Spark笔记(pyspark)
https://github.com/QInzhengk/Math-Model-and-Machine-Learning
Spark笔记
-
-
- 1、基本概念
- 2、架构设计
- 3、Spark运行流程
- 4、弹性分布数据集(RDD)
-
- 1.groupByKey和reduceByKey的区别
- 2. 哪两个Action算子的结果不经过Driver, 直接输出?
- 3. mapPartitions 和 foreachPartition 的区别?
- 5、Shuffle与依赖
- 6、持久化
-
- 1. Cache和Checkpoint区别
- 2. Cache 和 CheckPoint的性能对比?
- 7、Spark On Yarn两种模式总结
- 8、Spark内核调度
-
- 1.DAG之Job和Action
- 2.Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?
- 3. Spark为什么比MapReduce快
- 4.Saprk并行度
- 5.Spark中数据倾斜
- 9、DataFrame
-
- 1.DataFrame的组成
- 2.DataFrame之DSL
- 3.DataFrame之SQL
- 4.pyspark.sql.functions 包
- 5.SparkSQL Shuffle 分区数目
- 6.SparkSQL 数据清洗API
- 7.DataFrame数据写出
- 10、SparkSQL
-
- 1.定义UDF函数
- 2.使用窗口函数
- 11、PySpark参数
-
- 1.spark启动参数
- 2.参数设置
-
- 1.2.1 --driver-memory:
- 1.2.2 --num-executors | --executor-cores | --executor-memory
- 1.2.3 --conf spark.dynamicAllocation.maxExecutors
- 1.2.4 日志级别设置
- 1.2.5 spark.shuffle.memoryFraction
- 1.2.6 spark.storage.memoryFraction
- 3.spark调试
- 4.错误及解决方法
-
- 3.4G物理内存已经使用了3.4G(说明物理内存不够);16.9G虚拟内存已经使用了7.5G。
- Python运行spark时出现版本不同的错误
-
Spark是什么:Spark是基于内存的迭代式计算引擎
1、基本概念
RDD:是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
Executor:执行器,是运行在工作节点(WorkerNode)的一个进程,负责运行Task
应用(Application):用户编写的Spark应用程序
任务( Task ):运行在Executor上的工作单元
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集
driver:驱动程序,简单来说就是整个application的管理程序。提交到集群的spark任务,在获取到driver运行的节点前,spark任务并不会出现在Web UI的RUNNING页,会临时挂在ACCEPTED页面,等待driver机器的获取。
cluster manager:资源管理器,常用的有standalone和yarn。
worker:计算节点,在yarn上一般指的是nodemanager节点,主要作用就是运行application代码。
2、架构设计
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点 (Driver)和每个工作节点上负责具体任务的执行进程(Executor)。资源管理器可以自带或Mesos或YARN 。
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
3、Spark运行流程
Spark运行的4个步骤:
- 当一个Spark应用被提交时,Driver创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源 ;
- 资源管理器为Executor分配资源,并启动Executor进程,Executor发送心跳到资源管理器上;
- SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度(DAGScheduler)进行解析,将DAG图分解成多个“阶段”,并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
- 任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源 。
4、弹性分布数据集(RDD)
RDD的两种操作(算子):
- 转换算子(Transformation)
- 动作算子(Action)
flatMap(func) 类似于 map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以 func 应该返回一个序列,而不是单一元素)
1.groupByKey和reduceByKey的区别
reduceByKey自带聚合逻辑, groupByKey不带;如果做数据聚合reduceByKey的效率更好, 因为可以先聚合后shuffle再最终聚合, 传输的IO小。
2. 哪两个Action算子的结果不经过Driver, 直接输出?
foreach 和 saveAsTextFile 直接由Executor执行后输出,不会将结果发送到Driver上去。
3. mapPartitions 和 foreachPartition 的区别?
mapPartitions 带有返回值;foreachPartition不带。
转换得到的RDD是惰性求值的。也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。行动操作是真正触发计算的地方。Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。
所以遇到错误时,不一定是行动的原因,可能是之前的某个地方的错误,要看错误原因是什么
5、Shuffle与依赖
shuffle描述着数据从map task输出到reduce task输入的这部分过程。shuffle是连接map和reduce的桥梁,包含了大量的磁盘IO、序列化、网络数据传输,可以认为大部分的spark任务作业的性能主要消耗在了这一阶段。shufle的主要工作简单来说就是跨节点将数据进行重新分配,类似reduceByKey、groupByKey等reduce算子都会触发shuffle,同时repartition也会触发shuffle。
Shuffle就是对数据进行重组
在Spark中,有两种依赖关系:
- 宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区;
- 窄依赖:一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。
常见的窄依赖有:map、filter、union、mapPartitions、mapValues
常见的宽依赖有groupByKey、partitionBy、reduceByKey
窄依赖和宽依赖,主要取决于是否包含Shuffle操作。(宽依赖还有一个别名:shuffle)
窄依赖可以实现“流水线”优化。宽依赖无法实现“流水线”优化。
6、持久化
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了:RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新的RDD生成,代表老RDD的消失。(这个特性可以最大化的利用资源,老旧RDD没用了,就从内存中清理,给后续的计算腾出空间)
在Spark中,RDD采用惰性求值的机制,每次遇到行动操作,都会从头开始执行计算。每次调用行动操作,都会触发一次从头开始的计算。这对于迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据。
可以使用persist()方法,对一个RDD标记为持久化,避免这种重复计算的开销。之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化 。持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。

