深入分析负载均衡情景
本文出现的内核代码来自Linux5.4.28,为了减少篇幅,我们尽量不引用代码,如果有兴趣,读者可以配合代码阅读本文。
一、有几种负载均衡的方式?
整个Linux的负载均衡器有下面的几个类型:
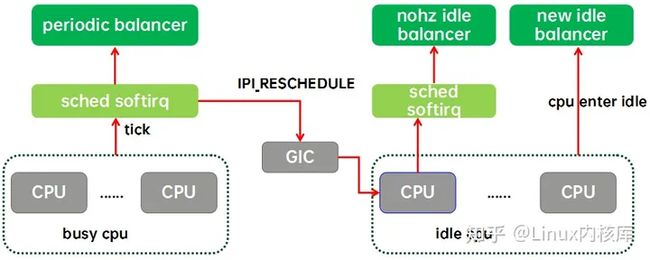
实际上内核的负载均衡器(本文都是特指CFS任务的)有两种,一种是为繁忙CPU们准备的periodic balancer,用于CFS任务在busy cpu上的均衡。还有一种是为idle cpu们准备的idle balancer,用于把繁忙CPU上的任务均衡到idle cpu上来。idle balancer有两种,一种是nohz idle balancer,另外一种是new idle balancer。
周期性负载均衡(periodic load balance或者tick load balance)是指在tick中,周期性的检测系统的负载均衡状况,找到系统中负载最重的domain、group和CPU,将其上的runnable任务拉到本CPU以便让系统的负载处于均衡的状态。周期性负载均衡只能在busy cpu之间均衡,要想让系统中的idle cpu“燥起来”就需要借助idle load balance。
NOHZ load balance是指其他的cpu已经进入idle,本CPU任务太重,需要通过ipi将其他idle的CPUs唤醒来进行负载均衡。为什么叫NOHZ load balance呢?那是因为这个balancer只有在内核配置了NOHZ(即tickless mode)下才会生效。如果CPU进入idle之后仍然有周期性的tick,那么通过tick load balance就能完成负载均衡了,不需要IPI来唤醒idle的cpu。和周期性均衡一样,NOHZ idle load balance也是通过busy cpu上tick驱动的,如果需要kick idle load balancer,那么就会通过GIC发送一个ipi中断给选中的idle cpu,让它代表系统所有的idle cpu们进行负载均衡。
New idle load balance比较好理解,就是在CPU上没有任务执行,马上要进入idle状态的时候,看看其他CPU是否需要帮忙,从来从busy cpu上拉任务,让整个系统的负载处于均衡状态。NOHZ load balance涉及系统中所有的idle cpu,但New idle load balance只是和即将进入idle的本CPU相关。
二、周期性负载均衡的大概过程为何?
当tick到来的时候,在scheduler_tick函数中会调用trigger_load_balance来触发周期性负载均衡,相关的代码如下:

整个代码非常的简单,主要的逻辑就是调用raise_softirq触发SCHED_SOFTIRQ,当然要满足均衡间隔时间的要求(后面会详述)。nohz_balancer_kick用来触发nohz idle balance的,这是后面两个章节要仔细描述的内容。上面的图片,我特地保留了函数的注释,这里看起似乎注释不对,因为这个函数不但触发的周期性均衡,也触发了nohz idle balance。然而,其实nohz idle balance本质上也是另外一种意义上的周期性负载均衡,只是因为CPU进入idle,无法产生tick,因此让能产生tick的busy CPU来帮忙触发tick balance。而实际上tick balance和nohz idle balance都是通过SCHED_SOFTIRQ的软中断来处理,最后都是执行run_rebalance_domains这个函数。
三、整个nohz idle balance的过程是怎样的?
这个问题可以拆解成两个问题:
1)系统中有多个idle的cpu,如何选择执行nohz idle balance的那个cpu?
2)怎么通知到idle的CPU,唤醒的CPU如何进行均衡?
