Java集合
文章目录
- 数组
-
- 一维数组
-
- 声明 + 初始化
- 默认初始化值
- 多维数组
-
- 声明 + 初始化
- Arrays工具类
- 数组中常见异常
- 集合
-
- Collection
- Iterator
- List
-
- ArrayList
- LinkedList
- Vector
- Set
-
- HashSet
- LinkedHashSet
- TreeSet
- Map
-
- HashMap
- LinkedHashMap
- TreeMap
- HashTable
- Properties
- 比较器
-
- 自然排序:java.lang.Comparable
- 定制排序:java.util.Comparator
数组
一维数组
声明 + 初始化
- 动态初始化:数组声明 且为数组元素分配空间与赋值的操作分开进行
int[] arr = new int[3]; arr[0] = 3; arr[1] = 9; arr[2] = 8;String names[]; names = new String[3]; names[0] = “钱学森”; names[1] = “邓稼先”; names[2] = “袁隆平”; - 静态初始化:在定义数组的同时就为数组元素分配空间并赋值。
int arr[] = new int[]{ 3, 9, 8}; int[] arr = {3,9,8}; String names[] = {“李四光”,“茅以升”,“华罗庚”}
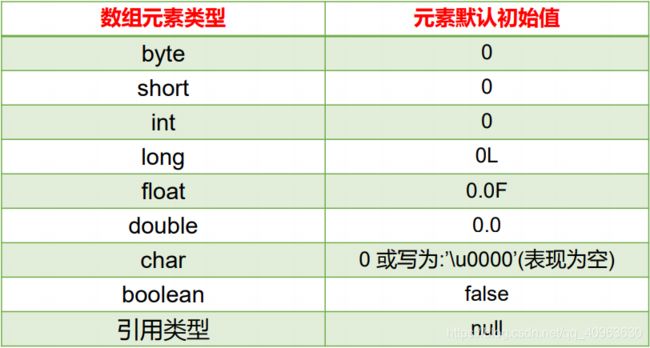
默认初始化值
多维数组
声明 + 初始化
- 动态初始化:
int[][] arr = new int[3][2];
定义了名称为arr的二维数组
二维数组中有3个一维数组
每一个一维数组中有2个元素
一维数组的名称分别为arr[0], arr[1], arr[2]
给第一个一维数组1脚标位赋值为78写法是:arr[0][1] = 78;int[][] arr = new int[3][];
二维数组中有3个一维数组。
每个一维数组都是默认初始化值null (注意:区别于格式1)
可以对这个三个一维数组分别进行初始化
arr[0] = new int[3]; arr[1] = new int[1]; arr[2] = new int[2];
注:int[][]arr = new int[][3]; //非法
- 静态初始化
int[][] arr = new int[][]{{3,8,2},{2,7},{9,0,1,6}};
定义一个名称为arr的二维数组,二维数组中有三个一维数组
注意特殊写法情况:int[] x,y[]; x是一维数组,y是二维数组。
Arrays工具类
java.util.Arrays类即为操作数组的工具类,包含了用来操作数组(比如排序和搜索)的各种方法。
boolean equals(int[] a,int[] b)判断两个数组是否相等。
String toString(int[] a)输出数组信息。
void fill(int[] a,int val)将指定值填充到数组之中。
void sort(int[] a)对数组进行排序。
int binarySearch(int[] a,int key)对排序后的数组进行二分法检索指定的值。
- java.util.Arrays类的sort()方法提供了数组元素排序功能
import java.util.Arrays;
public class SortTest {
public static void main(String[] args) {
int [] numbers = {5,900,1,5,77,30,64,700};
Arrays.sort(numbers);
for(int i = 0; i < numbers.length; i++){
System.out.println(numbers[i]);
}
}
}
数组中常见异常
- 数组脚标越界异常(
ArrayIndexOutOfBoundsException)
int[] arr = new int[2];
System.out.println(arr[2]);
System.out.println(arr[-1]);
访问到了数组中的不存在的脚标时发生。
- 空指针异常(
NullPointerException)
int[] arr = null;
System.out.println(arr[0]);
