map、sync.map、concurrent-map适用场景与源码解析
最近一直加班,无论工作日还是周末,虽然每天很忙但总感觉空空的,很少有时间停下来思考与总结。项目中各种甩锅,最后最苦逼的还是落到了研发的头上,文档编写、环境部署、问题排查虐得一遍又一遍。事情杂乱,研发效率超级低,不知道何是是个头呀
背景
在go中,map是最常用的集合之一。
其底层key存储采用的是hash算法,在数据检索时提供了强大的性能,深受各大开发者喜爱。
但在并发方面,map则存在较为严重的问题。一不留神,就会导致整个程序出错退出。
为了解决map并发操作的问题,诞生出了sync.map及第三方的concurrent-map等集合。
那么哪个集合更符合我们的需求,就需要都来了解一下。
map线程安全问题
先来看一下原生map在并发操作上带来的问题,随便写个测试代码验证一下:
var myMap = make(map[int]int, 0)
for i := 0; i < 10; i++ {
go func() {
for x := 0; x < 1000; x++ {
time.Sleep(time.Millisecond)
myMap[x] = x + 1
fmt.Printf("x=%d m=%d\n", x, myMap[x])
}
}()
}
time.Sleep(time.Second * 5)
可能出现如下错误:
x=12 m=13
fatal error: concurrent map writes
x=12 m=13
goroutine 27 [running]:
fatal error: concurrent map writes
如上面所示,使用map在并发场景的情况下进行并发读写,程序可能抛出以上错误则会导致程序退出
给map加互斥锁(Mutex)
为了解决以上问题,在代码量改动比较上的情况下则是加上lock锁;
代码改造为:
var myMap = make(map[int]int, 0)
var lock sync.Mutex
for i := 0; i < 10; i++ {
go func() {
lock.Lock()
for x := 0; x < 1000; x++ {
time.Sleep(time.Millisecond)
myMap[x] = x + 1
fmt.Printf("x=%d m=%d\n", x, myMap[x])
}
lock.Unlock()
}()
}
time.Sleep(time.Second * 5)
所有协程都使用同一把lock锁,进行数据读写时先获取锁再执行对map的读写操作。
这种方式对于并发较小的场景一般也能进行处理,对于并发大时则可能会出现耗时过久才能获取锁。
给map加读写锁(RWMutex)
针对上面给map加一把大锁,如果带来了性能不佳的情况,且应用场景为比较明确的读多写少场景的场景,可以进一步优化为读写锁(RWMutex)分离实现,编码上来看也还过得去。
sync.map
下面深入了解一下sync.map是如何解决的golang中map并发安全问题的。
将原代码进行修改:
var myMap = sync.Map{}
for i := 0; i < 10; i++ {
go func() {
for x := 0; x < 1000; x++ {
time.Sleep(time.Millisecond)
myMap.Store(x, x+1)
value, _ := myMap.Load(x)
fmt.Printf("x=%d m=%d\n", x, value)
}
}()
}
time.Sleep(time.Second * 5)
再看来一下sync.map的源码,代码行数总体不到600行,与go的代码的简短精悍比较符合。
sync.map结构
在了解sync.map的源码前,非常有必要了解一下sync.map的数据存储结构。
type Map struct {
mu Mutex
read atomic.Pointer[readOnly]
dirty map[any]*entry
misses int
}
type readOnly struct {
m map[any]*entry
amended bool // true if the dirty map contains some key not in m.
}
type entry struct {
p atomic.Pointer[any]
}
如下图:

Store流程
sync.map中每个kv对的新增使用store方法实现。源码如下:
// Store sets the value for a key.
func (m *Map) Store(key, value any) {
_, _ = m.Swap(key, value)
}
// Swap swaps the value for a key and returns the previous value if any.
// The loaded result reports whether the key was present.
func (m *Map) Swap(key, value any) (previous any, loaded bool) {
read := m.loadReadOnly()
if e, ok := read.m[key]; ok {
if v, ok := e.trySwap(&value); ok {
if v == nil {
return nil, false
}
return *v, true
}
}
m.mu.Lock()
read = m.loadReadOnly()
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {
// The entry was previously expunged, which implies that there is a
// non-nil dirty map and this entry is not in it.
m.dirty[key] = e
}
if v := e.swapLocked(&value); v != nil {
loaded = true
previous = *v
}
} else if e, ok := m.dirty[key]; ok {
if v := e.swapLocked(&value); v != nil {
loaded = true
previous = *v
}
} else {
if !read.amended {
// We're adding the first new key to the dirty map.
// Make sure it is allocated and mark the read-only map as incomplete.
m.dirtyLocked()
m.read.Store(&readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
return previous, loaded
}
流程图如下:

在store中主要分为2个分支:
- 更新的key在read中存在,使用自旋锁(CAS)的方式对value进行更新
- 将更新的kv对在dirty中进行更新,并确保dirty初始化完毕且amended标识为true
Load流程
sync.map中在kv对被存储后,就可以使用Load方法查询了。
其源码如下:
// Load returns the value stored in the map for a key, or nil if no
// value is present.
// The ok result indicates whether value was found in the map.
func (m *Map) Load(key any) (value any, ok bool) {
read := m.loadReadOnly()
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
// Avoid reporting a spurious miss if m.dirty got promoted while we were
// blocked on m.mu. (If further loads of the same key will not miss, it's
// not worth copying the dirty map for this key.)
read = m.loadReadOnly()
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
// Regardless of whether the entry was present, record a miss: this key
// will take the slow path until the dirty map is promoted to the read
// map.
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
流程图如下:
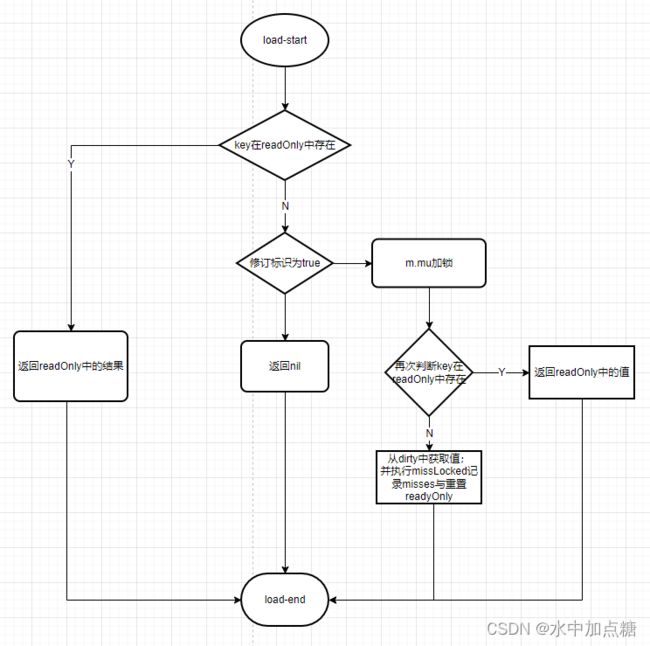
在了解了Store的流程后再来看Load就比较简单啦。
主要流程为:
- 从readOnly中查询key的值
- readOnly中无法找到,且有新的值被存到map中(amended为true)
- 从dirty中查找
- 将misses自增
- misses大于等于dirty的数量时,将dirty设为readOnly;并重置dirty与misses
需要重点关注的关于dirtry升级为readOnly的代码如下:
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(&readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
Delete流程
在看了Store和Load的流程后,对sync.map的主要流程就算是基本掌握了。最后再来看一下Delete的流程:
// Delete deletes the value for a key.
func (m *Map) Delete(key any) {
m.LoadAndDelete(key)
}
// LoadAndDelete deletes the value for a key, returning the previous value if any.
// The loaded result reports whether the key was present.
func (m *Map) LoadAndDelete(key any) (value any, loaded bool) {
read := m.loadReadOnly()
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read = m.loadReadOnly()
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
delete(m.dirty, key)
// Regardless of whether the entry was present, record a miss: this key
// will take the slow path until the dirty map is promoted to the read
// map.
m.missLocked()
}
m.mu.Unlock()
}
if ok {
return e.delete()
}
return nil, false
}
Delete的流程与前面新增和查询流程类似:
- 先从readOnly中查询,存在对应key值调用
e.delete()进行删除 - readOnly中不存在并被修改过(amended为true),则进行加锁从dirty中查找,并调用delete进行删除
这里需要留意的是,从readOnly中删除kv对也是使用的自旋(CAS)的方式进行删除的,源码如下:
func (e *entry) delete() (value any, ok bool) {
for {
p := e.p.Load()
if p == nil || p == expunged {
return nil, false
}
if e.p.CompareAndSwap(p, nil) {
return *p, true
}
}
}
concurrent-map
与JAVA语言类似地,第三方的concurrent-map组件也提供了一种实现用于解决map的并发访问问题。

其项目地址如下:
https://github.com/orcaman/concurrent-map
其实现方式为采用的与JAVA中的ConcurrentHashMap思路实现的,即通过多个锁提高减少对大锁竞争。
与sync.map相比,sync.map中所有的key使用同一个Mutex互斥锁,而在concurrent-map中,则存大多个Mutex互斥锁,多个key共享同一个Mutex互斥锁。
总结
在go中进行KV存储时,常用map、sync.map、concurrent-map这3种map实现。
项目中选型时具体应该使用哪个需要分析具体的业务场景,可参考sync.map中的这段话:
The Map type is optimized for two common use cases: (1) when the entry for a given key is only ever written once but read many times, as in caches that only grow, or (2) when multiple goroutines read, write, and overwrite entries for disjoint sets of keys. In these two cases, use of a Map may significantly reduce lock contention compared to a Go map paired with a separate Mutex or RWMutex.
最后,再简单总结一下:
项目中选型时,应优先考虑使用原生map进行KV存储;
多个协程的并发读写场景,应优先考虑在map中加上互斥锁(Mutex)或读写锁(RWMutex)实现,这样对map的编码方式改动也最小。
并发场景为读多写少的场景,则可考虑sync.map;如并发场景为读多写多的场景,又追求性能则也可考虑下第三方的concurrent-map。