如果不考虑功耗,那么从所有的idle cpu中选择一个就OK了,然而,在异构系统中(例如手机环境),我们要考虑更多。例如:如果大核CPU和小核CPU都处于idle状态,那么选择唤醒大核CPU还是小核CPU?大核CPU虽然算力强,但是功耗高。如果选择小核,虽然能省功耗,但是提供的算力是否足够。此外,发起idle balance请求的CPU在那个cluster?是否首选同一个cluster的cpu来执行nohz idle balance?还有cpu idle的深度如何?很多思考点,不过本文就不详述了,毕竟标准内核选择的最简单的算法:随便选择一个idle cpu(也就是idle cpu mask中的第一个)。
我们定义发起nohz idle balance的CPU叫做kicker;接收请求来执行均衡操作的CPU叫做kickee。Kicker和kickee之间的交互是这样的:
1)Kicker通知kickee已经被选中执行nohz idle balance,具体是通过设定kickee cpu runqueue的nohz_flags成员来完成的。
2)Send ipi把kickee唤醒
3)Kickee被中断唤醒,执行scheduler_ipi来处理这个ipi中断。当发现其runqueue的nohz_flags成员被设定了,那么知道自己被选中,后续的流程其实和周期性均衡一样的,都是触发一次SCHED_SOFTIRQ类型的软中断
我们再强调一下:被kick的那个idle cpu并不是负责拉其他繁忙cpu上的任务到本CPU上就完事了,kickee是为了重新均衡所有idle cpu(tick被停掉)的负载,也就是说被选中的idle cpu仅仅是一个系统所有idle cpu的代表,它被唤醒是要把系统中繁忙CPU的任务均衡到系统中所有的idle cpu们。此外,在上面的步骤1中,有可能有多个kicker同时选中一个kickee,因此这里需要检测pending的请求,避免重复操作。具体的代码可以参考nohz_balancer_kick函数。
SCHED_SOFTIRQ软中断的处理函数如下:

nohz idle balance和periodic load balance都是通过SCHED_SOFTIRQ类型的软中断来完成,也就是说它们两个都是通过SCHED_SOFTIRQ注册的handler函数run_rebalance_domains来完成其功能的,那么如果一个CPU被选中做nohz idle balance,于此同时tick也到了,那么怎么处理?这个时候调度器优先处理nohz idle balance,毕竟nohz idle balance是一个全局的事情(代表系统所有idle cpu做均衡),而periodic load balance只是均衡自己的各阶sched domain。
四、什么条件下才需要唤醒idle CPU来执行NOHZ idle load balance?
在一个active的CPU上,tick会周期性到来,我们在该CPU的tick中检测是否需要触发NOHZ load balance。显然一个轻载的CPU可以“自力更生”,不需要其他idle的CPU来协助,那么如何界定一个CPU上的任务的轻和重?以至于需要冒险(功耗损失)要将其他idle的CPU唤醒?主要考虑下面几点:
- 本CPU不能处于idle状态,且其runqueue中的任务数大于等于2(load balance主要是迁移runnable的任务,>=2保证了至少有一个可以被迁移的任务)
- 系统中有其他的CPU处于tickless mode的idle状态
- NOHZ load balance不宜触发的过于频繁。下一章会详细描述。
- 本CPU runqueue有至少1个CFS任务,并且CPU的算力被大量消耗在RT task或者IRQ处理上,可以用于执行cfs的算力大大降低了,这时候也需要其他idle cpu来帮忙。
- 在异构计算系统中,如果当前CPU上有misfit task,并且系统中有更高算力的idle cpu,那么也会发起balance,让算力更高的处理器来承接该misfit task。和提高cache命中率相比,调度器更期待任务可以获得更适合算力的CPU。
具体的代码可以参考nohz_balancer_kick函数。
五、如何控制触发nohz idle balance的频次?
虽然nohz idle balance本质上是tick balance,但是它会发IPI,会唤醒idle的cpu,带来额外的开销,所以还是要控制触发触发nohz idle balance的频次。为了方便控制触发nohz idle balance,调度器定义了一个nohz的全局变量,其数据结构如下:
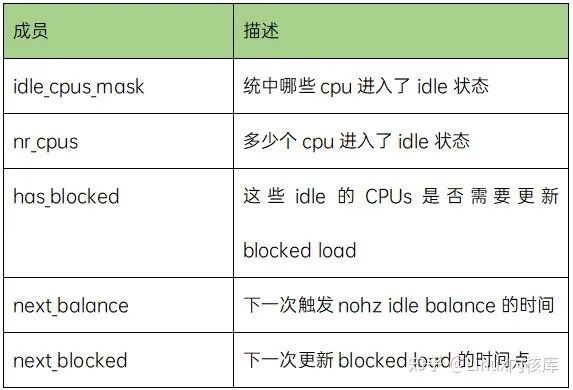
nr_cpus和idle_cpus_mask这两个成员可以让调度器了解当前系统idle CPU的情况,从而选择合适的CPU来执行nohz idle balance。一个idle的cpu被kick并不总是完成负载均衡,有时候也可能是因为要更新blocked load,让系统中的CPU负载符合当前的状态。这部分不是本文的内容,不再详述。next_balance是用来控制触发nohz idle balance的时间点,这个时间点应该是和系统中所有idle cpu的rq->next_balance相关的,也就是说,如果系统中所有idle cpu都还不需要均衡,那么根本也就没有必要触发nohz idle balance,因此,在执行nohz idle balance的时候,调度器实际上会遍历idle cpu找到rq->next_balance最小的(即最近需要均衡的)赋值给nohz.next_balance。
具体执行nohz idle balance非常简单,遍历系统所有的idle cpu,调用rebalance_domains来完成该cpu上的各个level的sched domain的负载均衡。具体的代码可以参考nohz_idle_balance函数。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
六、做new idle load balance需要考虑哪些因素?
