7. Linux的内存分配
在很多系统当中需要使用到一些先进的数据结构,他们的大小或者形状是随着程序的推进而演化,这个时候在程序开始之初我们并没有能力确认到底给他分配多少空间。所以这一章我们将讨论用于在堆和栈上分配内存的功能函数。
7.1 在堆上分配内存
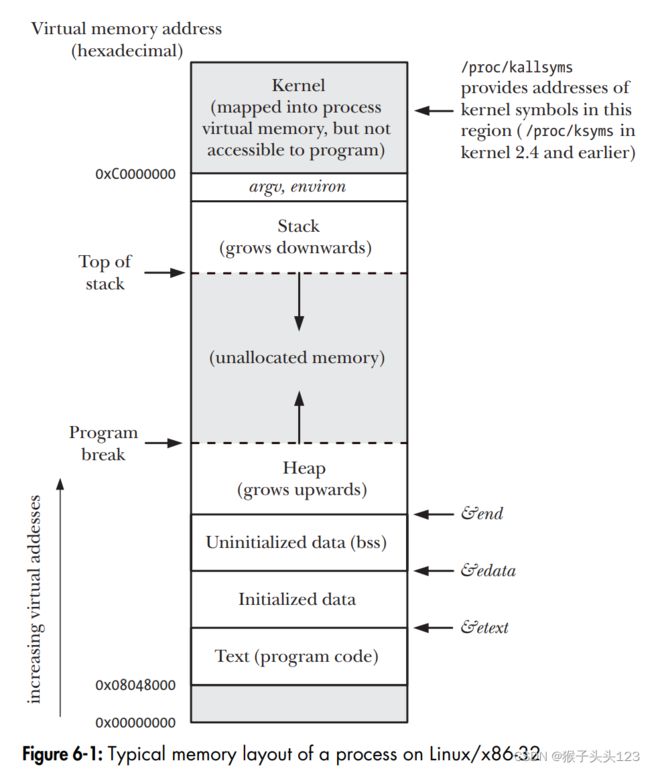
一个进程可以通过增加堆的尺寸来分配内存。堆是一个用来存放动态分配的变量的空间,它位于未初始化数据段(bss)之后,它的顶叫做program break,这个地方会根据内存的分配和释放而变化。一般来讲C语言堆内存的分配一般会使用malloc(),它是基于brk()和sbrk()所实现的。
7.1.1 调整Program Break: brk() 和sbrk()
调整heap区域的大小其实非常简单,也就是让内核调整Program Break的位置。在最刚开始什么都没有分配的时候,Program break就是紧挨着Unitialized data(bss)区域向上。当Program Break被增加了之后,程序就可以自由访问它之下在Heap范围内的任何被新分配的区域,但是这时候并还没有物理内存的页被分配。Kernel会在该进程第一次尝试进入该物理页的时候分配给新的物理内存页。
通常来说,UNIX系统提供了两种方法来改变program break的位置,在Linux中当然也是两种,他们叫做brk()和sbrk()。一般来讲我们在真正的应用层程序中不太可能直接使用brk()以及sbrk()(一般都直接使用malloc和free,因为他们已经将底层方法进行抽象),但是对于他们的理解却是可以帮助我们理解到底内存分配是如何工作的。
基本使用方法:
#include
int brk(void *end_data_segment);
//Returns 0 on success, or –1 on error
void *sbrk(intptr_t increment);
//Returns previous program break on success, or (void *) –1 on error brk()可以直接将program break设置在end_data_segment所指定的位置上。因为虚拟内存都是以页的形式分配,所以end_data_segment一定要被进到更大的整数页数上,比如现在是需要2.2页,则我们需要end_data_segment是3。
如果我们尝试将end_data_segment设置为program break初始值之下的话,则会触发segmentation fault。对于program break生长的限制取决于多个因素:进程资源对数据段的限制(RLIMIT_DATA在36.3中)还有就是内存映射的位置,共享内存段以及共享库等等。
对sbrk()的调用会通过调整往上的相对增加值来实现对program break的改变。成功之后,sbrk()会返回program break之前的地址。这里面可以这样子理解, 当program break增加之后,我们就会得到新被分配内存块的起始地址,并且我们知道它有多大。
sbrk(0)的调用会返回目前program break的位置,并不会改变任何东西。使用sbrk(0)可以帮助我们追踪heap目前的大小,可以用来监控内存分配package的行为。
7.1.2 在Heap上分配内存:malloc()和free()
一般来讲,C程序会使用malloc程序来分配或者取消分配heap上的内存空间。这些函数相比于brk()和sbrk()提供了众多的好处:
- 作为C语言的标准化的一部分
- 更易于在线程化的程序当中使用
- 提供一个简单的接口而允许内存在小的单元中被分配
- 允许我们任意取消对内存块的分配,并且这些信息会维持在一个free list上以方便未来可以对该空内存部分的循环使用。
malloc()会分配size大小的内容并返回起始位置的指针大小,并且被分配的内存并没有被初始化。
#include
void *malloc(size_t size); 因为malloc()返回的是void*类型,所以我们可以将该值赋予指向任何类型的指针。由malloc()返回的内存块总是要保持8位或者16位的整数倍的大小(俗称alignment)。
如果内存不能够被分配(可能因为我们到达了program break的限制),那么malloc()会返回NULL指针和errno来表示错误内容。尽管分配内存错误的可能性非常小,但我们仍然需要检查他是否出现错误。
free()函数用来释放被malloc()返回指针指向的程序块。
#include
