HashMap几种遍历方式
学习目标:
HashMap遍历方法
学习内容:
Java8之前:
- EntrySet遍历
代码部分:
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
for (Map.Entry<String, String> entry : map.entrySet()) {
if ("Java".equals(entry.getKey())) {
map.remove(entry.getKey());
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
运行结果:
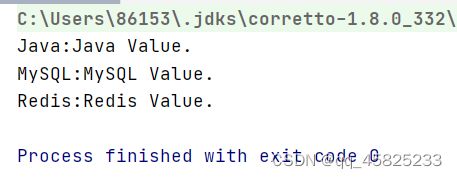
2. KeySet遍历 性能不好,需要遍历两遍集合
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
for (String key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
运行结果:
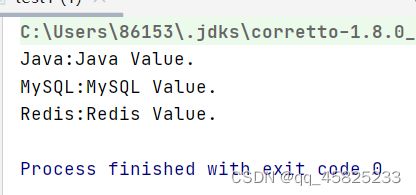
- EntrySet迭代器遍历
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
if ("Java".equals(entry.getKey())) {
iterator.remove();
continue;
}
System.out.println(entry.getKey() + ":" + entry.getValue());
}
KeySet迭代器遍历
HashMap<String, String> map = new HashMap() {{
put("Java", " Java Value.");
put("MySQL", " MySQL Value.");
put("Redis", " Redis Value.");
}};
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String key = iterator.next();
System.out.println(key + ":" + map.get(key));
}
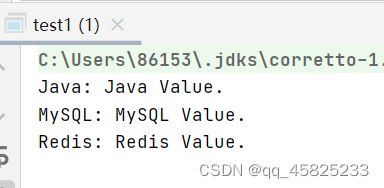
``
注意:如果不使用迭代器,在遍历代码时动态删除元素,非迭代器遍历会报错,如下图所示:
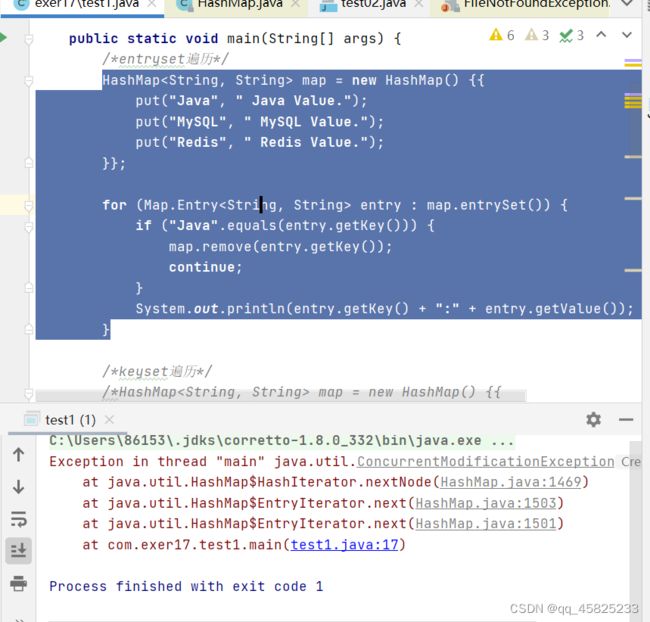
ConcurrentModificationException是Java集合的一个快速失败(fail-fast)机制,防止多个线程同时修改同一个集合的元素。
HashMap底层就是使用的迭代器,对象在初始化的时候会将当前的modCount赋值给自身属性expectedModCount,由于循环遍历时remove会改变modCount的值但是不会改变expectedModCount的值,所以就会发生异常!
使用iterator迭代器进行remove时就不会有这种错误,原因是removeNode之后会将expectedModCount重新赋值就不会发生这种问题!
1.可以使用concurrentHashMap,运行在遍历时进行修改,删除
2.使用iterator迭代器循环遍历删除元素也是可取的
使用Lambda表达式遍历
HashMap<String, String> map = new HashMap() {{
put("Java", "Java Value.");
put("MySQL", "MySQL Value.");
put("Redis", "Redis Value.");
}};
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
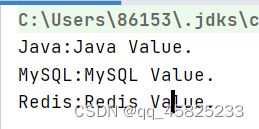
Stream单线程遍历
先得到map集合的EntrySet,然后再执行forEach循环
HashMap<String, String> map = new HashMap() {{
put("Java", "Java Value.");
put("MySQL", "MySQL Value.");
put("Redis", "Redis Value.");
}};
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});

Stream多线程遍历:多执行了一个parallel并发执行方法,此方法会根据当前的硬件配置生成对应的线程数,然后再进行遍历操作
HashMap<String, String> map = new HashMap() {{
put("Java", "Java Value.");
put("MySQL", "MySQL Value.");
put("Redis", "Redis Value.");
}};
map.entrySet().stream().parallel().forEach((entry) -> {
System.out.println(entry.getKey() + ":" +entry.getValue());
});
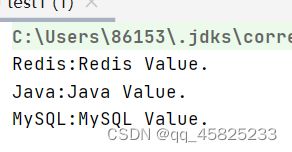
程序是并发执行的,所以没有办法保证元素的执行顺序和打印顺序
如果是Java8之后的开发环境,推荐使用Stream的遍历方式,因为它足够简洁
如果在遍历的过程中需要动态的删除元素,推荐使用迭代器的遍历方式
如果在遍历的时候在意程序的执行效率,使用Stream多线程遍历方式