1. Cache和Checkpoint区别
Cache是轻量化保存RDD数据, 可存储在内存和硬盘, 是分散存储, 设计上数据是不安全的(保留RDD 血缘关系)
CheckPoint是重量级保存RDD数据, 是集中存储, 只能存储在硬盘(HDFS)上, 设计上是安全的(不保留 RDD血缘关系)
2. Cache 和 CheckPoint的性能对比?
Cache性能更好, 因为是分散存储, 各个Executor并行执行, 效率高, 可以保存到内存中(占内存),更快
CheckPoint比较慢, 因为是集中存储, 涉及到网络IO, 但是存储到HDFS上更加安全(多副本)
7、Spark On Yarn两种模式总结
Client模式和Cluster模式最最本质的区别是:Driver程序运行在哪里。
- Client模式:学习测试时使用,生产不推荐(要用也可以,性能略低,稳定性略低)
1.Driver运行在Client上,和集群的通信成本高
2.spark任务的日志输出将直接打印在命令行或者输出到重定向的日志文件中
3.如果kill掉这个启动进程将直接导致spark任务运行结束 - Cluster模式:生产环境中使用该模式
1.Driver程序在YARN集群中,和集群的通信成本低
2.Driver输出结果不能在客户端显示
3.如果需要kill掉任务可以使用yarn指令或者spark web ui上进行手动kill
8、Spark内核调度
1.DAG之Job和Action
1个Action会产生1个DAG,如果在代码中有3个Action就产生3个DAG;一个Action产生的一个DAG,会在程序运行中产生一个JOB,所以:1个ACTION = 1个DAG= 1个JOB。
如果一个代码中,写了3个Action,那么这个代码运行起来产生3个JOB,每个JOB有自己的DAG;一个代码运行起来,在Saprk中称之为:Application。
层级关系:1个Application中,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JOB都是由一个Action产生的。
2.Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?
- Spark会产生DAG图
- DAG图会基于分区和宽窄依赖关系划分阶段
- 一个阶段的内部都是窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道。
- 这些内存迭代计算的管道,就是一个个具体的执行Task
- 一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了。
3. Spark为什么比MapReduce快
- Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务,很多复杂的任务,是需要写多个MapReduce进行串联,多个MR串联通过磁盘交互数据
- Saprk可以执行内存迭代,算子之间形成DAG,基于依赖划分阶段后,在阶段内形成内存迭代管道,但是MApReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的。
4.Saprk并行度
全局并行度配置的参数:spark.default.parallelism
5.Spark中数据倾斜
数据倾斜:在任务执行期间,RDD会被分为一系列的分区,每个分区都是整个数据集的子集。当spark调度并运行任务的时候,Spark会为每一个分区中的数据创建一个任务。大部分的任务处理的数据量差不多,但是有少部分的任务处理的数据量很大,因而Spark作业会看起来运行的十分的慢,从而产生数据倾斜(进行shuffle的时候)
数据倾斜只出现在shuffle过程中,可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等
解决办法:
- 过滤少量导致数据倾斜的key (如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话)
- 提高shuffle操作的并行度(增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据)
- 两阶段聚合 局部聚合+全局聚合(将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果)
- join时使用广播变量Broadcast将较小数据量广播至每个Executor(相当于reduce join转为map join)
Peak Execution memory应该是任务用的峰值内存
shuffle read是任务读取的数据量,如果有的任务这个值明显特别高,说明出现数据倾斜
shuffle write是任务写出的数据量,同样可以表示数据倾斜
9、DataFrame
1.DataFrame的组成
在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
在数据层面
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息
2.DataFrame之DSL
"""
1. agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
2. alias: 它是Column对象的API, 可以针对一个列 进行改名
3. withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
4. orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
5. first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.
# Row对象 就是一个数组, 你可以通过row['列名'] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等)
"""
1.show方法
功能:展示DataFrame中的数据, 默认展示20条
df.show(参数1, 参数2)
- 参数1: 默认是20, 控制展示多少条
- 参数2: 是否阶段列, 默认只输出20个字符的长度, 过长不显示, 要显示的话请填入truncate=True
2.printSchema方法
功能:打印输出df的schema信息
df.printSchema()
3.select
功能:选择DataFrame中的指定列(通过传入参数进行指定)

4. filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
5.groupBy 分组
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
df.groupBy()
传入参数和select一样,支持多种形式。GroupedData对象是一个特殊的DataFrame数据集,GroupedData对象也有很多API,比如count、min、max、avg、sum等等
3.DataFrame之SQL
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:

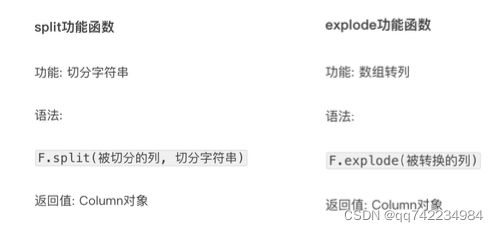
4.pyspark.sql.functions 包
里的功能函数, 返回值多数都是Column对象.
例:
5.SparkSQL Shuffle 分区数目
在SparkSQL中当Job中产生产生Shuffle时,默认的分区数(spark.sql.shuffle.partitions)为200,在实际项目中要合理的设置。可以设置在:
6.SparkSQL 数据清洗API
1.去重方法 dropDuplicates
功能:对DF的数据进行去重,如果重复数据有多条,取第一条

2.删除有缺失值的行方法 dropna
功能:如果数据中包含null,通过dropna来进行判断,符合条件就删除这一行数据

3.填充缺失值数据 fillna
功能:根据参数的规则,来进行null的替换

7.DataFrame数据写出
spark.read.format()和df.write.format() 是DataFrame读取和写出的统一化标准API
SparkSQL 统一API写出DataFrame数据

DataFrame可以从RDD转换、Pandas DF转换、读取文件、读取 JDBC等方法构建
10、SparkSQL
1.定义UDF函数
方式1语法:
udf对象 = sparksession.udf.register(参数1,参数2,参数3)
- 参数1:UDF名称,可用于SQL风格
- 参数2:被注册成UDF的方法名
- 参数3:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
方式2语法:
udf对象 = F.udf(参数1, 参数2)
- 参数1:被注册成UDF的方法名
- 参数2:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
其中F是:from pyspark.sql import functions as F 其中,被注册成UDF的方法名是指具体的计算方法,如: def add(x, y): x + y
add就是将要被注册成UDF的方法名
2.使用窗口函数
开窗函数
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
聚合函数和开窗函数
聚合函数是将多行变成一行, count,avg…
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中
开窗函数可以不使用group by,直接将所有信息显示出来
开窗函数分类
1.聚合开窗函数
聚合函数(列) OVER(选项),这里的选项可以是PARTITION BY子句、但不可以是ORDER BY子句。
2.排序开窗函数
排序函数(列) OVER(选项),这里的选项可以是ORDER BY子句,也可以是OVER(PARTITION BY子句ORDER BY子句),但不可以是PARTITION BY子句。
3.分区类型NTILE的窗口函数