void free(void *ptr); 一般来讲,free()并不会降低program break,但是它会将被释放的内存空间的地址放在一个free blocks的列表当中,之后可以被malloc()所循环利用。这是因为以下一些原因:
- 被释放的内存块一般来讲都位于现已利用的堆的中间,所以降低program break是不可能的。
- 它可以减少对sbrk()的调用,因为系统调用的开销相对比较大
- 在很多例子当中,降低program break并不会帮助分配大内存给程序。因为他们经常会被分配内存或者重复性的释放并分配内存,而不是释放他们所有并继续运行一段时间。
如果给free()一个NULL指针作为参数,那么这个调用就会什么都不做。随便丢给free()一个指针,比如对同一个指针地址调用两次free(),会产生一个不可预知的错误。
例程
下列程序可以用来解释free()对program break的效果-程序分配多个内存块并释放他们中的一些。
命令行参数的前两个表示想要分配的内存块的数量和大小,第三个参数表示当释放内存块的时候每隔几个内存块进行释放,这里还可以有第四第五个参数,表示被释放块的范围。
memalloc/free_and_sbrk.c (from "The Linux Programming Interface")
#define _BSD_SOURCE
#include "tlpi_hdr.h"
#define MAX_ALLOCS 1000000
int
main(int argc, char *argv[])
{
char *ptr[MAX_ALLOCS];
int freeStep, freeMin, freeMax, blockSize, numAllocs, j;
printf("\n");
if (argc < 3 || strcmp(argv[1], "--help") == 0)
usageErr("%s num-allocs block-size [step [min [max]]]\n", argv[0]);
numAllocs = getInt(argv[1], GN_GT_0, "num-allocs");
if (numAllocs > MAX_ALLOCS)
cmdLineErr("num-allocs > %d\n", MAX_ALLOCS);
blockSize = getInt(argv[2], GN_GT_0 | GN_ANY_BASE, "block-size");
freeStep = (argc > 3) ? getInt(argv[3], GN_GT_0, "step") : 1;
freeMin = (argc > 4) ? getInt(argv[4], GN_GT_0, "min") : 1;
freeMax = (argc > 5) ? getInt(argv[5], GN_GT_0, "max") : numAllocs;
if (freeMax > numAllocs)
cmdLineErr("free-max > num-allocs\n");
printf("Initial program break: %10p\n", sbrk(0));
printf("Allocating %d*%d bytes\n", numAllocs, blockSize);
for (j = 0; j < numAllocs; j++) {
ptr[j] = malloc(blockSize);
if (ptr[j] == NULL)
errExit("malloc");
}
printf("Program break is now: %10p\n", sbrk(0));
printf("Freeing blocks from %d to %d in steps of %d\n",
freeMin, freeMax, freeStep);
for (j = freeMin - 1; j < freeMax; j += freeStep)
free(ptr[j]);
printf("After free(), program break is: %10p\n", sbrk(0));
exit(EXIT_SUCCESS);
}从下面例子中出发:
当分配1000个1024字节大小的内存之后,再对奇数block进行释放,可以利用sbrk(0)看到program break保持不变,因为最上面的那个块并没有被释放
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out 1000 1024 2
Initial program break: 0x1862000
