Spark3.2教程(九)CentOS7下Spark Standalone分布式搭建
Spark搭建方式有local、Standalone、on Yarn等。
- local模式适合程序的开发测试
- Standalone模式适合小规模数据
- on Yarn适合大数据量大,并且可能依赖于其他计算引擎,如MapReduce,这样可以更好的和Hadoop集成
因为Spark本质上是一个计算引擎,对于学习它而言,用本地模式就可以,实际工作中会有专门人员根据实际情况进行合适模式的搭建。
但是作为想要提高自己认知的学习者,还是有必要在Linux下搭建一套环境的。我们本次在3台节点上搭建一个Spark Standalone模式的分布式集群环境。
Linux环境为CentOS7,JDK1.8,Spark3.2.0,因为是Standalone模式,Hadoop可有可无。
版本选择,避免踩坑请看:
Spark3.2教程(前置)关于Spark3.2.0与Scala版本的坑
三台虚拟机如下所示,其中hp1为主结点。
| 主机名 | IP地址 |
|---|---|
| hp1 | 192.168.150.101 |
| hp2 | 192.168.150.102 |
| hp3 | 192.168.150.103 |
| 一、静态IP、关闭防火墙,关闭selinux,修改hosts做一个映射,修改ip地址 | |
| 参见:Hadoop3.3.1详细教程(二)样机配置 | |
| 二、安装JDK | |
| 参见:Hadoop3.3.1详细教程(三)克隆样机+JDK安装 | |
| 三、免密登录 | |
| 参见:Hadoop3.3.1详细教程(四)Linux集群搭建+免密登录 |
搭建Spark:
1.将spark-3.2.0-bin-hadoop3.2-scala2.13.tgz上传到/apps文件夹下
2.解压至/usr/local下
tar -zxvf /apps/spark-3.2.0-bin-hadoop3.2-scala2.13.tgz -C /usr/local
3.为其创建一个软连接:
ln -s /usr/local/spark-3.2.0-bin-hadoop3.2-scala2.13 /usr/local/spark3
4.配置环境变量
vi /etc/profile.d/spark.sh
export SPARK_HOME=/usr/local/spark3
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
使之生效:
source /etc/profile.d/spark.sh
5.修改配置文件
在spark/conf目录下
复制spark-env.sh.template文件,命名为 spark-env.sh
cp spark-env.sh.template spark-env.sh
在里面最后追加上:
export JAVA_HOME=$JAVA_HOME
export SPARK_HOME=$SPARK_HOME
复制workers.template文件,命名为 workers
和Hadoop一样,设置从结点,将里面内容替换为:
hp2
hp3
6,将hp1配置好的Spark、环境变量分发到hp2、hp3
scp -r /usr/local/spark-3.2.0-bin-hadoop3.2-scala2.13/ hp2:/usr/local
scp -r /usr/local/spark-3.2.0-bin-hadoop3.2-scala2.13/ hp3:/usr/local
scp -r /etc/profile.d/spark.sh hp2:/etc/profile.d
scp -r /etc/profile.d/spark.sh hp3:/etc/profile.d
并分别进入hp2、hp3创建软连接、并让它们的环境变量生效。
7.启动:
启动Spark的命令和Haooop一样,都是start-all.sh,因为本集群之前已经搭建好了Hadoop,所以这时候直接输入start-all.sh,只会启动Hadoop。在这种情况下,可以通过加$SPARK_HOME前缀的方式找到start-all.sh启动。
$SPARK_HOME/sbin/start-all.sh
jps主结点会有Master进程,从结点会有Worker进程。
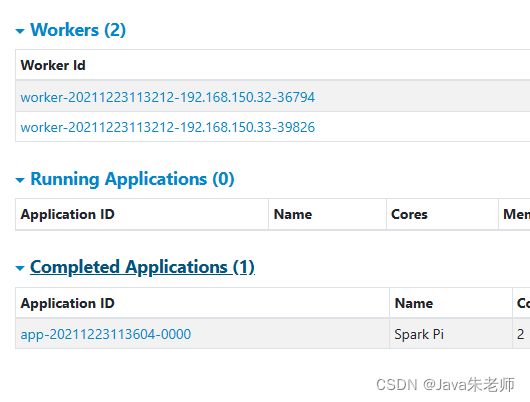
访问WEB UI界面:

8.测试
在启动Spark的时候,控制台会打印出一行信息来,这就是Master的URL,在接下来的运行jar时候,需要指定。
spark://hp1:7077
通过Spark自带的PI程序测试:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hp1:7077 --num-executors 2 /usr/local/spark3/examples/jars/spark-examples_2.13-3.2.0.jar
可以在打印的日志中,找到结果值:

通过WEB UI可以看到运行、结束的任务信息。