11、PySpark参数
1.spark启动参数
spark启动任务一般通过下边这种方式:
/usr/bin/spark-submit
--master yarn \
--deploy-mode cluster \
--driver-memory ${driver_memory} \
--num-executors ${executor_num} \
--executor-cores ${executor_cores} \
--executor-memory ${executor_memory} \
--conf spark.dynamicAllocation.maxExecutors=${executor_max} \
--conf spark.driver.maxResultSize=${driver_memory} \
--conf spark.yarn.maxAppAttempts=1 \
--conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties \
--conf spark.ui.showConsoleProgress=true \
--conf spark.executor.memoryOverhead=1g \
--conf spark.yarn.nodemanager.localizer.cache.target-size-mb=4g \
--conf spark.yarn.nodemanager.localizer.cache.cleanup.interval-ms=300000 \
--files s3://learning/spark/log4j.properties \
--py-files ../config/*.py,../util/*.py \
--name "${WARN_SUB} => ${script} ${params}" \
${script} ${params}
2.参数设置
在spark中指定Python版本运行:conf spark.pyspark.python=/usr/bin/python2.7
1.2.1 --driver-memory:
一般设置1g-2g即可,如果程序中需要collect相对比较大的数据,这个参数可以适当增大
1.2.2 --num-executors | --executor-cores | --executor-memory
这三个参数是控制spark任务实际使用资源情况。其中
num-exectors*executor-memory
就是程序运行时需要的内存量(根据实际处理的数据量以及程序的复杂程度,需要针对不同的任务设置不同的参数)
一般情况下executor-cores可以设置1或者2就行了。设置的特别高,容易造成物理内存或者虚拟内存超限,最终导致任务失败。
需要注意的是,executor-memory设置最好控制在在4g以内(甚至2g),最好不要设置的特别大。(根据实际集群资源来配置)如果设置的特别大,可能会卡住整个集群,导致后续任务都无法启动。
num-executors是执行器数量,执行器越多,并行度越高,相对执行速度也会快。但是如果申请数量太多,也会造成资源的大量浪费。
一般数据量较小的任务,可以配置num-executors == 200,同时executor-memory==4g;这样申请资源大概在1TB左右。大型的任务可以根据实际情况调整num-executors即可。
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G ~ 8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所有Executor进程的内存总和),这个量是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3 ~ 1/2,避免你自己的Spark作业占用了队列所有的资源,导致别人的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他人的作业运行。
1.2.3 --conf spark.dynamicAllocation.maxExecutors
集群任务是由yarn来管理的,启动任务之后,yarn会倾向于给每个任务分配尽可能多的executor数量,num-executors的设置并不是最大的executors数量,最大executors数量通过这个参数来控制。也就是说,一个任务最大的资源占用量 = spark.dynamicAllocation.maxExecutors * executor-memory。
1.2.4 日志级别设置
--conf spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties
--conf spark.executor.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties
--files s3://learning/spark/log4j.properties
这三个配置是控制spark运行的日志输出级别的
1.2.5 spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
1.2.6 spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
3.spark调试
GC time太长,代表用于任务的内存太低,导致频繁GC,可以调小storage、shuffle的内存,增加任务内存
Peak Execution memory应该是任务用的峰值内存
shuffle read是任务读取的数据量,如果有的任务这个值明显特别高,说明出现数据倾斜
shuffle write是任务写出的数据量,同样可以表示数据倾斜
如果shuffle出现spill disk,说明shuffle内存不够,开始往硬盘写了。可以调大shuffle的内存,或者增大shuffle的partition数量。往硬盘写的数据如果不大,问题也不大。如果往硬盘溢写超过60G左右,节点可能就要崩了。
4.错误及解决方法
3.4G物理内存已经使用了3.4G(说明物理内存不够);16.9G虚拟内存已经使用了7.5G。
![]()
物理内存通常表示driver-memory;虚拟内存通常表示executor-memory?
Python运行spark时出现版本不同的错误
Exception: Python in worker has different version 3.9 than that in driver 3.7, PySpark cannot run with different minor versions. Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.
import os
# 此处指定自己的python路径
os.environ["PYSPARK_PYTHON"] = "/miniconda3/envs/py37/bin/python"
参考链接:调优 Spark3.3.0 官方文档