Allocating 1000*1024 bytes
Program break is now: 0x1949000
Freeing blocks from 1 to 1000 in steps of 2
After free(), program break is: 0x1949000
如果我们只是释放最上面的几个到甚至到100个程序块,也并不能让program break下降,直到测试了释放第800-1000个内存块,则可以看到在释放之后,program break从0xef5000下降到了0xed7000,下降了0x1e000这么多的字节,也就是下降了有120个程序块。至于说为什么只会下降120块,是因为free()的时候它会检查是否已经形成了一大块空区域(取决于LINUX本身)。如果达到标准的话,这时候就会下降program break。
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out 1000 1024 1 990 1000
Initial program break: 0x7d6000
Allocating 1000*1024 bytes
Program break is now: 0x8bd000
Freeing blocks from 990 to 1000 in steps of 1
After free(), program break is: 0x8bd000
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out 1000 1024 1 900 1000
Initial program break: 0x142000
Allocating 1000*1024 bytes
Program break is now: 0x229000
Freeing blocks from 900 to 1000 in steps of 1
After free(), program break is: 0x224000
pi@raspberrypi:~/sysprog/learn_tlpi/build $ ./out 1000 1024 1 800 1000
Initial program break: 0xe0e000
Allocating 1000*1024 bytes
Program break is now: 0xef5000
Freeing blocks from 800 to 1000 in steps of 1
After free(), program break is: 0xed7000
是否应该使用free()?
当进程终结的时候,所有的内存都将返还给系统,包括这其中被以malloc分配出去的内存。一个程序中如果分配并持续使用被malloc分配的内存并持续到程序结束的时候,我们一般都会忽略使用free(),等到程序结束的时候它自然会被自动收回。当我们已经分配了很多block出去的时候,不使用free()是会非常有用的,因为当大量调用free()的时候他们会消耗大量CPU资源,而且会增加代码复杂度。
尽管通过终结进程而自动释放内存对于很多程序来讲是可接受的,但还是有一些理由应该要使用free()来显式释放所有分配的内存:
- free()的调用可以使得程序更具可读性,并且在未来的维护上更容易
- 如果我们使用malloc调试库来寻找程序中的内存泄露,那么没有被显式释放的内存都会被当成是内存泄露而被报告。这会使得找到真正的内存泄露这件事情变得困难。
7.1.3 malloc()和free() 的实现
尽管比起brk()和sbrk(),malloc()和free()提供了分配内存的接口使得编程变得简单,但是在编程的过程中使用他们还是会带来很多错误。通过对malloc()和free()实现的内容可以帮助我们理解在调用他们的时候到底发生了什么,错误可能从什么地方来以及怎么避免错误。
malloc()的实现是比较简单直接地,它会首先检查之前被free的block list来找到一个可以容纳现在所需要的size的空间(但是具体怎么去找,这个取决于实现的方法)。如果空闲块大小正好满足size,那么它会直接返回,如果空闲块大于需求,那么首先会分割该块,并返回块初始地址,同时剩下的空闲块会被重新注册在free list上。
如果在free list上没有满足需求的空闲块,那么malloc()才会调用sbrk()来向上获得新的内存空间。为了减少sbrk()的调用次数,malloc()在每次调用sbrk()的时候不会只向上寻求只有需求大小的size,而是会寻求分配一个大很多的空间,然后会将多余的内存放进free list中管理。