arr引用没有指向实体,却在操作实体中的元素时。
集合
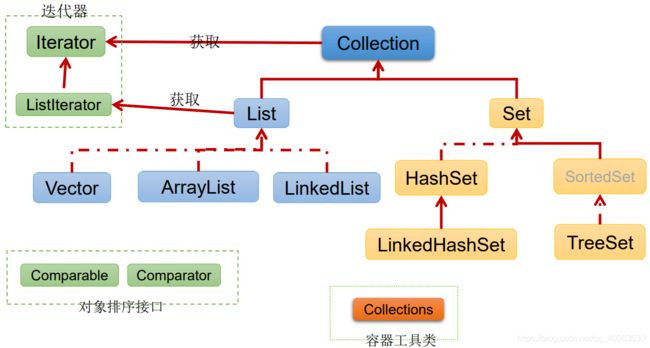
Java 集合可分为 Collection 和 Map 两种体系
Collection接口:单列数据,定义了存取一组对象的方法的集合
- List:元素有序、可重复的集合
- Set:元素无序、不可重复的集合
Map接口:双列数据,保存具有映射关系“key-value对”的集合
Collection
是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象
boolean containsAll(Collection c):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。
boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
boolean removeAll(Collection coll):取当前集合的差集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
boolean equals(Object obj):集合是否相等
Object[] toArray():转成对象数组
iterator():返回迭代器对象,用于集合遍历
Iterator
Iterator iter = coll.iterator();//回到起点
//hasNext():判断是否还有下一个元素
while(iter.hasNext()){
//next():①指针下移 ②将下移以后集合位置上的元素返回
Object obj = iter.next();
if(obj.equals("Tom")){
iter.remove();
}
}
Java 5.0 提供了 foreach 循环迭代访问 Collection和数组。
遍历操作不需获取Collection或数组的长度,无需使用索引访问元素。
遍历集合的底层调用Iterator完成操作。
foreach还可以用来遍历数组。
List
ArrayList和LinkedList的异同
二者都线程不安全,相对线程安全的Vector,执行效率高。
此外,ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add(特指插入)和remove,LinkedList比较占优势,因为ArrayList要移动数据。
ArrayList和Vector的区别
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比ArrayList要大,访问要慢。
正常情况下,大多数的Java程序员使用ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。
Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。
Vector还有一个子类Stack。
ArrayList
LinkedList
Vector
Set
HashSet
LinkedHashSet
TreeSet
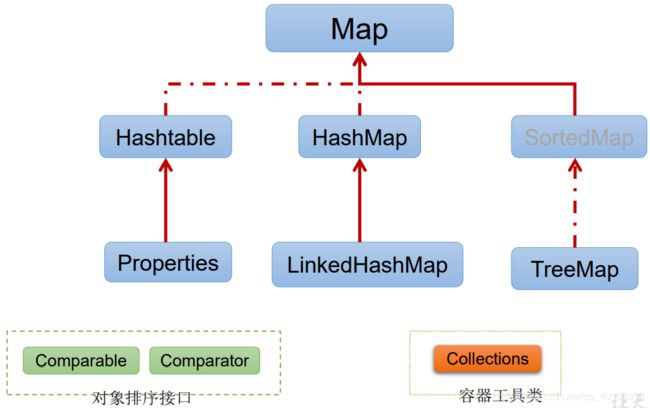
Map
Map中的key:
无序的、不可重复的,使用Set存储所有的key→key所在的类要重写equals()和hashCode() (以HashMap为例)
Map中的value:
无序的、可重复的,使用Collection存储所有的value —>value所在的类要重写equals()
一个键值对:key-value构成了一个Entry对象。
Map中的entry:无序的、不可重复的,使用Set存储所有的entry
Map:双列数据,存储key-value对的数据
HashMap:作为Map的主要实现类;线程不安全的,效率高;可以存储null的key和value
LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,此类执行效率高于HashMap。
TreeMap:保证按照添加的key-value对进行排序,实现排序遍历。
此时考虑key的自然排序或定制排序
底层使用红黑树
Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
Properties:常用来处理配置文件。key和value都是String类型
HashMap
HashMap的底层实现原理?
