【Quartz】(一)定时框架Quartz的持久化配置
1. 使用背景
当前,越来越多的场景下面需要使用到定时任务,比如报表的生成,每月或者每年进行一次某些数据的统计等等,使用Springboot中的@Scheduled注解固然也可以实现,只不过,如果要改定时的时间,控制定时的开关,都需要直接操作项目的代码,如果是线上环境的,还得需要把项目 停下来,代价太大,那到底有没有一种框架可以实现我们对于定时任务的增删查改,可以修改定时的时间,启动以及暂定定时任务呢,答案是有的,目前定时任务的框架有很多,比如我们今天要说的Quartz,分布式定时任务xxl-job等等。
2.Quartz持久化定时任务的原理
Quartz的依赖
<dependency>
<groupId>org.quartz-schedulergroupId>
<artifactId>quartzartifactId>
<version>2.3.0version>
dependency>
打开Quartz包下的路径org.quartz.impl.jdbcjobstore可以看到有很多的sql
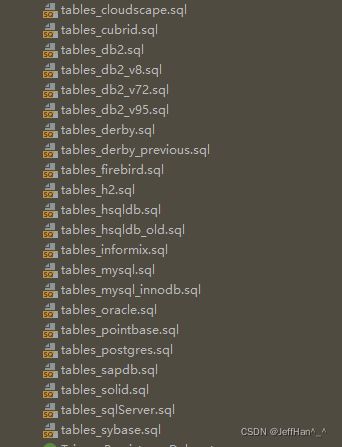
这些Sql文件是quartz针对不同的数据库设计的,我们使用的是Mysql,所以我们将tables_mysql_innodb.sql在数据库里面跑一下,看下效果
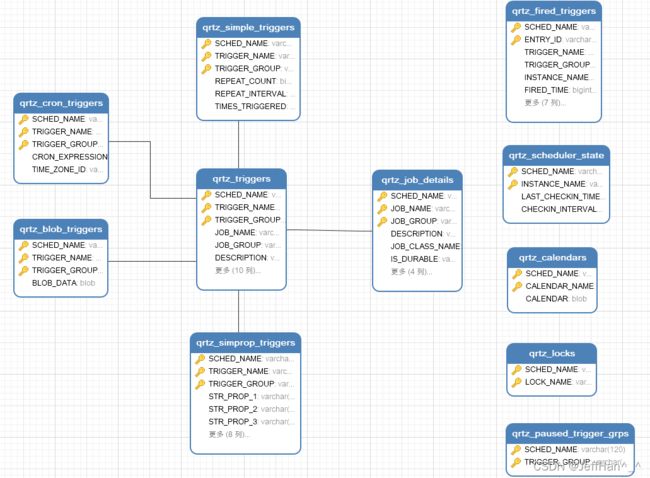
看到默认帮我们生成了这11张表,通过分析这些表,我们就能大致了解Quartz实现定时任务持久化的原理。
| 表名 | 含义 |
|---|---|
| qrtz_blob_triggers | 存储用户自定义的trigger,实现Trigger等接口实现自定义逻辑 |
| qrtz_calendars | 存储和触发器关联的日期 |
| qrtz_cron_triggers | 存储cron类型的触发器 |
| qrtz_fired_triggers | 存储正在执行的任务 |
| qrtz_job_details | 存储任务的详细信息 |
| qrtz_locks | 存储执行任务需要获取的锁 |
| qrtz_paused_trigger_grps | 存储被暂停的触发器组 |
| qrtz_scheduler_state | 存储集群环境的状态 |
| qrtz_simple_triggers | 存储简单触发器 |
| qrtz_simprop_triggers | 存储CalendarIntervalTrigger和DailyTimeIntervalTrigger |
| qrtz_triggers | 存储任务执行的时间,下次执行时间,任务执行的状态等信息 |
其实quartz的执行逻辑很简单,就是从qrtz_triggers获取等待状态将要执行的任务,通过关联查询,查询对应的触发器,以及job_details中任务执行的类进行任务的执行,简单的来说,就是这样的。
3. 持久化配置
我这里以Springboot配置为例,讲解一下如何进行配置。
定义一个Quartz的配置类QuartzConfig
@Configuration
public class QuartzConfig{
@Bean
public SchedulerFactoryBean schedulerFactoryBean(DataSource dataSource){
SchedulerFactoryBean factory = new SchedulerFactoryBean();
// 设置数据源,这个数据源是从Bean获取来的,可以在Bean里面配置任意的数据库
factory.setDataSource(dataSource);
Properties prop = new Properties();
// 集群环境的唯一ID,名字可以任意设置,instanceId设置成AUTO,系统会帮我们自动生成
prop.put("org.quartz.scheduler.instanceName", "MyScheduler");
prop.put("org.quartz.scheduler.instanceId", "AUTO");
// 配置Quartz运行的线程池配置
prop.put("org.quartz.threadPool.class", "org.quartz.simpl.SimpleThreadPool");
prop.put("org.quartz.threadPool.threadCount", "20");
prop.put("org.quartz.threadPool.threadPriority", "5");
// 非常重要!JDBC的增删查改都是依靠JobStore来完成的。
prop.put("org.quartz.jobStore.class", "org.quartz.impl.jdbcjobstore.JobStoreTX");
// 配置集群环境
prop.put("org.quartz.jobStore.isClustered", "true");
prop.put("org.quartz.jobStore.clusterCheckinInterval", "15000");
prop.put("org.quartz.jobStore.maxMisfiresToHandleAtATime", "1");
prop.put("org.quartz.jobStore.txIsolationLevelSerializable", "true");
//若集群环境需要配置此项,可防止重复执行,单机环境不推荐配置此项,会消耗服务器性能
//prop.put("org.quartz.jobStore.acquireTriggersWithinLock","true");
prop.put("org.quartz.jobStore.misfireThreshold", "12000");
prop.put("org.quartz.jobStore.tablePrefix", "QRTZ_");