再看free(),当free()将内存块放入free list的时候,实际它的参数只有该块的起始位置,那么它是如何知道释放多少内存呢?事实上malloc()在分配内存块的时候,它会额外多分配一些字节用来保存该内存块的大小信息。这个存储内存块大小的信息位于内存块的开头位置,但是malloc()所返回的指针指向的是内存块开始的实际位置。见下图:
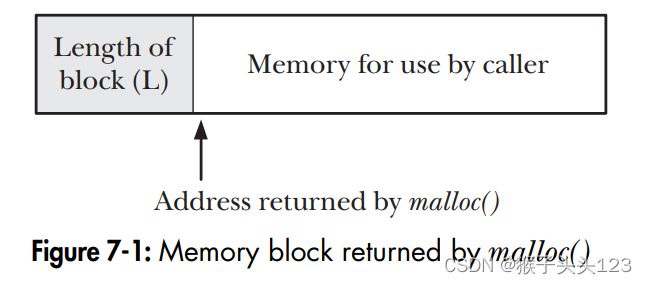
当内存块被放置在free list的时候,实际上free()使用的是该内存块的内存来作为free list的一部分。它实际是一个双向链表,在原内存块的存储位置放入指向前一个free内存块和后一个free内存块的地址。(读完这本书这一块,突然感觉Linux的内核的设计真的还挺有意思,可以说是真的非常精妙,其实读OS编程,对自己的编程水平的提高也会不是一点半点,因为这些真的都是考虑到系统最高运行效率所采取的编程方法)。

7.2图代表的是当一个内存块被释放之后,该内存块看上去变成了什么样子,下图7.3则是从宏观的角度再来看一下free list长什么样子:

C语言允许我们指向heap的任何位置,然后修改他们所指向的地方,这里包括了长度,前free block地址的位置,下一个free block的地址,这些信息都可以由malloc()和free()所修改以及维持。
在了解上面这些内容之后,我们就可以想见到可能程序会产生的错误。比如,如果因为一个错误指向的指针(我理解是错误指向了该内存块存放length的地址),我们突然增加了所被分配的内存块的长度值并且然后又释放了该内存块,那么free()就会错误记录一个该被释放的内存块的大小(因为length字节是唯一知道该内存块大小的信息)。然后当mallco()根据length重新分配内存块的时候,就会导致一个会有两个被分配的内存块使用共同的部分内存块,因为length被修改变大的内存块实际上最后的一些bytes一定会叠加在下一个内存块上。类似于这样的场景很多我们都会见到。
为了避免这类型的错误,我们应该遵守以下规则:
- 在我们分配了内存块之后,不应该触碰任何在该内存块之外的任何内存位置。很多时候我们是这样想,但是可能因为数字计算错误或者多循环了一位等等难以觉察的错误都会导致这样的问题。
- 另一种错误是对一个block free两次或多次。在使用Linux上的glibc的时候,我们会因此得到一个segmentation violation的错误(由SIGSEGV给出)。这样子可以帮助我们获得错误的警告。然而,一般来说,free同一个内存空间两次会导致不可预知错误。
- 我们不应该随便用一个指针值来调用free()释放内存,而且是应该给定一个因为malloc()调用而得到的指针值。
- 如果我们写了一个长时间运行的程序(比如shell或者network daemon进程),如果他们会为不同目的而重复地分配内存地话,那么我们需要确保我们会释放所有我们已经用完而不再用的内存。
malloc调试工具和库
上面所观察的的错误例子可以发现这一类错误是隐晦而且很难重现的。如果使用glibc里所提供的调试工具就可以轻松地找到一些类似这样的错误。
glibc调试工具提供了以下方法
- mtrace()和muntrace()函数允许程序开启或关闭内存分配追踪功能。这些函数可以与MALLOC_TRACE环境变量一起使用,它可以用来定义一个文件的文件名,并且该文件可以用来记录这些追踪信息。当mtrace()被调用的时候,它会检查该文件是否被定义并且是否能以可写的方式打开。如果上述信息都成立的话,那么所有对malloc()的调用都会被记录在这个文件上面。因为所记录的文件并不是一个可被人理解的内容,所以会有mtrace()来帮助分析和产生可读懂文件。对于一些安全的原因,mtrace()的调用一般会被所设置用户ID和所设置群组ID而忽略。
- mcheck()和mprobe()函数允许一个程序进行对被分配内存块的持续检查。比如说,当尝试在被分配内存块之外的空间写入一个数据的时候,他就会捕捉到这样子的错误。这样的函数功能提供了一些与之后所描述的malloc调试库所提供的功能有一定的重复。程序要使用这种检查功能的话,需要对mcheck 库进行链接-- cc -lmcheck。
- MALLOC_CHECK_环境变量提供了类似于mcheck()和mprobe()的功能。这两种方法的区别在于如果使用MALLOC_CHECK_的话则不需要修改和重编译(其实使用的话重编译还是需要的,只是不需要修改程序)程序。通过对MALLOC_CHECK_设置不同的值,我们就可以得到程序对内存分配错误的不同响应。