目前调度器做new idle load balance主要考虑两个因素:当前cpu的cache状态和当前的整机负载情况。如果该CPU平均idle时间非常短,那么当CPU重新回来执行的任务的时候,CPU cache还是热的,如果从其他CPU上拉取任务,那么这些新的任务会破坏其他任务的cache,从而影响过去任务的性能,同时也有功耗的增加。整机负载的影响记录在root domain中的overload成员中,所谓overload就是指满足下面的条件:
- 大于1个runnable task,即该CPU上有等待执行的任务
- 只有一个正在运行的任务,但是是misfit task
满足上面的条件我们称这个CPU是overload状态的,如果系统中至少有一个CPU是overload状态,那么我们认为系统是overload状态的。如果系统没有overload,那么也就没有必要做new idle load balance了。
上面是从CPU视角做的决定,降低了new idlebalance的次数,此外,调度器也从sched domain的角度进行检查,进一步避免了无效new idlebalance发生的次数。首先我们要明确一点:做new idle load balance是有开销的,我们辛辛苦苦找到了繁忙的CPU,从它的runqueue中拉了任务来,然而如果自己其实也没有那么闲,可能很快就有任务放置到自己的runqueue上来,这样,那些用于均衡的CPU时间其实都白白浪费了。怎么避免这个尴尬状况?我们需要两个数据:一个是当前CPU的平均idle时间,另外一个是在new idle load balance引入的开销(max_newidle_lb_cost成员)。如果CPU的平均idle时间小于max_newidle_lb_cost+本次均衡的开销,那么就不启动均衡。
为了控制cpu无效进入new idle load balance,runqueue数据结构中有下面的成员:
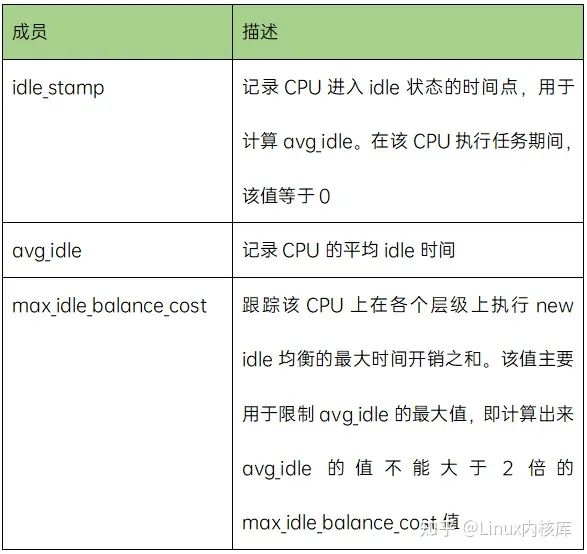
计算avg_idle的算法非常简单,如下:
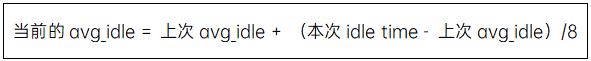
和nohz idle balance一样,new idle balance不仅仅要处理负载均衡,同时也要负责处理blocked load的更新。如果条件不满足,该cpu不需要进行均衡,那么在进入idle状态之前,还需要看看系统中的那些idle cpu们的blocked load是否需要更新了,如果需要,那么该CPU就会执行blocked load的负载更新。其背后的逻辑是:与其在nohz idle balance过程中遍历选择一个idle CPU来做负载更新,还不如就让这个即将进入idle的cpu来处理。具体的代码可以参考newidle_balance函数。
七、对于一个sched domain而言,多久做一次负载均衡比较适合?
负载均衡执行的频次其实是在延迟和开销之间进行平衡。不同level的sched domain上负载均衡带来的开销是不一样的。在手机平台上,MC domain在inter-cluster之内进行均衡,对性能的影响小一点。但是DIE domain上的均衡需要在cluster之间迁移任务,对性能和功耗的影响都比较大一些(例如cache命中率,或者一个任务迁移到原来深度睡眠的大核CPU)。因此执行均衡的时间间隔应该是和domain的层级相关的。此外,负载状况也会影响均衡的时间间隔,在各个CPU负载比较重的时候,均衡的时间间隔可以拉大,毕竟大家都忙,让子弹先飞一会,等尘埃落定之后在执行均衡也不迟。
struct sched_domain和均衡相关的数据成员包括:

对于一个4+4的手机平台,在MC domain上,小核和大核cluster的min_interval都是4ms,而max_interval等于8ms。而在DIE domain层级上,由于CPU个数是8,其min_interval是8ms,而max_interval等于16ms。真正的均衡间隔是定义在balance_interval中,是一个不断跟随sched domain的不均衡程度而变化的值。初值一般从min_interval开始,随着不均衡的状况在变好,balance_interval会逐渐变大,从而让均衡的间隔变大,直到max_interval。
八、结束语
周期性均衡和nohz idle balance都是SCHED类型的软中断触发,最后都调用了rebalance_domains来执行该CPU上各个level的sched domain的均衡,具体在某个sched domain执行均衡的函数是load_balance函数。对于new idle load balance,也是遍历该CPU上各个level的sched domain执行均衡动作,调用的函数仍然是load_balance。因此,无论哪一种均衡,最后都万法归宗来到load_balance。由于篇幅原因,本文不再详细分析load_balance的逻辑,想要了解细节且听下回分解吧。
原文作者:内核工匠