factory.setQuartzProperties(prop);
factory.setSchedulerName("MyScheduler");
// 延时启动
factory.setStartupDelay(1);
factory.setApplicationContextSchedulerContextKey("applicationContextKey");
// 可选,QuartzScheduler
// 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了
factory.setOverwriteExistingJobs(true);
// 设置自动启动,默认为true
factory.setAutoStartup(true);
return factory;
}
}
4.持久化一些简单的实现
我们首先定义一个Job,我希望这个Job帮我打印字符串
public class TestTask implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("Hello");
}
}
然后我们告诉Quartz,申请一个名称为job1,组为group1的JobDetails帮我们记录这个Job
@RestController
@RequestMapping("/job")
public class JobController {
@Autowired
private Scheduler scheduler;
@RequestMapping("createJob")
public String createJob() throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(TestTask.class).withIdentity("job1", "group1").build();
return "created!";
}
}
光这样还不行,我们还要申请一个名称为trigger1,组为tgroup1的Cron类型的触发器,告诉Quartz这个任务执行的周期
@RestController
@RequestMapping("/job")
public class JobController {
@Autowired
private Scheduler scheduler;
@RequestMapping("createJob")
public String createJob() throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(TestTask.class).withIdentity("job1", "group1").build();
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "tgroup1")
.withSchedule(CronScheduleBuilder.cronSchedule("* * * * * ?")).build();
return "created!";
}
}
然后通过Quartz的调度器,帮我们执行的任务,通过我们创建的Cron的触发器
@RestController
@RequestMapping("/job")
public class JobController {
@Autowired
private Scheduler scheduler;
@RequestMapping("createJob")
public String createJob() throws SchedulerException {
JobDetail jobDetail = JobBuilder.newJob(TestTask.class).withIdentity("job1", "group1").build();
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "tgroup1")
.withSchedule(CronScheduleBuilder.cronSchedule("* * * * * ?")).build();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
return "created!";
}
}
启动项目
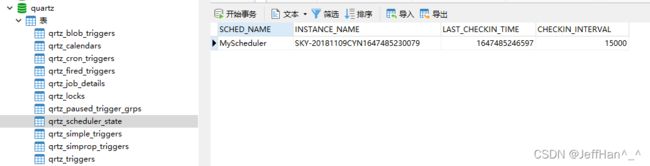
此时观察表,可以发现
qrtz_scheduler_state已经记录了我们的第一台的机器的信息
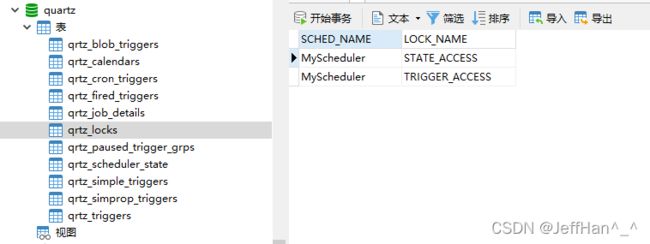
此外,qrtz_locks里面也帮我们生成了两把锁,关于这个锁的含义,下一篇博客中,我会和大家讲解一下含义
其他表里面暂时没有数据了,那么现在我们我们利用我们刚刚写的那个接口帮我们创建一个job试一下
http://ip:端口/job/createJob
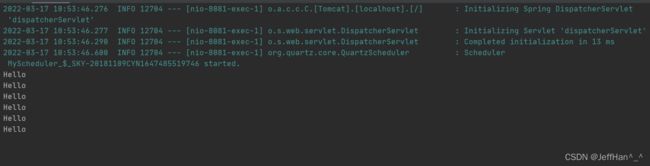
可以看到此时任务一直在重复执行
我们再来看一下表里面发生了哪些数据的改变
首先qrtz_cron_triggers,帮我们新增了一条我们刚刚定义的cron的trigger
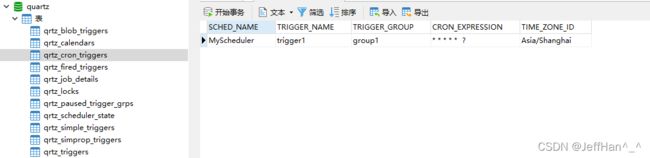
qrtz_job_details,也帮我们新建了一条任务的详情,记录了任务执行类的全限定名

qrtz_fired_triggers记录了此时此刻,我们正在执行的定时任务

qrtz_triggers记录了我们已有任务的一些信息,包括上一次执行的时间,下一次执行的时间,以及任务此时的状态等

看到这里,相信大家应该觉得Quartz不过如此,非常的简单,但是如果仅仅是这样使用也会产生某些问题,后面的博客中,我将详细介绍一下,集群环境下Quartz重复执行产生的原因,以及如何去解决重复执行的问题,包括我们如果在一个Springboot项目中如何优雅的使用Quartz,我们可以在页面中,增删查改定制化我们的任务。