0 - 忽略错误 1 - 在strerr上打印出来诊断错误 2 - 调用abort()来结束程序。
但是MALLOC_CHECK_的设置并不能找出来所有的错误,它只能帮忙检测到常见错误。但是,这种手段的优点就是快速好用,运行开销小。但是通常来说,出于安全考虑,MALLOC_CHECK_也会被一定的userID和groupID忽略。
进一步的一些上述信息可以在glibc手册中找到。
一个malloc调试库提供了标准malloc包的相同的API,但是它会做更多的事情来抓住内存分配bug。为了能够使用这样的库,我们需要链接到malloc调试库上而不是malloc标准库中。因为调试库会做更多事情降低运行速度,增加内存开销,所以针对此我们只会在调试过程中使用该库。
监控malloc包
glibc手册表述了一系列可用于监控内存分配的非标准函数在malloc保中,其中包括:
- mallopt()用于修改控制malloc()中算法相关的多个参数。比如,一个用于确定在调用sbrk()缩减整个heap区域走之前确定free list末尾最小可释放空间的参数。另一个参数确定可被分配的内存块的上限值,当要被分配的块大于这个值的时候,需要使用mmap()来分配。
- mallinfo()返回一个struct数据,其中包含了多种关于被malloc()分配的内存的静态信息
很多UNIX执行都提供了mallopt()和mallinfo()供使用。然而,他们并不是可移植的程序,因为他们的很多实现并不相同。
7.1.4 其他在堆上分配内存的方法
calloc()和realloc()
calloc()可以给一个含有多个相同内容的array分配内存
#include
void *calloc(size_t numitems, size_t size); numitems表示要多少分配多少item,size表明他们的大小。在分配之后,它会返回指向块初始位置的指针(或者在未能成功分配的情况下返回NULL)。不同于malloc(),calloc()会将所分配的内存初始化为0。
这里是一个calloc()使用的例子:
struct { /* Some field definitions */ } myStruct;
struct myStruct *p;
p = calloc(1000, sizeof(struct myStruct));
if (p == NULL)
errExit("calloc");这里可以理解为,我们定义一个指向myStruct类型的结构体的指针变量 p,然后我们在堆中分配1000个myStruct类型大小的内存块,并且将第一个内存块的初始地址返回给p,也就是p在不发生错误的情况下指向一个有1000个单元myStruct类型大小的堆空间。
realloc()被用于改变(通常用于扩大)之前所被malloc()包中的一个函数分配的内存块的大小。用法如下:
#include
void *realloc(void *ptr, size_t size);
//Returns pointer to allocated memory on success, or NULL on error ptr指向要被改变大小的内存块,size表示想要最终实现的该内存块的大小。在成功之后,realloc()会返回一个指向该被改变大小的内存块的初始地址指针。这个地方可能会不同于之前的一些函数的调用。在错误情况下,realloc()返回NULL并且会让ptr的指向保持不变。
当realloc()增加了被分配内存块的大小,这时候他并不会初始化那些被额外分配的新的内存区域。
被calloc()和realloc()所分配的内存需要用free()来释放。
注意,事实上realloc(ptr, 0)即等同于free(ptr)。如果realloc(NULL),则等同于malloc(size)。
一般来说,当我们尝试使用realloc增加内存块空间的时候,它会自动从free list上找到下一个紧邻空闲内存块,如果它足够大的话就会将它们联合起来。如果这个块本身在heap的末尾,那么realloc()就会自动扩展heap。如果内存块在heap的中间,但是紧邻那他的空间没有足够的空间来扩大内存块,则它会将所有旧block中的内容移植到新的块中。总的来说一般建议减少对realloc的使用。
因为realloc()可能会重定位内存块的位置,我们必须使用realloc()所返回的指针来指向新的内存块地址。我们应该让ptr重新指向realloc()指向的新地址:
nptr = realloc(ptr, newsize);
if (nptr == NULL) {
/* Handle error */
} else { /* realloc() succeeded */
