可以通读它或按照描述运行示例。
当 AllenNLP 更改使用的变压器模型时,SRL 模型输出可能会有所不同。这是因为 AllenNLP 模型和转换器通常是不断训练和更新的。此外,用于训练的数据集可能会发生变化。最后,这些不是每次都产生相同结果的基于规则的算法。如屏幕截图中所述和所示,输出可能会从一次运行更改为另一次运行。
现在让我们进行一些 SRL 实验。
使用基于 BERT 的模型进行 SRL 实验
我们将使用本章设置 BERT SRL 环境部分中描述的方法运行我们的 SRL 实验。我们将从带有各种句子的基本样本开始结构。然后我们将挑战基于 BERT 的模型带有一些更难的样本来探索系统的容量和限制。
打开SRL.ipynb并运行安装单元:
!pip install allennlp==2.1.0 allennlp-models==2.1.0然后我们导入标记模块和经过训练的 BERT 预测器:
from allennlp.predictors.predictor import Predictor
import allennlp_models.tagging
import json
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/structured-prediction-srl-bert.2020.12.15.tar.gz")我们还添加了两个函数来显示 SRL BERT 返回的 JSON 对象。第一个显示谓词的动词和描述:
def head(prediction):
# Iterating through the json to display excerpt of the prediciton
for i in prediction['verbs']:
print('Verb:',i['verb'],i['description'])第二个显示完整的响应,包括标签:
def full(prediction):
#print the full prediction
print(json.dumps(prediction, indent = 1, sort_keys=True))在本文发布时间,BERT模型是专门为语义角色标签使用而训练的。该模型的名称是 SRL BERT。SRL BERT 使用OntoNotes 5.0 数据集:https ://catalog.ldc.upenn.edu/LDC2013T19 。
该数据集包含句子和注释。该数据集旨在识别句子中的谓词(包含动词的句子的一部分),并识别提供有关动词的更多信息的单词。每个动词都带有它的“参数”,可以告诉我们更多关于它的信息。“框架”包含动词的参数。
因此,SRL BERT 是经过训练以执行特定任务的专用模型,因此,它不是像我们在第 7 章“使用 GPT-3 引擎的超人变形金刚的崛起”中看到的 OpenAI GPT-3 那样的基础模型。
只要句子包含谓词,SRL BERT 将专注于以可接受的准确性进行语义角色标记。
我们现在准备好用一些基本样本来热身。
基本样本
基本样本看起来很简单,但分析起来却很棘手。复合句、形容词、副词和情态词很难识别,即使对于非专业人士也是如此。
让我们从一个简单的变压器示例开始。
样品 1
首先样本很长,但对变压器来说相对容易:
Did Bob really think he could prepare a meal for 50 people in only a few hours?
运行样本 1中的单元格SRL.ipynb:
prediction=predictor.predict(
sentence="Did Bob really think he could prepare a meal for 50 people in only a few hours?"
)
head(prediction)BERT SRL 识别了四个谓词;每个动词的动词使用以下head(prediction)函数标记结果,如本节选所示:
Verb: Did [V: Did] Bob really think he could prepare a meal for 50 people in only a few hours ?
Verb: think Did [ARG0: Bob] [ARGM-ADV: really] [V: think] [ARG1: he could prepare a meal for 50 people in only a few hours] ?
Verb: could Did Bob really think he [V: could] [ARG1: prepare a meal for 50 people in only a few hours] ?
Verb: prepare Did Bob really think [ARG0: he] [ARGM-MOD: could] [V: prepare] [ARG1: a meal for 50 people] [ARGM-TMP: in only a few hours] ?您可以通过运行单元格来查看完整响应full(prediction)。
如果我们使用基于 PropBank(命题库)结构的数据集参数的描述,think例如这个节选中的动词 可以解释为:
V识别动词thinkARG0识别代理;因此,Bob是代理人还是“亲代理人”ARGM-ADV认为really是副词 (ADV),ARGM意思是副词提供了一个附加词(不是必需的),因此没有编号
如果我们在 AllenNLP 在线界面中运行示例,我们将获得每个动词一帧的 SRL 任务的可视化表示。第一个动词是Did:
 图 10.2:识别动词“Did”
图 10.2:识别动词“Did”
第二确定的动词是think:

图 10.3:识别动词“think”
如果我们仔细观察这个表示,我们可以发现 SRL BERT 的一些有趣的属性:
- 检测到动词
think prepare避免了可能被解释为主要动词的陷阱。相反,prepare仍然是论点的一部分think- 检测到一个副词并将其标记
第三个动词是could:
 图 10.4:识别动词“could”和论点
图 10.4:识别动词“could”和论点
变压器然后移动到动词prepare,标记它,并分析它的上下文:
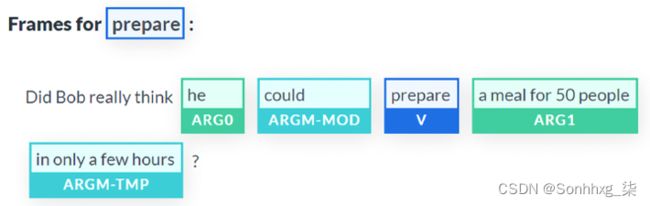 图 10.5:识别动词“prepare”、论据和修饰语
图 10.5:识别动词“prepare”、论据和修饰语
再次,简单的基于 BERT 的 Transformer 模型检测到很多关于句子语法结构的信息,发现:
- 动词
prepare和孤立它 - 名词
he并将其标记为一个论点,并为 做同样的事情a meal for 50 people,这是一个“原始患者”,其中涉及其他参与者的修改 - 那
in only a few hours是一个时间修饰符(ARGM-TMP) - 那
could是一个情态修饰语,表示动词的情态,例如事件的可能性
我们现在将分析另一个相对较长的句子。
样品 2
以下句子看起来很简单,但包含几个动词:
Mrs. and Mr. Tomaso went to Europe for vacation and visited Paris and first went to visit the Eiffel Tower.
这会令人困惑的句子让变压器犹豫不决?让我们通过运行笔记本的Sample 2单元来查看:SRL.ipynb
prediction=predictor.predict(
sentence="Mrs. and Mr. Tomaso went to Europe for vacation and visited Paris and first went to visit the Eiffel Tower."
)
head(prediction)输出的摘录证明了转换器正确识别了句子中的动词:
Verb: went [ARG0: Mrs. and Mr. Tomaso] [V: went] [ARG4: to Europe] [ARGM-PRP: for vacation] and visited Paris and first went to visit the Eiffel Tower .
Verb: visited [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and [V: visited] [ARG1: Paris] and first went to visit the Eiffel Tower .
Verb: went [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and visited Paris and [ARGM-TMP: first] [V: went] [ARG1: to visit the Eiffel Tower] .
Verb: visit [ARG0: Mrs. and Mr. Tomaso] went to Europe for vacation and visited Paris and first went to [V: visit] [ARG1: the Eiffel Tower] .在 AllenNLP online 上运行样本识别了四个谓词,从而生成了四个帧。
第一帧用于went:

图 10.6:识别动词“went”、论据和修饰语
我们可以解释动词的论点went。Mrs. and Mr. Tomaso是代理。变压器发现动词的主要修饰语是旅行的目的:to Europe. 如果我们不知道Shi和Lin (2019) 只是建立了一个简单的 BERT 模型来获得这种高质量的语法分析,结果也就不足为奇了。
我们还可以注意到 与went正确关联Europe。visited转换器正确地识别出与以下相关的动词Paris:

图 10.7:识别动词“visited”和论据
转换器可以将动词visited直接与Eiffel Tower. 但它没有。它坚持自己的立场并做出了正确的决定。
我们要求转换器做的下一个任务是识别动词第二次使用的上下文went。同样,它没有落入合并所有与动词相关的论点的陷阱,went在句子中使用了两次。同样,它正确地拆分了序列并产生了出色的结果:
 图 10.8:识别动词“went”、论据和修饰语
图 10.8:识别动词“went”、论据和修饰语
动词went用了两次,但变形金刚没有落入陷阱。它甚至发现那first是动词的时间修饰语went。
最后,动词visit被第二次使用,SRL BERT 正确解释了它的用法:
 图 10.9:识别动词“visit”和论据
图 10.9:识别动词“visit”和论据
让我们运行一个更令人困惑的句子。
样品 3
样品 3将使对于我们的变压器模型来说,事情变得更加困难。以下示例包含drink四次动词变体:
John wanted to drink tea, Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice.
让我们在笔记本中运行示例 3 :SRL.ipynb
prediction=predictor.predict(
sentence="John wanted to drink tea, Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice."
)
head(prediction)变压器找到了它的方式,如以下包含动词的输出摘录所示:
Verb: wanted [ARG0: John] [V: wanted] [ARG1: to drink tea] , Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drink [ARG0: John] wanted to [V: drink] [ARG1: tea] , Mary likes to drink coffee but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: likes John wanted to drink tea , [ARG0: Mary] [V: likes] [ARG1: to drink coffee] but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drink John wanted to drink tea , [ARG0: Mary] likes to [V: drink] [ARG1: coffee] but Karim drank some cool water and Faiza would like to drink tomato juice .
Verb: drank John wanted to drink tea , Mary likes to drink coffee but [ARG0: Karim] [V: drank] [ARG1: some cool water] and Faiza would like to drink tomato juice .
Verb: would John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] [V: would] like [ARG1: to drink tomato juice] .
Verb: like John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] [ARGM-MOD: would] [V: like] [ARG1: to drink tomato juice] .
Verb: drink John wanted to drink tea , Mary likes to drink coffee but Karim drank some cool water and [ARG0: Faiza] would like to [V: drink] [ARG1: tomato juice] .当我们在 AllenNLP 在线界面上运行句子时,我们获得了几个视觉表示。我们将研究其中的两个。
第一个是完美的。它识别动词wanted并做出正确的关联:

图 10.10:识别动词“wanted”和论据
当它识别了动词drank,它正确地排除Faiza并仅some cool water作为参数产生。

图 10.11:识别动词“drank”和论据
我们发现,到目前为止,基于 BERT 的转换器在基本样本上产生了相对较好的结果。所以让我们尝试一些更困难的。
困难样品
本节将运行包含基于 BERT 的转换器将首先解决的问题的样本。最后,我们将以一个棘手的样本结束。
让我们从一个基于 BERT 的变压器可以分析的复杂样本开始。
样品 4
示例 4将我们带入更棘手的 SRL 领域。样本Alice从动词中分离出来liked,创建了一个必须跳过的长期依赖关系whose husband went jogging every Sunday.
句子是:
Alice, whose husband went jogging every Sunday, liked to go to a dancing class in the meantime.
人类可以分离Alice并找到谓词:
Alice liked to go to a dancing class in the meantime.
可以BERT 模型找到像我们一样的谓词?
让我们通过首先运行以下代码来找出答案SRL.ipynb:
prediction=predictor.predict(
sentence="Alice, whose husband went jogging every Sunday, liked to go to a dancing class in the meantime."
)
head(prediction)输出识别每个谓词的动词并标记每个帧:
Verb: went Alice , [ARG0: whose husband] [V: went] [ARG1: jogging] [ARGM-TMP: every Sunday] , liked to go to a dancing class in the meantime .
Verb: jogging Alice , [ARG0: whose husband] went [V: jogging] [ARGM-TMP: every Sunday] , liked to go to a dancing class in the meantime .
Verb: liked [ARG0: Alice , whose husband went jogging every Sunday] , [V: liked] [ARG1: to go to a dancing class in the meantime] .
Verb: go [ARG0: Alice , whose husband went jogging every Sunday] , liked to [V: go] [ARG4: to a dancing class] [ARGM-TMP: in the meantime] .
Verb: dancing Alice , whose husband went jogging every Sunday , liked to go to a [V: dancing] class in the meantime .让我们关注我们感兴趣的部分,看看模型是否找到了谓词。它做了!它找到了liked这个输出摘录中所示的动词,尽管动词like被另一个谓词分隔Alice:
Verb: liked [ARG0: Alice , whose husband went jogging every Sunday]
现在让我们看看在 AllenNLP 的在线 UI 上运行示例后模型分析的可视化表示。变压器首先找到爱丽丝的丈夫:

图 10.12:谓词“went”已被识别
这变压器解释说:
- 谓词或动词是
went whose husband是论据jogging是另一个与wentevery Sunday是一个时间修饰符,在原始输出中表示为[ARGM-TMP: every Sunday]
变压器然后发现爱丽丝的丈夫在做什么:

图 10.13:动词“jogging”的 SRL 检测
我们可以看到动词jogging被识别并与whose husband时间修饰符相关every Sunday。
变压器并不止于此。它现在检测爱丽丝喜欢什么:
 图 10.14:识别动词“喜欢”
图 10.14:识别动词“喜欢”
这Transformer 还可以go正确检测和分析动词:
 图 10.15:检测动词“go”、它的参数和修饰符
图 10.15:检测动词“go”、它的参数和修饰符
我们可以看到时间修饰符in the meantime也被识别出来。考虑到SRL BERT 训练时使用的简单序列+动词输入,这是相当不错的表现。
最后,转换器将最后一个动词 确定dancing为与 相关class:

图 10.16:将论点“class”与动词“dancing”联系起来
样本 4产生的结果非常有说服力!让我们试着找出变压器模型的极限。
样品 5
样本 5没有多次重复一个动词。但是,样本 5包含一个具有多种功能和含义的单词。它超越了多义词,因为这个词round可以有不同的意义和语法功能。这个词round可以是名词、形容词、副词、及物动词或不及物动词。
作为及物动词或不及物动词,round可以达到完美或完成。从这个意义上说,round可以与off.
以下句子使用round过去时:
The bright sun, the blue sky, the warm sand, the palm trees, everything round off.
这个谓词中的动词round 用于“达到完美”的意思。当然,最容易理解的语法形式应该是“四舍五入”。但是让我们看看我们的句子会发生什么。
让我们运行示例5 SRL.ipynb:
prediction=predictor.predict(
sentence="The bright sun, the blue sky, the warm sand, the palm trees, everything round off."
)
head(prediction)输出不显示动词。转换器没有识别谓词。事实上,即使我们运行该full(prediction)函数,它也根本找不到动词:
"verbs": []然而,网上的版本似乎更好地解释了这句话,因为它找到了动词:

图 10.17:检测动词“round”和“everything”作为参数
由于我们喜欢我们的 SRL 变压器,我们会善待它。我们将向它展示如何处理更常用的动词形式。s让我们通过添加to将句子从过去时变为现在时round:
The bright sun, the blue sky, the warm sand, the palm trees, everything rounds off.
让我们SRL.ipynb再试一次现在时:
prediction=predictor.predict(
sentence="The bright sun, the blue sky, the warm sand, the palm trees, everything rounds off."
)
head(prediction)原始的输出显示找到了谓词,如下输出所示:
Verb: rounds [ARG1: The bright sun , the blue sky , the warm sand , the palm trees , everything] [V: rounds] [ARGM-PRD: off] .如果我们在 AllenNLP 上运行这个句子,我们会得到直观的解释:

图 10.18:检测单词“rounds”作为动词
我们基于 BERT 的转换器做得很好,因为round可以找到该词rounds的现在时形式。
BERT 模型最初未能产生我们预期的结果。但在朋友的帮助下,这个样本的一切都结束了。
我们可以看到:
- 输出可能会随着我们实施的模型版本的演变而变化
- 工业 4.0 务实的心态需要更多的认知努力来向转型者展示该做什么
让我们尝试另一个难以标记的句子。
样品 6
样本 6取了一个我们经常认为只是名词的词。然而,比我们想象的更多的词既是名词又是动词。例如,to ice是曲棍球中使用的动词,用于将冰球一路射过溜冰场并越过对手的球门线。冰球是曲棍球中使用的圆盘。
曲棍球教练可以通过告诉球队训练冰球来开始新的一天。然后我们可以得到教练大喊时的祈使句:
Now, ice pucks guys!
请注意,这guys可能意味着不分性别的人。
让我们运行Sample 6单元格,看看会发生什么:
prediction=predictor.predict(
sentence="Now, ice pucks guys!"
)
head(prediction)转换器找不到动词:"verbs": []。
游戏结束!我们可以看到 Transformer 取得了巨大的进步,但开发者仍有很大的改进模型的空间。人类仍在游戏中向变形金刚展示该做什么。
pucks在线界面与动词混淆:
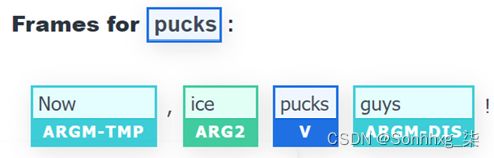
图 10.19:模型错误地将“puck”标记为动词
这个问题可以用另一个模型解决,但你会达到另一个极限。即使是 GPT-3 也有您必须应对的限制。
当您使用专业术语或技术词汇为定制应用程序实施转换器时,您将在某些时候达到难以处理的限制。
这些限制将需要您的专业知识才能使项目成功。因此,您必须创建专门的词典才能在项目中取得成功。这对开发者来说是个好消息!您将发展您的团队会欣赏的新的跨学科和认知技能。
尝试一些您自己的示例或示例,看看 SRL 可以利用该方法的限制做什么。然后探索如何开发预处理功能以向转换器展示如何为您的定制应用程序做些什么。
在我们离开之前,让我们质疑 SRL 的动机。
质疑 SRL 的范围
面对现实生活中的项目时,我们是孤独的。我们有工作要做,只有人要满足的是那些要求该项目的人。
实用主义必须先行。之后的技术思想。
在 2020 年代,旧的 AI 意识形态和新的意识形态并存。到本世纪末,将只有一个赢家将前者的一些合并到后者中。
本节通过两个方面质疑 SRL 的生产力及其动机:
- 谓词分析的极限
- 质疑“语义”一词的使用
谓词分析的极限
SRL 依赖关于谓词。SRL BERT 仅在您提供动词时才有效。但是数以百万计的句子不包含动词。
如果您在 AllenNLP 演示界面 ( AllenNLP - Demo ) 的语义角色标签部分中仅提供 SRL BERT并带有断言,则它可以工作。
但是,如果您的断言是对某个问题的回答,会发生什么:
- 第 1 个人:
What would you like to drink, please? - 第 2 个人:
A cup of coffee, please.
当我们输入第 2 个人的答案时,SRL BERT 什么也没找到:

图 10.20:未获得帧
输出是0总帧数。SRL 无法分析这句话,因为它包含省略号。谓词是隐式的,而不是显式的。
省略号的定义是从一个句子中留下一个或几个单词的行为,这对于理解它是不必要的。
每天有数以亿计的包含省略号的句子被说和写。
然而,SRL BERT 为所有这些产生了0 总帧。
以下对以、开头的A问题 ( ) 的答案 ( )并产生0 总帧数:Qwhatwherehow
Q: What would you like to have for breakfast?
A: Pancakes with hot chocolate.
(模型推导出:pancakes=专有名词、with=介词、hot=形容词和chocolate=普通名词。)
Q: Where do you want to go?
A: London, please.
(模型推导出:London=专有名词和please=副词。)
Q: How did you get to work today?
A: Subway.
(模型推导出:subway=专有名词。)
我们可以找到数百万个 SRL BERT 无法理解的示例,因为这些句子不包含谓词。
我们也可以将其应用于对话中间的问题,并且仍然没有从 SRL BERT 获得任何帧(输出):
背景:谈话的中间人 2 不想喝咖啡:
Q: So, tea?
A: No thanks.
Q: Ok, hot chocolate?
A: Nope.
Q: A glass of water?
A: Yup!
我们刚刚看到一个没有框架、没有语义标签的对话。没有什么。
我们可以在社交媒体上完成一些产生 0 帧的电影、音乐会或展览评论:
Best movie ever!Worst concert in my life!Excellent exhibition!
本节展示了 SRL 的局限性。现在让我们重新定义 SRL 并展示如何实现它。
重新定义 SRL
SRL BERT 假设句子包含谓词,这在许多情况下是错误的假设。分析句子不能仅基于谓词分析。
谓词包含一个动词。谓词告诉我们更多关于主语的信息。以下谓词包含动词和附加信息:
The dog ate his food quickly.ate...quickly告诉我们更多关于狗吃东西的方式。但是,单独的动词可以是谓词,如:
Dogs eat.
这里的问题在于“动词”和“谓词”是句法和语法分析的一部分,而不是语义。
从语法和功能的角度理解单词如何组合在一起是有限制的。
拿这句话绝对没有意义:
Globydisshing maccaked up all the tie.SRL BERT 完美地对没有任何意义的句子执行“语义”分析:

图 10.21:分析一个无意义的句子
我们可以从这些例子中得出一些结论:
- SRL 谓词分析仅在句子中有动词时有效
- SRL 谓词分析无法识别省略号
- 谓词和动词是语言结构的一部分,是语法分析的一部分
- 谓词分析识别结构但不识别句子的含义
- 语法分析远远超出了作为句子必要中心的谓词分析
语义关注关于短语或句子的含义。语义学侧重于上下文和单词相互关联的方式。
语法分析包括句法、屈折变化以及短语或句子中单词的功能。语义角色标签一词具有误导性;它应该被命名为“谓词角色标签”。
我们完全理解没有谓词和超出序列结构的句子。
情感分析可以解码句子的含义,并在没有谓词分析的情况下为我们提供输出。情感分析算法完全理解“有史以来最好的电影”是积极的,无论是否存在谓词。
单独使用 SRL 来分析语言是有限制的。在 AI 管道或其他 AI 工具中使用 SRL 可以非常有效地为自然语言理解添加更多智能。
我的建议是将 SRL 与其他 AI 工具一起使用,我们将在第 13 章使用Transformers 分析假新闻中看到。
现在让我们结束我们对 SRL 范围和限制的探索。
概括
在本章中,我们探讨了 SRL。SRL 任务对人和机器来说都很困难。Transformer 模型表明,在一定程度上可以达到许多 NLP 主题的人类基线。
我们发现一个简单的基于 BERT 的转换器可以执行谓词意义消歧。我们运行了一个简单的转换器,它可以在没有词汇或句法标签的情况下识别动词(谓词)的含义。Shi和Lin (2019) 使用标准句子+动词输入格式来训练他们基于 BERT 的转换器。
我们发现用精简的句子+谓词输入训练的转换器可以解决简单和复杂的问题。当我们使用相对稀有的动词形式时,就达到了极限。然而,这些限制并不是最终的。如果将难题添加到训练数据集中,研究团队可以改进模型。
我们还发现存在造福人类的人工智能。艾伦人工智能研究所提供了许多免费的人工智能资源。此外,研究团队还在 NLP 模型的原始输出中添加了视觉表示,以帮助用户理解 AI。我们看到解释人工智能与运行程序一样重要。视觉和文本表示清晰地展示了基于 BERT 的模型的潜力。
最后,我们探索了 SRL 的范围和限制,以优化我们如何将此方法与其他 AI 工具一起使用。
Transformers 将通过其分布式架构和输入格式继续改进 NLP 的标准化。
在下一章,第 11 章,让您的数据说话:故事、问题和答案,我们将挑战变形金刚通常只有人类才能完成的任务。在面对命名实体识别( NER ) 和问答任务时,我们将探索 Transformer 的潜力。