1.JDK7中
HashMap map = new HashMap():
在实例化以后,底层创建了长度是16的一维数组Entry[] table。
map.put(key1,value1):
首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
如果此位置上的数据为空,此时的key1-value1添加成功。 ----情况1
如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2
如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法,比较:
如果equals()返回false:此时key1-value1添加成功。----情况3
如果equals()返回true:使用value1替换value2。
补充:关于情况2和情况3:此时key1-value1和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
2.JDK8中
jdk8 相较于jdk7在底层实现方面的不同:
1. new HashMap():底层没有创建一个长度为16的数组
2. jdk 8底层的数组是:Node[],而非Entry[]
3. 首次调用put()方法时,底层创建长度为16的数组
4. jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。
4.1 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
4.2 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75
threshold:扩容的临界值,=容量*填充因子:16 * 0.75 => 12
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
LinkedHashMap
TreeMap
HashTable
Properties
比较器
在Java中经常会涉及到对象数组的排序问题,那么就涉及到对象之间的比较问题。
Java实现对象排序的方式有两种:
自然排序:java.lang.Comparable
定制排序:java.util.Comparator
自然排序:java.lang.Comparable
Comparable接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序。
实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。
如果当前对象this大于形参对象obj,则返回正整数,
如果当前对象this小于形参对象obj,则返回负整数,
如果当前对象this等于形参对象obj,则返回零。
实现Comparable接口的对象列表(和数组)可以通过 Collections.sort 或Arrays.sort进行自动排序。实现此接口的对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
对于类 C 的每一个 e1 和 e2 来说,当且仅当 e1.compareTo(e2) == 0 与e1.equals(e2) 具有相同的 boolean 值时,类 C 的自然排序才叫做与 equals一致。建议(虽然不是必需的)最好使自然排序与 equals 一致。
Comparable 的典型实现:(默认都是从小到大排列的)
String:按照字符串中字符的Unicode值进行比较
Character:按照字符的Unicode值来进行比较
数值类型对应的包装类以及BigInteger、BigDecimal:按照它们对应的数值大小进行比较
Boolean:true 对应的包装类实例大于 false 对应的包装类实例
Date、Time等:后面的日期时间比前面的日期时间大
class Goods implements Comparable {
private String name;
private double price;
//按照价格,比较商品的大小
@Override
public int compareTo(Object o) {
if(o instanceof Goods) {
Goods other = (Goods) o;
if (this.price > other.price) {
return 1;
} else if (this.price < other.price) {
return -1;
}
return 0;
}
throw new RuntimeException("输入的数据类型不一致");
}
//构造器、getter、setter、toString()方法略
}
public class ComparableTest{
public static void main(String[] args) {
Goods[] all = new Goods[4];
all[0] = new Goods("《红楼梦》", 100);
all[1] = new Goods("《西游记》", 80);
all[2] = new Goods("《三国演义》", 140);
all[3] = new Goods("《水浒传》", 120);
Arrays.sort(all);
System.out.println(Arrays.toString(all));
}
}
定制排序:java.util.Comparator
当元素的类型没有实现java.lang.Comparable接口而又不方便修改代码,或者实现了java.lang.Comparable接口的排序规则不适合当前的操作,那么可以考虑使用 Comparator 的对象来排序,强行对多个对象进行整体排序的比较。
重写compare(Object o1,Object o2)方法,比较o1和o2的大小:如果方法返回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示o1小于o2。
可以将 Comparator 传递给 sort 方法(如 Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。
还可以使用 Comparator 来控制某些数据结构(如有序 set或有序映射)的顺序,或者为那些没有自然顺序的对象 collection 提供排序。
@Test
public void test(){
String[] arr = new String[]{"AA","CC","KK","MM","GG","JJ","DD"};
Arrays.sort(arr,new Comparator(){
//按照字符串从大到小的顺序排列
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof String && o2 instanceof String){
String s1 = (String) o1;
String s2 = (String) o2;
return -s1.compareTo(s2);
}
throw new RuntimeException("输入的数据类型不一致");
}
});
System.out.println(Arrays.toString(arr));
}