ptr = nptr;
}在这个例子当中,realloc()不会将新的地址替换写入ptr,是因为如果发生错误,ptr也会被改写成NULL,但是这样子会导致连原来的内存块的链接也会丢失。
因为realloc()可能会移动内存块,所以任何在成功调用realloc之后的ptr所指向的内存块可能已经不再有效。具体一些别的信息会在48.6章中解释。
分配对齐的内存(aligned memory):memalign()和posix_memalign()
memalign()和posix_memalign()函数被设计成从一个2的次方位开始对其的地址分配内存的功能,他对于很多应用来说非常有用。比如在13章中的13.7例。
#include
void *memalign(size_t boundary, size_t size);
//Returns pointer to allocated memory on success, or NULL on error memalign()函数分配size字节的内存,从boundary为单位对齐的地址开始分配内存,boundary一般是2的n次幂。返回值是所分配内存的起始地址。
memalign()并不是一个标准的所有UNIX都会实现的。大多数UNIX要使用memalign()则需要包含
SUSv3并没有规定memalign()作为标准函数,但是它定义了一个类似的即posix_memalign()。这个函数是一个最近的标准产物,目前被使用在UNIX的场景中并不多(现在2022年应该比较多了)。
#include
int posix_memalign(void **memptr, size_t alignment, size_t size);
//Returns 0 on success, or a positive error number on error posix_memalign()和memalign()还是有一定的区别:
- 被分配的地址会被返回在memptr中
- 内存会以2的幂次方倍数的sizeof(void*)对齐,一般sizeof(void*)会是4或者8自己在多数硬件结构上
虽然posix_memalign不会返回常见的-1作为错误值,但是它会返回错误码。
如果sizeof(void*)是4的话,那我们可以这样子用posix_memalign()来分配65,536自己的内存对其在一个4096字节的boundary上:
int s;
void *memptr;
s = posix_memalign(&memptr, 1024 * sizeof(void *), 65536);
if (s != 0)
/* Handle error */这里boundary就是1024*sizeof(void *),我们一共分配65535字节的内容。
同样,最后当要释放内存的时候,使用memalign()或者是posix_memalign()即可。
7.2 在栈上分配内存:alloca()
就像在malloc包中的函数一样,alloca()分配会动态分配内存。然而,不同于在heap上获取内存的方式,alloca()会从stack上通过增加stack frame大小的方式来获得内存资源。这是可能的因为调用函数本身就是在stack的最上面发生。因此只要stack顶还有空间扩展的时候,我们就可以通过一个简单的分配来完成这样的事情:
#include
void *alloca(size_t size); alloca()会返回所对应的初始地址。
我们不需要通过调用free()来释放alloca()所分配的内存。同样我们也不可能通过realloc()类似的方式来达到扩展内存块的目的。
虽然alloca()不是SUSv3的一部分,但是大多数UNIX都支持它的实现以及他是可移植的。
如果因为alloca()的使用而造成栈溢出,那么它的的行为也是不可控的。特别是在错误情况下我们不能指望通过NULL返回而得知错误的存在。
另外我们也不可以通过函数内部参数形式对他进行调用。例如func(x, alloca(size), z)。
但是我们可以这样做:
void *y;
y = alloca(size);
func(x, y, z);对alloca()的使用相比malloc()所能带来的好处并不多。好处大概就是compiler可以把它当作内联函数对待,另外alloca并不需要维持一个free list。另外就是alloca()所分配的区域会被stack自动回收,所以编程会比较容易。
alloca()常用的地方例如在使用longjmp()或者siglongjmp()的时候来做一些处理。具体的可以查看6.8和21.2.1章。